В современном мире искусственного интеллекта инфраструктура играет критически важную роль, определяя эффективность и скорость разработки моделей. Существует две основные экосистемы, претендующие на лидерство в управлении вычислительными ресурсами для AI-нагрузок — Slurm и Kubernetes. Обе системы возникли из разных сред и подходят для разных задач, и в их сравнении прослеживается глубокое противоречие между академическими HPC кластерами и облачной, нативной для облака реальностью. Несмотря на плодотворные попытки объединить лучшее из этих миров, современные AI-нагрузки продолжают ставить сложные вызовы, которые ни одна из систем не решает идеально. Slurm уверенно ассоциируется с академическими и научными вычислениями, являясь стандартом для кластеров HPC с начала 2000-х годов.
Его сильным местом является пакетное планирование задач и особенно функция gang scheduling — одновременное выделение всех требуемых ресурсов для распределённых задач. Это крайне важно в AI, когда обучение крупной модели на десятках GPU требует гарантированной доступности всего запрошенного пула одновременно. Для исследователей, привыкших к командам типа sbatch и srun, Slurm предлагает предсказуемость и стабильность в распределении ресурсов. Разработчики ценят, что после выделения нужных GPU, эти ресурсы закрепляются за задачей как минимум до её завершения, что исключает неожиданные перемещения и снижение производительности во время длительного обучения. Однако такой традиционный подход приводит к ряду ограничений.
Во-первых, Slurm практически не контролирует изоляцию ресурсов на уровне отдельных процессов. Ошибки в конфигурации или непредсказуемые всплески потребления памяти могут привести к сбоям всего узла, что затрудняет работу на разнотипных и динамичных нагрузках AI. Во-вторых, кластеры Slurm — это обычно стационарные, статичные пулы оборудования. При достижении лимита мощностей приходится либо ждать освобождения, либо запускать сложные процедуры добавления новых узлов, что не всегда возможно или удобно. Кроме того, Slurm плохо подходит для развертывания служебных задач, связанных с inference и API, поскольку изначально ориентирован на пакетные задачи, а лёгкие веб-сервисы не вписываются в его модель.
Отсутствие официального консольного интерфейса с графикой также усложняет мониторинг и управление, особенно для менее технических пользователей. В отличие от этого, Kubernetes разрабатывался с 2014 года как оркестратор для микросервисов и облачных приложений, ориентированных на горизонтальное масштабирование и отказоустойчивость. Он гибок, адаптивен и обладает встроенными механизмами авторасширения и сжатия кластера. Это особенно выгодно для инфраструктуры ИИ, где стоимость простаивающих GPU достигает ощутимых сумм. Kubernetes предлагает единое пространство для разнородных рабочих нагрузок — обучающих заданий, inference сервисов, ETL-пайплайнов и систем мониторинга.
Обширная экосистема и проекты на базе K8s, такие как Kubeflow или Volcano, дополняют возможности платформы AI-ориентированными инструментами. Тем не менее, Kubernetes также далек от совершенства в работе с AI. Его стандартный планировщик не поддерживает полноценное gang scheduling для распределённого обучения, что вызывает ситуации взаимной блокировки ресурсов. Для более масштабного ИИ использования корпорации, например Google при работе с TPU, пришлось создавать сложнейшие расширения и модификации. Управление ресурсами в Kubernetes с AI задачами требует высокой квалификации, а даже простые для Slurm скрипты превращаются в громоздкие и сложные YAML-манифесты, что тормозит интерактивное исследование моделей и затрудняет отладку.
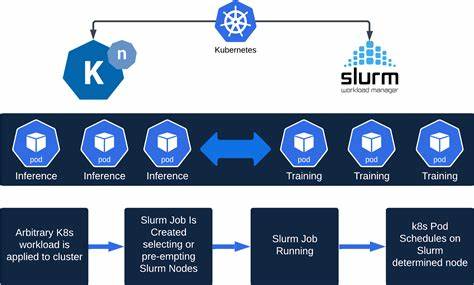
Кроме того, архитектура K8s ориентирована на декларативное управление, что противоречит гибкой, экспериментальной работе исследователей. Столкнувшись с этими противоположностями, индустрия начала экспериментировать с гибридными решениями. Среди них выделяется Slurm-on-Kubernetes — проекты, размещающие Slurm-кластер внутри Kubernetes, обеспечивая знакомую подсистему для исследователей и одновременно пользуясь преимуществами облачной масштабируемости. Однако такие решения зачастую вынуждены резервировать целые узлы Kubernetes для Slurm, что ограничивает совместное использование ресурсов и снижает эффективность. Дополнительные надстройки над K8s, вроде Volcano и Kueue, улучшают планирование заданий и повышают производительность, но сохраняют высокую сложность эксплуатации и необходимость глубоких знаний Kubernetes.
Другой широко распространённый подход — разделение задач обучения и обслуживания моделей между разными платформами: Slurm используется для пакетного обучения, а сервисы inference запускаются в Kubernetes. Этот метод позволяет играть на сильных сторонах обеих систем, но ведёт к раздробленности инфраструктуры, росту операционных нагрузок и снижению общей эффективности использования ресурсов. В свете этих вызовов появляются новые инструменты, призванные упростить работу команд ИИ и скрыть инфраструктурные детали. Один из примеров — SkyPilot, который предлагает абстракцию, позволяющую запускать одинаковые задания на любом основании — будь то Kubernetes или облачные провайдеры разных регионов и провайдеров. Это даёт гибкость мультиоблачных стратегий, упрощает масштабирование и автоматизирует подбор ресурсов без необходимости изучать детали каждого оркестратора.
Подобные абстракции создают новую парадигму, где компании могут сосредоточиться на построении моделей и исследованиях без глубокого погружения в вопросы инфраструктурного администрирования. В конечном счёте, будущее AI-инфраструктуры, скорее всего, будет связано с гибкими и удобными слоями абстракции поверх фундаментальных систем Slurm и Kubernetes, а сами платформы продолжат развиваться, адаптируясь к потребностям современного машинного обучения. Таким образом, приоритет не стоит только в выборе между Slurm и Kubernetes. Задача — найти правильные комбинации, интеграции и инструменты, позволяющие с минимальными затратами времени и сил запускать эффективные и масштабируемые AI-нагрузки. Академические HPC и облачные технологии дополняют друг друга, создавая целостную экосистему, где каждая технология раскрывает свои преимущества в нужных сценариях.
В конечном итоге ключом к успеху станет архитектурная гибкость, мультиоблачность, а также создание удобных интерфейсов для исследователей и инженеров, позволяющих убирать инфраструктурную сложность из процесса создания искусственного интеллекта.