В современном мире искусственного интеллекта и больших языковых моделей (LLM) наблюдается стремительное развитие, которое открывает новые горизонты для исследователей и разработчиков. Одной из заметных и широко обсуждаемых моделей 2025 года является Qwen3 - открытая и мощная архитектура, обеспечивающая высокую производительность и удобство использования для самых разных проектов. Освоение принципов работы Qwen3 и понимание его архитектуры позволяет не только получить глубокие знания о современных технологиях обработки естественного языка, но и открыть двери для создания инновационных решений на ее основе. Qwen3 интересна многим специалистам благодаря своей доступной лицензии Apache 2.0, что делает ее привлекательным выбором для коммерческого и исследовательского использования без ограничений, которыми зачастую сопровождаются другие открытые модели.
Кроме того, Qwen3 демонстрирует впечатляющие показатели эффективности: на момент начала осмысления модели, версия Qwen3 235B-Instruct занимает восьмое место в рейтинге LMArena, что сопоставимо с результатами проприетарной модели Claude Opus 4. Более крупные модели, такие как DeepSeek 3.1 и Kimi K2, превосходят ее только благодаря значительно большему количеству параметров. Недавно в линейке Qwen3 появился 1 триллионный параметр "max" вариант, который по ряду ключевых метрик обошел всех конкурентов, хотя пока он закрыт для публичного использования. Архитектура Qwen3 отличается гибкостью и масштабируемостью.
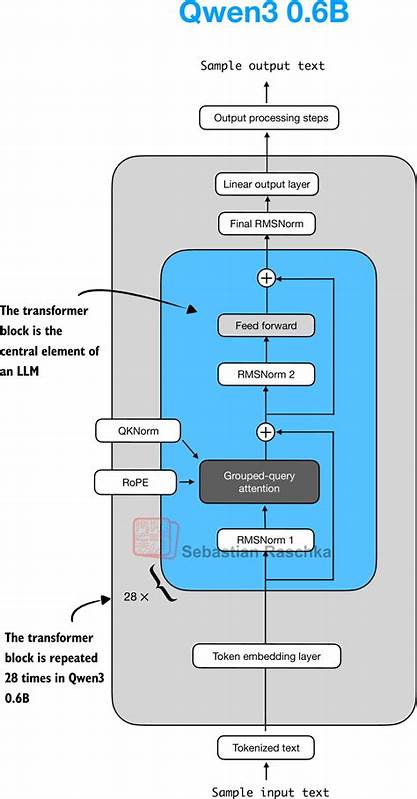
Модель выпускается в различных конфигурациях - от сравнительно легких 0,6 миллиарда параметров до огромных 480-миллиардных Mixture-of-Experts (MoE) комплектаций. Такой подход позволяет подобрать наиболее оптимальное решение в зависимости от поставленных задач и доступных вычислительных ресурсов, начиная с настольных компьютеров и заканчивая мощными серверными кластерами. Важным преимуществом Qwen3 является её продуманная внутренняя структура, которая тщательно проработана для оптимального сочетания скорости обучения, качества генерации текста и экономии памяти. Ключевые механизмы включают в себя современные методы трансформеров, гибко варьируемые слои экспертов и технологии адаптивного внимания, что обеспечивает максимально эффективную работу с большими объемами данных и сложными текстовыми запросами. Для тех, кто хочет копнуть глубже и узнать, как функционирует Qwen3 на уровне кода, есть прекрасная возможность познакомиться с реализацией модели на языке Python с использованием фреймворка PyTorch.
Детальный разбор, выполненный в исследовательской публикации SEBASTIAN RASCHKA от сентября 2025 года, предоставляет самостоятельное пошаговое руководство по созданию основных блоков модели с нуля. Такие практические знания помогают не просто понимать архитектуру теоретически, но и применять эти навыки для разработки собственных модификаций и экспериментов. Реализация Qwen3 "с нуля" представляет собой не только вызов, но и возможность познакомиться с современными методами оптимизации, обработки последовательностей, распределенного обучения и управления памятью. Особое внимание уделяется тому, как строятся слои внимания и механизмы выбора экспертов, что обеспечивает модели высокую точность при минимальных вычислительных издержках. Практическое освоение Qwen3 особенно полезно для тех, кто хочет развивать собственные исследовательские или продуктовые проекты на базе LLM, а также для инженеров, стремящихся понять устройство конкурентных моделей, популярных в 2025 году.
Эксперименты с реализацией помогают выявить узкие места, оптимизировать нагрузку и настроить модель под специфические задачи, будь то генерация текста, анализ данных, машинный перевод или создание интеллектуальных ассистентов. Поскольку Qwen3 выпускается в открытом доступе и одним из первых моделей в 2025 году предлагает такой широкий диапазон вариантов по числу параметров и архитектурных решений, она быстро стала своего рода "стандартом" для тех, кто ищет баланс между производительностью и гибкостью. Это заставляет обратить внимание не только на внутренние технические детали, но и на вопросы лицензирования, совместимости и практического разворачивания в различных IT-инфраструктурах. Кроме того, Qwen3 активно поддерживается сообществом, что отражается в появлении множества дополнительных инструментов, библиотек и документации для упрощения интеграции и обучения. Это особенно полезно в эпоху, когда число новых моделей растет лавинообразно, а качественные руководства помогают специалистам за короткое время войти в курс дела и приступить к работе с самой передовой технологией.
Если подытожить все, что представляет собой Qwen3, перед нами открывается модель, которая гармонично сочетает в себе исследовательские инновации и практическую применимость. Она не только демонстрирует высокий уровень точности и скорости, но и предоставляет возможность расширения и адаптации, что крайне важно для быстро меняющихся задач в области искусственного интеллекта. Сейчас, когда модели с триллионными параметрами начинают занимать своё место в индустрии, а требования к качеству генерации текста становятся все строже, понимание того, как устроена Qwen3 и умение реализовывать её алгоритмы вручную, открывает широкие перспективы для инженеров и исследователей. Это знание становится ключом к созданию более интеллектуальных, быстрых и адаптивных решений, которые определят будущее коммуникации между человеком и машиной. Таким образом, изучение и внедрение Qwen3 - это не просто освоение очередной модели.
Это глубокое погружение в самую суть современных технологий обработки естественного языка, стремление понять и использовать лучшие наработки индустрии, а также подготовка к вызовам будущего в мире искусственного интеллекта. В конечном итоге, такие компетенции становятся неотъемлемой частью профиля эксперта, способного создавать инновационные решения на стыке науки и техники. .