Современный мир данных стремительно развивается, и вопросы масштабируемой, надёжной и экономичной потоковой обработки становятся всё более актуальными для бизнеса и разработчиков. В этом контексте Ursa представляет собой новаторское решение, предлагающее гармоничное сочетание эффективной работы с потоками данных и возможностей lakehouse-хранилищ. Этот движок обещает революционные изменения в использовании Apache Kafka, избавляя пользователей от ряда ограничений традиционных систем и открывая новые перспективы для построения сложных дата-пайплайнов. Ursa — это платформа, разработанная как lakehouse-native, то есть глубоко интегрированная с хранилищами данных, которые используют открытые форматы таблиц, такие как Apache Iceberg и Delta Lake. Благодаря этому подходу обеспечивается прямое и безкопийное стриминг-запись данных в объектное хранилище, что сокращает издержки на инфраструктуру и минимизирует задержки в обработке данных.
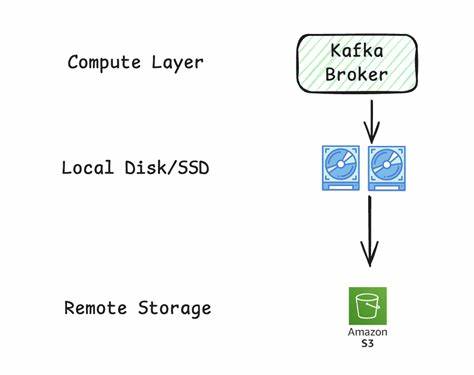
Важно, что для конечных пользователей и разработчиков Ursa полностью совместима с Kafka, не требуя переписывания кода или изменения привычных потоков передачи данных. Ключевым преимуществом Ursa выступает лидерless архитектура. Традиционные системы потоковой передачи, в частности Apache Kafka, опираются на наличие лидера в кворуме брокеров для координации и репликации данных. Это существоcтвенно усложняет масштабирование, увеличивает задержки и ведёт к дополнительным расходам на сетевой трафик внутри облачных зон доступности (AZ). Ursa же устраняет необходимость в лидерах и меж-зональном трафике, обеспечивая устойчивую и отказоустойчивую работу без избыточных коммуникаций между брокерами.
Такая архитектура снижает общие затраты и повышает надёжность. Важным моментом является разделение хранения и вычислений. Ursa использует объектные хранилища, которые сегодня доступны в облачных платформах с высокой степенью отказоустойчивости и масштабируемости. Это позволяет масштабировать вычислительные мощности независимо от объема хранимых данных, избегая излишних затрат на предварительное выделение ресурсов (оверпровижинг). Пользователи платят только за реально используемые вычислительные ресурсы и поток данных.
Экономическая эффективность – ещё один важный критерий, по которому Ursa превосходит классические решения. Согласно обзорам и измерениям производительности, запуск тяжелых Kafka-ворклоадов с пропускной способностью до 5 гигабайт в секунду возможен за стоимость около 50 долларов в час, что примерно в 10 раз дешевле по сравнению с традиционными системами, такими как Redpanda или стандартный Kafka-кластер. Это открывает возможности для компаний любого масштаба оптимизировать свои бюджеты на потоковую обработку и направить сэкономленные средства на развитие аналитики и искусственного интеллекта. Ursa предлагает поддержку разных протоколов передачи данных, не ограничиваясь Kafka. Среда совместима с Apache Pulsar, MQTT и другими распространёнными стандартами, что облегчает интеграцию в уже существующую инфраструктуру заказчика и расширяет сферы применения.
Продюсеры и консюмеры данных могут продолжать работу в привычном режиме без необходимости внесения изменений в код, что значительно упрощает процесс адаптации и внедрения нового движка. Одним из самых примечательных аспектов Ursa является возможность работы с lakehouse-форматами напрямую, что позволяет минимизировать использование промежуточных систем, таких как ETL-инструменты и коннекторы, которые часто усложняют архитектуру и увеличивают задержки. Благодаря zero-copy стримингу данные мгновенно становятся доступными для аналитики и машинного обучения без лишних нагрузок, позволяя свести к минимуму временные промежутки между сбором событий и их использованием для бизнес-решений. Ursa получила признание широкого сообщества и экспертов — в 2025 году платформа была отмечена престижной премией VLDB (Very Large Data Bases) за лучшую отраслевую научную работу. Это подтверждает лидерство Ursa в сегменте lakehouse-native технологий и её инновационную роль в эволюции потоковых систем.
Статьи и отчёты подробно описывают архитектурные особенности и преимущества, которые позволяют Ursa достигать высоких показателей надёжности, масштабируемости и эффективности. Интерес для бизнеса и дата-инженеров обусловлен не только технологическими инновациями, но и удобством эксплуатации. Ursa снимает с пользователей необходимость в управлении дисковыми подсистемами, межзональным трафиком и настройкой лидеров кворума. Кроме того, платформа автоматически масштабируется в зависимости от текущей нагрузки, обеспечивая оптимальный уровень производительности и экономии. Это освобождает команды от рутинного мониторинга и администрирования, позволяя сосредоточиться на анализе данных и развитии продуктов.
Совместимость с облачными платформами AWS, Azure и Google Cloud делает Ursa универсальным инструментом для множества применений. Публичные предпросмотры и примеры успешного внедрения подтверждают её готовность для использования в крупных проектах с требованиями к безопасности, отказоустойчивости и высокой производительности. При этом модель оплаты по факту использования обеспечивает гибкость и доступность решения для широкого круга организаций. Особое внимание уделено снижению латентности и упрощению архитектурных паттернов в системе. За счёт отсутствия необходимости в дополнительных коннекторах, копировании или перегоне данных Ursa уменьшает время реакции между появлением события и его обработкой в системе аналитики или AI-моделях.
Это особенно важно для сценариев, где скорость принятия решения критична, например, в финансовых системах, интернет-рекламе и IoT. Клиенты Ursa отмечают, что переход на эту платформу открывает новые горизонты для построения более гибкой и эффективной инфраструктуры данных. Возможность объединить потоки и lakehouse-форматы в одном инструменте снижает сложность системы, сокращает возможные точки отказа и делает архитектуру более прозрачной и предсказуемой. Это позволяет бизнесу быстрее извлекать ценность из данных, ускорять процессы разработки моделей и получать конкурентные преимущества. Еще одним достоинством является открытость и прозрачность экосистемы.
Ursa основана на духе открытого программного обеспечения, поддерживает стандартные форматы и интегрируется с популярными инструментами в области больших данных и машинного обучения. Это даёт гарантию, что решения на её базе не привязаны к конкретному вендору и легко адаптируются под изменяющиеся требования бизнеса. Подытоживая, Ursa представляет собой компактное и гармоничное решение, которое сочетает достоинства объектного хранения, lakehouse-форматов и безлидерной распределённой архитектуры, сохраняя полную совместимость с Apache Kafka и другими распространёнными протоколами. Такая платформа способна значительно снизить затраты на инфраструктуру потоковых данных, упростить сопровождение и обеспечить высокую производительность, что делает её привлекательной альтернативой для компаний, стремящихся модернизировать свои архитектуры данных и подготовиться к вызовам будущего. При выборе Ursa организации получают не просто технологическую платформу, а возможность создавать устойчивые и масштабируемые дата-пайплайны, которые легко интегрируются с современными lakehouse-экосистемами и обеспечивают быстрый доступ к качественным данным для аналитики и ИИ.
В условиях постоянно растущих объемов данных и необходимости оперативного принятия решений такая инновация открывает новые перспективы и задаёт вектор развития всей индустрии потоковой обработки.