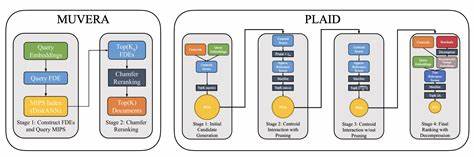
Современный информационный поиск переживает эпоху значительных изменений благодаря прогрессу в использовании нейронных эмбеддингов. В то время как классические модели преобразовывали каждый объект в единственный эмбеддинг, новые мультивекторные модели, такие как ColBERT, работают с наборами векторов, значительно повышая качество поиска. Однако высокая вычислительная сложность и увеличенный объем данных в мультивекторных подходах порождали задачу оптимизации: как сохранить точность, не жертвуя скоростью? Ответом стала система MUVERA — инновационный алгоритм, способный ускорить мультивекторный поиск, при этом обеспечивая точность, сопоставимую с оригинальными сложными методами. MUVERA сводит сложность мультивекторного поиска к простой процедуре поиска максимального внутреннего произведения одиночных векторов, что открывает путь для использования высоко оптимизированных алгоритмов MIPS (maximum inner product search). В основе MUVERA лежит идея фиксированных по размерности кодирований (Fixed Dimensional Encodings, FDE), которые кодируют набор мультивекторов запроса и документа в один вектор.
При сравнении этих FDE с помощью внутреннего произведения достигается приближенная оценка оригинального сложного мультивекторного сходства, например, по метрике Chamfer similarity. Эта метрика учитывает взаимное покрытие информации двух наборов векторов и отражает, насколько один мультивектор детально соответствует другому, что существенно превосходит простое сравнение одиночных представителей. Сам подход формирования FDE базируется на случайном разбиении пространства эмбеддингов с помощью гиперплоскостей, что позволяет распределять векторы по отдельным блокам кода с разными способами агрегации для запросов и документов. Для запросов агрегируются суммы по блокам, для документов — средние значения, что точно отражает асимметрию в метрике Chamfer. Теоретические исследования, проведённые авторами, подтвердили, что такой подход даёт гарантированное приближение оригинальной меры сходства с известной ошибкой, а сама трансформация является дата-оближающей — она не зависит от конкретного распределения данных, что повышает её универсальность и устойчивость к изменениям в наборах данных.
Практические эксперименты показали высокую эффективность MUVERA на популярных бенчмарках BEIR. Алгоритм позволил более чем в десять раз сократить время поиска по сравнению с существующими решениями, такими как PLAID, при этом улучшив качество выборки кандидатов для оценки. Это достигается за счёт уменьшения количества кандидатов, требующих дальнейшего анализа, в пять-двадцать раз при сохранении качества точности. Дополнительно FDE демонстрируют хорошую компрессию с использованием product quantization, что снижает занимаемую память более чем в тридцать два раза без существенного ущерба для качества результатов. Такие достижения делают MUVERA крайне привлекательным для широкого спектра приложений: поисковых систем, рекомендательных механизмов, анализа естественного языка и даже мультимодальных систем, где объекты описываются сложными совокупностями векторов.
MUVERA фактически переопределяет оптимальный баланс между скоростью и точностью в информационном поиске на больших объемах данных при использовании мультивекторных эмбеддингов. Тем самым он открывает новые возможности для внедрения глубоких нейронных моделей в реальные системы обработки информации с миллиардами документов и запросов. Будущее мультивекторного поиска явно связано с развитием подобных гибридных решений, которые сочетают в себе лучшие свойства классических алгоритмов с новыми мощными представлениями данных. MUVERA служит примером того, как сложные алгоритмические вызовы можно преодолевать, используя инновационные методы кодирования и адаптацию теоретических основ геометрии и вероятностных разбиений пространства. Именно такой междисциплинарный подход способен вывести задачи информационного поиска на новый уровень производительности.
С открытым исходным кодом реализации MUVERA, предоставленным исследователями Google, разработчики и ученые получили мощный инструмент для дальнейших экспериментов и внедрения. Это способствует расширению экосистемы мультивекторного поиска и повышает доступность передовых алгоритмов для сообщества. В итоге MUVERA не только решает текущие технические проблемы многоекторного поиска, но и прокладывает путь для новых исследований и технологий, связывающих теорию и практику. Так, инновации в области многомерного кодирования и оптимизации реализуют потенциал современных моделей и способствуют появлению более интеллектуальных, быстрых и масштабируемых систем поиска информации в будущем.







