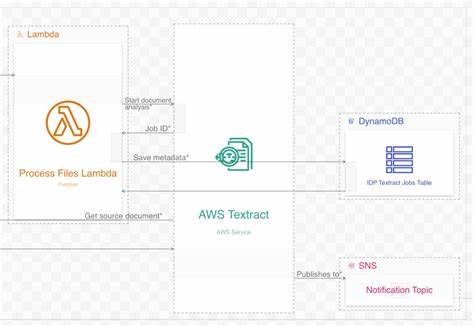
Архитектура облачных приложений часто становится сложным многослойным конструктом, требующим аккуратного документирования и визуального представления. В частности, решения Amazon Web Services (AWS) предоставляют широчайший набор инструментов для решения разнообразных задач, среди которых выделяется система AI обработки документов. Несмотря на то, что AWS предлагает обширную библиотеку архитектурных диаграмм для своих решений, в них нередко встречаются ошибки, упрощения и несоответствия реальному функционированию систем. Особенно ярко это проявляется на примере Intelligent Document Processing - серверлес-приложения, использующего искусственный интеллект для классификации и извлечения информации из документов, таких как заявки на кредит. Внешне такие диаграммы выглядят вполне приемлемо - элементы и последовательность шагов обозначены достаточно интуитивно.
Однако при более тщательном анализе на поверхности всплывают серьёзные несоответствия. Например, стрелки между компонентами зачастую не подписаны, что противоречит основным правилам построения эффективных диаграмм. Кроме того, схема отображает процесс как конвейерную линию, где данные последовательно проходят от одного ресурса к другому, тогда как реальное управление процессом гораздо более сложное и включает обратные связи и асинхронные вызовы. Эта упрощённая картина вводит в заблуждение, особенно начинающих разработчиков, которые могут впоследствии неправильно понять архитектуру и логику приложения. Проблема усугубляется тем, что в исходной диаграмме одинаково выделены по размеру все ресурсы, что не отражает их истинное значение и нагрузку в системе.
Некоторые ресурсы продублированы визуально, создавая иллюзию независимых компонентов, хотя на самом деле они представляют собой одну сущность. Все эти ошибки снижают ценность диаграммы как обучающего и справочного материала. Для решения данных вопросов необходим подход, ориентированный на точность и глубину отображения взаимодействий между компонентами. Традиционная блок-схема с номерованными стрелками не способна полно и понятно показать сложный обмен сообщениями и асинхронные вызовы между функциями Lambda, очередями SQS, хранилищами S3 и другими сервисами. Лучшим решением стало использование диаграмм последовательностей (sequence diagrams), которые позволяют детально отобразить пошаговый протокол сообщений между всеми участниками системы.
В таких диаграммах поток управления и передачи данных читается сверху вниз, что значительно облегчает понимание процесса. При этом каждый ресурс представляется в виде вертикальной линии протекания времени, что позволяет показать многоступенчатые сценарии и циклы взаимодействий. В случае AI обработки документов было выделено четыре ключевых рабочих процесса, каждый из которых сфокусирован вокруг соответствующей функции Lambda. Это позволило сначала создать общую карту архитектуры, а затем с помощью инструментов, например Ilograph, обеспечить возможность детального зумирования на каждую подсистему, изучая их поведение шаг за шагом. Первый рабочий процесс отвечает за извлечение текста из документов.
Здесь система довольно близко соответствует исходной диаграмме: загрузка документа в хранилище S3 инициирует вызов Lambda, которая запускает сервис AWS Textract для распознавания текста. Отличием стала уточнённая последовательность получения данных Textract из исходного бакета, а также сохранение временной метаинформации в DynamoDB - ключевой момент, который отсутствовал в оригинальной схеме, но критичен для дальнейших этапов обработки. Второй процесс - классификация документа - ранее был представлен крайне упрощённо и допускал несколько неточностей. В улучшенной диаграмме дополнительно отражено получение результатов из Textract и метаданных из DynamoDB функцией Lambda, а также сохранение сырых данных в другой бакет S3, что дает возможность последующим этапам работать с единой точкой доступа к данным. Ключевое исправление - удаление ошибочного утверждения, что S3 напрямую триггерит следующий Lambda, вместо чего показано правильное взаимодействие через очередь сообщений SQS, обеспечивающую асинхронную обработку и повышающую отказоустойчивость системы.
Третий этап - анализ документа - в исходной диаграмме ошибочно отображался вызов сразу трёх потоков в Bedrock, хотя на самом деле используется только один. Это уточнение позволяет обеспечить более компактное и понятное представление, где Bedrock обращается к данным из S3, а Analysis Lambda сохраняет результаты обратно. Опять же, переход от одного этапа к другому реализован через SQS, а не через прямой вызов или запись в S3. Завершающий этап - валидация документа - в исходном варианте был запутанным и избыточным, включал ресурсы типа AWS A2I и сложные циклы вызовов. Новая диаграмма демонстрирует гораздо более простое поведение Validate Lambda: она просто считывает данные из S3, проводит проверку и сохраняет результаты обратно в тот же бакет.
Это основано на фактическом исходном коде решения и отражает его настоящую логику, впрочем, оставляя возможность расширения и доработок по мере необходимости. Подобный анализ показывает важное различие между маркетинговыми и техническими диаграммами. Исходный вариант создан для демонстрации возможностей AWS в целом, с упором на доступность и наглядность для широкой аудитории, где точность в деталях уходит на второй план. Однако для разработчиков, которые работают непосредственно с конкретным решением, это становится серьёзным препятствием к пониманию и сопровождению. Использование детальных и аккуратных диаграмм последовательностей с подкреплением комментариями и интерактивностью (например, при наведении на элементы появляются пояснения) позволяет устранить эти проблемы и сделать архитектуру прозрачной и легко осваиваемой для специалистов с различным уровнем опыта.
В современном мире, где технологии беспрерывно развиваются и системы усложняются, создание качественной документации приобретает критическое значение. AWS и другие провайдеры облачных решений могут выигрывать, предлагая не только функциональные возможности, но и легко воспринимаемые и корректные схемы работы своих сервисов. Они должны соответствовать принципам правильного визуального оформления, подобно тому, как устоявшиеся практики объектно-ориентированного проектирования требуют детализированных диаграмм при разработке. Применение подобных подходов к AI обработке документов демонстрирует не только выгоду с точки зрения технической точности, но и повышает доверие со стороны заказчиков и конечных пользователей. Таким образом, основная задача при работе с архитектурными диаграммами - это баланс между доступностью и полнотой информации, между простотой и точностью, а также адаптация представления к целевой аудитории.
Внедрение диаграмм последовательностей и современных методов визуализации превращает техническую документацию из формальной формальности в живой источник знаний и обучения, что говорит о взрослении культуры разработки современных облачных приложений. Проекты, подобные AWS Intelligent Document Processing, выигрывают от таких улучшений, становясь примером не только инновационного подхода к AI, но и высококлассного инженерного исполнения, отраженного в качественном и прозрачном представлении своей архитектуры. .