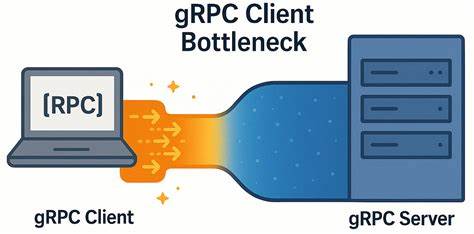
Современные распределённые системы и микросервисные архитектуры активно используют gRPC — высокопроизводительный фреймворк удалённого вызова процедур, построенный на основе HTTP/2. Его популярность обусловлена удобством работы, поддержкой строгой типизации, двоичной сериализацией и возможностями масштабирования. Однако, несмотря на все преимущества gRPC, разработчики и инженеры сталкиваются с неожиданными проблемами производительности, которые могут сильно влиять на качество работы приложений, особенно в условиях сетей с низкой задержкой. Одной из таких проблем является узкое место, возникающее на стороне клиента gRPC, которое значительно лимитирует пропускную способность и увеличивает клиентскую латентность. Интересно, что эта «узкость» проявляется именно в высокоскоростных сетях с минимальной задержкой, где от клиент-серверных взаимодействий ожидается максимальная отзывчивость и стабильность.
При этом на стороне сервера нередко наблюдается недогрузка ресурсов, что указывает на то, что причиной задержек является не пропускная способность сети или сервера, а именно реализация и конфигурация клиента. Суть проблемы заключается в том, что при использовании одного TCP-соединения для работы нескольких каналов gRPC и нескольких параллельных запросов происходит некоторая форма внутренней блокировки и задержки отправки новых запросов. gRPC использует HTTP/2 и механизмы мультиплексирования потоков поверх одного соединения, что с одной стороны экономит ресурсы, но с другой — накладывает ограничения на максимальное число одновременных потоков. Когда этот лимит достигается, последующие RPC-запросы оказываются в очереди и вынуждены ждать завершения предыдущих. По умолчанию число параллельных потоков в HTTP/2 ограничено сотней, но даже при меньшем числе одновременных запросов наблюдается деградация производительности.
Инженеры, работающие над оптимизацией YDB — открытой распределённой СУБД с поддержкой строгой консистентности и ACID-транзакций, подробно исследовали этот феномен. Их наблюдения показали, что при уменьшении числа узлов кластера увеличивается количество простаивающих ресурсов, а клиентская латентность, наоборот, растёт. Причём на сервере не возникало проблем с пропускной способностью или задержками при обработке запросов. Проведённые эксперименты выявили, что виновником является сам клиент и то, как он управляет каналами и соединениями. Для исследования была разработана простая тестовая среда — микробенчмарк на C++, включающий gRPC-сервер и клиент.
Клиент создаёт заданное количество рабочих потоков, каждый из которых выполняет RPC-вызовы, используя отдельный канал. Однако при этом все каналы использовали одинаковые параметры конфигурации, и фактически gRPC multiplex-ировала все вызовы через одно TCP-соединение. В условиях низкой сетевой задержки (около нескольких десятков микросекунд) опыт показывал, что несмотря на параллелизм, производительность росла далеко не пропорционально количеству активных потоков, а задержка увеличивалась с каждым новым запросом. Тщательный разбор сетевого трафика свидетельствовал, что основное время терялось в простой клиента после получения ACK с сервера. Несмотря на отсутствие сетевых проблем — вроде потерь пакетов, задержек в подтверждениях или сжатия TCP окна — клиент слишком долго ждал перед отправкой следующего запроса, что являлось следствием внутреннего конкурирования за ресурсы и ограничений HTTP/2.
В ходе последующих экспериментов была проверена рекомендация официальной документации gRPC по разделению нагрузки на несколько каналов с разными аргументами конфигурации. Это позволило добиться существенного прироста производительности — в некоторых случаях увеличения пропускной способности в 4–6 раз и значительного уменьшения задержек. Основным приёмом стала модификация так, чтобы каждый рабочий поток использовал отдельный канал с уникальными параметрами, что приводило к установлению самостоятельных TCP-соединений и, как следствие, устранению фактора мультиплексирования, ограничивающего параллельность. Интересно, что в сетях с высокой задержкой (около 5 миллисекунд) данная проблема практически не проявляется. Там узким местом становится сама сеть, и внутренние задержки клиента оказываются несущественны.
Однако в современных ЦОДах, где пропускная способность и задержки сети стремятся к минимальным значениям, устранение клиентских ограничений становится критически важным для обеспечения максимальной эффективности. Для профессионалов и разработчиков, внедряющих gRPC в высоконагруженных системах, выводы этой работы особенно полезны. Во-первых, необходимо учитывать, что оптимизация только серверной части и сети не гарантирует избавления от узких мест — важным фактором оказывается клиентская архитектура. Во-вторых, рекомендуемым подходом является использование портирования нагрузки на несколько каналов с уникальными параметрами, что фактически создаёт собственный пул TCP-соединений. Этот метод обеспечивает масштабируемость, позволяя работе клиентов «разбегаться» по разным линиям связи с сервером.
Исследование YDB также обращает внимание на важность правильного распределения потоков и привязки их к конкретным CPU и NUMA-узлам, что способствует минимизации накладных расходов и потерь производительности. Современный микробенчмарк демонстрирует, как принцип правильного управления потоками значительно влияет на стабильность и эффективность обмена данными. Наконец, стоит упомянуть, что это открытая проблема и потенциально существуют и другие оптимизации на уровне gRPC клиента, которые могут дополнительно повысить производительность. Разработчики призывают к сотрудничеству и обмену опытом с сообществом для выявления и устранения таких узких мест. Таким образом, неожиданное узкое место клиента gRPC в условиях низкой сетевой задержки оказывает существенное влияние на общую производительность распределённых систем.
Понимание этого явления и применение грамотных методов масштабирования клиентских каналов являются ключом к достижению высокой пропускной способности и минимальной латентности, что особенно актуально для современных высоконагруженных и требовательных к скорости отклика приложений.