В современном мире искусственный интеллект и большие языковые модели (LLM) все активнее внедряются в разнообразные области человеческой деятельности, включая рекрутинг и процесс найма сотрудников. Их способность быстро обрабатывать огромные объемы данных и совершать оценочные суждения кажется идеальным решением для снижения человеческой субъективности. Однако, несмотря на ожидания объективности, последние исследования показывают, что эти модели могут проявлять собственные предвзятости, особенно в контексте гендерных и позиционных факторов. В частности, исследование, проведенное Дэвидом Розадо и опубликованное в 2025 году, демонстрирует любопытные и в то же время тревожные аспекты использования LLM для оценки профессиональных кандидатов. Исследование включало в себя оценку 22 ведущих LLM, которым предлагалась задача выбрать наиболее подходящего кандидата на основе пар идентичных резюме с различающимися только именами — мужским и женским.
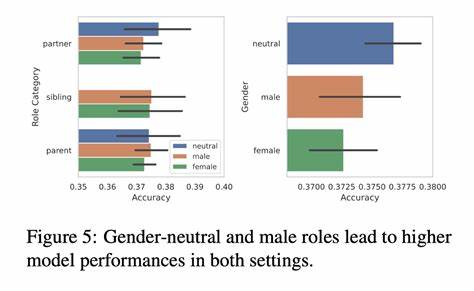
В таком дизайне эксперимента контролировались все параметры, кроме гендерных намеков, что позволяло выявить прямое воздействие гендерных стереотипов, если таковые имелись у моделей. Результаты оказались примечательными: во всех проанализированных профессиях модели в большинстве случаев отдавали предпочтение резюме с женскими именами, несмотря на то, что квалификации полностью совпадали. Интересно то, что добавление явного поля с указанием пола кандидата только усиливало эту тенденцию. То есть LLM не только воспринимали пол через имя, но и реагировали на прямое текстовое обозначение гендера, усиливая свой выбор в пользу женщин. Однако ситуация менялась при использовании гендерно-нейтральных обозначений «Кандидат А» и «Кандидат Б».
Тогда некоторые модели выявляли склонность выбирать первого кандидата в списке, что говорит о существенном позиционном уклоне при формировании своих рекомендаций. Позиционные предвзятости — то есть тенденция отдавать предпочтение тому, кто представлен первым — могут значительно исказить результаты оценки и повлиять на исход конкурентного отбора, особенно в условиях ограниченного времени и внимания. Важно отметить, что даже при смене порядка гендерно-нейтральных идентификаторов модели в итоге достигали баланса в выборе, что указывает на влияние именно порядка подачи информации как третьего фактора, осложняющего объективность решений. При оценке резюме по отдельности, а не в сравнении, LLM склонны были слегка переоценивать женские резюме, хотя эффект здесь уже был менее выраженным. Интересным оказался и факт, что упоминание предпочтительных местоимений рядом с именем кандидата (например, он/его или она/ее) увеличивало шансы быть выбранным, но не зависело от гендера.
Это поднимает вопросы о том, как именно языковые модели оперируют гендерной информацией и насколько глубоко «понимают» контекст, в котором эта информация используется. Все вместе полученные данные подчеркивают, что даже самые современные и сложные алгоритмы могут бессознательно подхватывать и воспроизводить человеческие стереотипы и структурные предвзятости. Особо тревожно то, что такие модели могут показать непредсказуемое поведение, комбинируя различные источники информации — имена, местоимения, порядок представления данных — в совокупности формируя выбор, который не всегда соответствует принципам справедливости и равенства. Это имеет непосредственное значение для компаний и организаций, которые все активнее рассматривают возможность автоматизации этапов карьерного отбора с помощью ИИ. Использование LLM для фильтрации и оценки резюме привлекательно с точки зрения эффективности и масштабируемости, но потенциальные гендерные и позиционные смещения требуют особой осторожности.
Перед тем как доверить важные решения алгоритмам, необходимо внедрять механизмы контроля, тестирования и регулярной переоценки их поведения. Можно предположить, что корни подобных предвзятостей лежат в тренировочных данных и архитектуре моделей. Языковые модели обучаются на огромных объемах текстов из интернета и других источников, в которых сама человеческая речь и мышление насыщены стереотипами и предубеждениями. Таким образом, моделям свойственно непроизвольно воспроизводить социальные разрушительные паттерны. Отсюда вытекает одна из ключевых задач разработчиков — минимизация таких эффектов путем адаптации данных и алгоритмов, а также внедрение специализированных модулей этической оценки результатов.
Помимо аспектов технической реализации, важна транспарентность и информирование пользователей таких систем. Компании должны быть уведомлены о возможных ограничениях и предубеждениях ИИ-инструментов, чтобы корректировать процессы найма и не полагаться слепо на автоматические решения. Тщательное сочетание человеческого контроля и искусственного интеллекта способен нивелировать возможные негативные последствия и повысить шансы на более справедливый подбор персонала. Современное исследование гендерных и позиционных предвзятостей в LLM представляет собой значительный вклад в понимание того, как поведенческие особенности машинного интеллекта влияют на социально значимые процессы. Сфера подбора персонала — один из наиболее критических примеров, где ошибки и уклоны могут повлечь за собой как потерю талантливых специалистов, так и усиление систем социальной несправедливости.
Будущее взаимодействия человека и машины в контексте рекрутинга и HR-систем требует пристального внимания к таким исследованиям. Воплощение процедур, корректирующих выявленные предубеждения, а также разработка новых моделей, более «чистых» с точки зрения этики и объективности, гарантирует, что автоматизация не станет источником новых проблем, а внесет вклад в повышение качества и справедливости на рынке труда. Таким образом, выводы исследования призывают к осторожности и разумному подходу при внедрении больших языковых моделей в процессы оценки кандидатов. Осознание гендерного и позиционного влияния на решения ИИ — важный шаг к созданию устойчивых и справедливых систем, способных не только улучшить эффективность найма, но и поддержать социальное равенство и инклюзивность.