В современном мире обработки данных и машинного обучения векторные эмбеддинги играют ключевую роль в задачах поиска и сопоставления информации. С их помощью реализуются системы рекомендаций, семантический поиск, обработка естественного языка и многие другие важные направления искусственного интеллекта. Однако с ростом объемов данных и размеров моделей возникает проблема эффективного хранения этих эмбеддингов — ведь высокоточные представления, как правило, требуют огромного объема памяти. В таких условиях крайне важным становится поиск способов сжатия векторных эмбеддингов при минимальных потерях качества. Одним из передовых и перспективных решений является методика квантования, позволяющая добиться сокращения объема памяти до 600%, сохраняя высокую точность поиска и сопоставления.
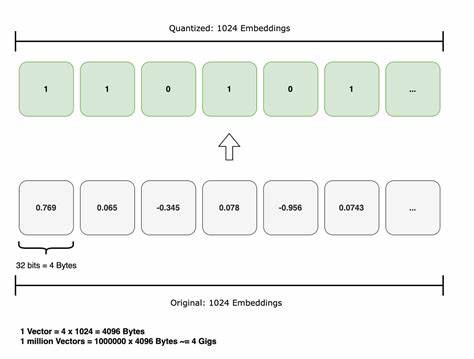
Методика квантования векторов основывается на том, что не все компоненты вектора одинаково важны для точности решения задачи. Вместо использования равномерного сжатия всех измерений, инновационные подходы применяют анализ статистических характеристик каждого измерения с целью определения их значимости. Например, анализ ковариационной матрицы позволяет выделить основные направления с высокой вариативностью данных — такие измерения несут больше информации и должны быть зафиксированы с большей точностью. Для измерений с высокой вариативностью применяется продуктовое квантование (Product Quantization), которое разбивает вектор на подблоки и сжимает их с помощью кода фиксированной длины, обычно 8 бит на измерение. Это позволяет сохранить максимум значимых особенностей данных.
Для измерений средней значимости применяется итеративное квантование (Iterative Quantization), которое кодирует информацию с меньшим числом бит — порой с 1 битом на измерение. При этом введение адаптивного порогового значения для вариативности измерений позволяет отказаться от хранения низковариативных признаков, что существенно снижает общий размер модели. Такое многоуровневое квантование — ключ к значительному уменьшению размера векторных индексов с сохранением релевантности поиска. Кроме того, современные реализации обеспечивают полную совместимость с лидирующей библиотекой Faiss, что делает внедрение данного подхода практически безболезненным для действующих систем. Интеграция идет через специально разработанные Faiss-совместимые индексы, позволяющие бесшовно заменять подсистемы, не меняя логику работы высокоуровневых сервисов.
Это открывает широкие возможности для их применения в различных бизнес-кейсах, начиная с систем рекомендаций и заканчивая интеллектуальным анализом больших данных в реальном времени. Среди дополнительных преимуществ квантования можно выделить встроенную оптимизацию гиперпараметров, которая позволяет автоматизировать подбор компромисса между уровнем сжатия и точностью поиска, исходя из характеристик конкретных данных. Такое решение значительно упрощает работу инженеров и исследователей, ускоряя процесс внедрения. Важно отметить, что все этапы алгоритма реализованы на высокоэффективном C++ с использованием типовых библиотек BLAS, что обеспечивает скорость и масштабируемость при работе с большими объемами данных. Несмотря на отсутствие поддержки GPU на данном этапе, оптимизации на CPU позволяют добиться высокой производительности на обычном серверном оборудовании.
Практическое применение этой технологии открывает новые горизонты для систем, где ограничено пространство хранения либо необходимо снизить себестоимость инфраструктуры. Особенно это актуально для проектов с ограниченными ресурсами, таких как edge AI и IoT-устройства, где важна экономия памяти без ущерба для качества. В реальных тестах применения нового подхода наблюдалось сокращение объема хранения до примерно 15.9% исходного размера, что в пересчете означает примерно шестиразовое сжатие. При этом точность поиска оставалась на уровне около 85% от эталонных результатов, что является отличным результатом для систем рекомендаций и семантического поиска.
Для специалистов в сфере машинного обучения и анализа данных данное решение является интересным выбором, позволяющим оптимизировать вычислительные ресурсы при реализации сложных проектов с большими объемами векторных данных. Эффективное использование квантования векторов — шаг к созданию более быстрых, экономичных и точных систем поиска информации в эпоху больших данных и искусственного интеллекта. В целом, внедрение продвинутого квантования эмбеддингов открывает путь к качественному опережению в конкурентных технологиях, где объемы данных растут стремительно, а требования к скорости и точности остаются высокими. Технологии, подобные описанной, становятся основой для будущих инноваций в интеллектуальных системах поиска и анализа, позволяя компаниям и исследовательским командам создавать более совершенные решения, экономя ресурсы и повышая эффективность.