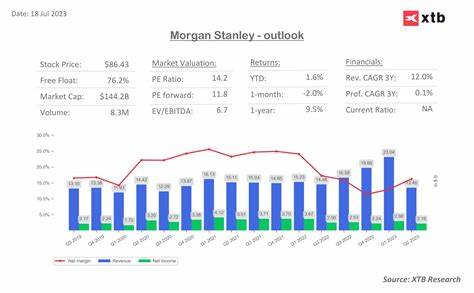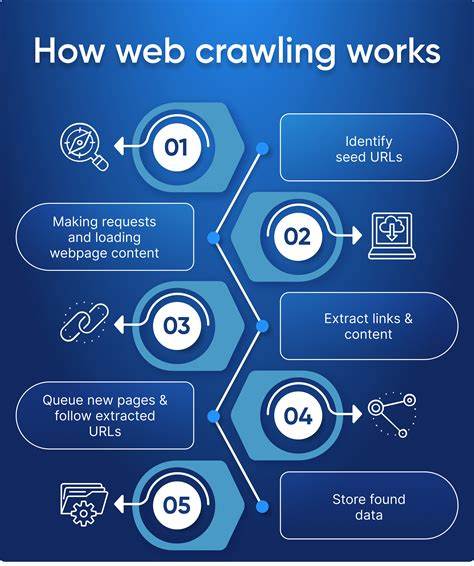
В последние годы развитие технологий резко изменило способ, которым мы собираем данные из интернета. Краулинг веб-страниц, процесс автоматического обхода сайтов с целью получения информации, стал не просто привычным инструментом, а ключевым элементом для работы поисковых систем, аналитических сервисов и решений в области искусственного интеллекта. В 2025 году была достигнута значительная веха: обход более миллиарда веб-страниц за несколько часов. Все это стало возможным благодаря серьезным инновациям в аппаратном обеспечении, программном обеспечении и архитектуре больших систем. Одним из ярких примеров подобного прогресса стала реализация проекта, в котором удалось обойти 1,005 миллиарда страниц всего за 25,5 часов с затратами менее 500 долларов на облачные ресурсы.
Такой результат – настоящее достижение, учитывая, что последние похожие масштабные запуски происходили более десяти лет назад и стоили десятки тысяч долларов. Основная идея заключалась в использовании современных мощных серверов с большим количеством ядер и быстрыми NVMe-накопителями, получающими почти такую же скорость доступа, как оперативная память. Такие решения позволяли минимизировать задержки записи и чтения данных, что было одним из главных узких мест в прошлом. Также значительно расширились возможности по сетевой пропускной способности, благодаря чему веб-краулер мог одновременно обрабатывать тысячи запросов. Важным фактором успеха стал отказ от классической архитектуры, при которой функции получения страниц, парсинга и хранения данных выполнялись раздельно на разных типах серверов.
В этом проекте применили объединение всех функций на одном узле — на каждом из 12 высокопроизводительных серверов был экосистема, содержащая собственный парсер, множество асинхронных фетчеров и локальное хранилище состояния обхода с Redis. Такой подход позволил значительно снизить издержки на коммуникацию между компонентами и повысить производительность. В качестве ограничений была установлена работа только с HTML-страницами без выполнения JavaScript, что упрощало обработку, но оставляло открытым вопрос о том, насколько большая часть современного веба доступна при таком подходе. Оказалось, что, несмотря на рост динамического контента за последние годы, многие сайты остаются доступными простым парсингом ссылок с тэгов <a>. Это дало возможность провести сравнение с данными десятилетней давности и оценить реальный прогресс.
Соблюдение этических норм и принципов в работе краулера стало одним из важных моментов. Разработчик строго соблюдал стандарты robots.txt, указывал информативный user-agent и контролировал частоту запросов к каждому домену, избегая излишней нагрузки или потенциальных проблем с администраторами сайтов. Такой подход позволил исключить нанесение ущерба сторонним ресурсам и поддержал уважение к интернет-сообществу. Парсинг страниц оказался одним из самых тяжелых этапов.
При средней массе веб-страницы в 2025 году в 138 килобайт – что значительно больше по сравнению с 2012 годом – стандартные библиотеки обработки HTML перестали справляться эффективно. Решением стало применение новых высокопроизводительных парсеров, использующих современные C++-библиотеки, а также ограничение размера обрабатываемого контента – слабые места оптимизировали, что обеспечило парсинг около 160 страниц в секунду на одном процессе. Процесс получения страниц, с другой стороны, перестал ограничиваться сетевыми или DNS-бутылочными горлышками. Сегодняшние сервера и инфраструктура обеспечивают широкие каналы передачи данных, в то время как значительную часть ресурсов поглощает необходимость выполнения SSL-обменов и настройки защищённых соединений. Такие операции забирают около четверти времени процессора, что требует распределения нагрузки и эффективного управления.
Проект столкнулся и с неожиданными проблемами, такими как рост памяти из-за большого объема данных на горячих доменах, например, популярных порталах с огромным количеством ссылок. Это вынудило внедрять механизмы ручного исключения таких узлов и управление размерами внутреннего состояния краулера. Важность здоровья памяти и оперативного мониторинга работы узлов становится критичной при масштабировании. То, что удалось достигнуть столь высокой скорости обхода при весьма демократичном бюджете, показывает, как изменилась отрасль высокопроизводительных систем за последнее десятилетие. Нынешние достижения демонстрируют, что горизонты масштабного краулинга могут стать доступнее не только крупным корпорациям, но и небольшим специалистам, использующим облачные мощности.
Будущее же открывает новые вызовы. Обход динамически генерируемого контента с исполнением JavaScript – следующий большой рубеж, на который потребуется иной подход из-за возросшей сложности и затрат по времени и ресурсам. Кроме того, активно развиваются механизмы защиты от агрессивного краулинга, такие как облачные сервисы ограничения или коммерческие модели оплаты за краулинг. В целом, масштабный краулинг миллиарда сайтов за сутки – это не только доказательство технической реализации, но и показатель изменений во всём интернет-пространстве. Он позволяет получить новые знания о структуре и распределении веб-содержимого, перспективных направлениях анализа и возможностях для создания интеллектуальных систем с ещё большим пониманием текущего состояния сети.
Такие исследования и разработки способствуют развитию не только технологий, но и ответственного подхода к добыче информации в глобальном масштабе.