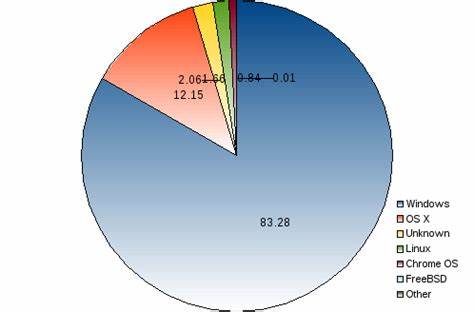
В современном мире информационных технологий операционные системы играют роль главного связующего звена между аппаратным обеспечением и пользователем. Статистика использования ОС часто является ключевым индикатором для разработчиков, аналитиков, маркетологов и исследователей индустрии. Однако при изучении данных о рыночной доле операционных систем в различных источниках, таких как StatCounter, часто можно заметить значительную часть, обозначенную как «неизвестные» или «unknown» операционные системы. Зачем появляются такие данные? Что скрывается за данной категорией и почему ее доля может достигать двузначных процентов? Попробуем разобраться более подробно в этом феномене и выяснить, какие факторы влияют на появление этого показателя в статистике. Первое, что нужно понимать — это природа сбора данных в подобных системах.
Большинство сервисов аналитики строятся на отслеживании информации, передаваемой браузерами и устройствами при посещении сайтов. Среди прочего, собираются данные о типе операционной системы, используемой пользователем. Однако получение точной информации не всегда возможно. В некоторых случаях браузеры и устройства не передают подробные или корректные данные об операционной системе, либо данные искажаются или скрываются пользователями, что приводит к классификации таких заходов как «неизвестные». Часть причин, приводящих к появлению категории «неизвестные» ОС в статистике, связана с техническими аспектами.
Во-первых, некоторые браузеры или программы могут умышленно скрывать данные об операционной системе в целях повышения приватности или безопасности пользователя. Например, приватные браузеры, такие как Brave, могут маскировать информацию, чтобы препятствовать отслеживанию. Во-вторых, ряд устройств и операционных систем базируются на необычных платформах, которые сложно определить стандартными методами. Это могут быть специализированные версии ОС, малоизвестные дистрибутивы Linux, кастомные версии Android или даже новейшие альтернативные системы, такие как Haiku OS, упомянутая пользователем с форума Hacker News. Интересно заметить, что в некоторых странах доля «неизвестных» операционных систем может быть особенно высокой.
Например, в Индии при фокусировке на десктопные ОС эта цифра порой превышает 25%. Такая аномалия вызывает вопросы, поскольку маловероятно, что четверть пользователей сознательно использует незарегистрированные или скрываемые системы. Более вероятны несколько объяснений: во-первых, в странах с более низким уровнем стандартизации и большим количеством бюджетных устройств, используемые ОС могут иметь модифицированные версии или быть частично несовместимы с аналитическим ПО. Во-вторых, это может быть следствием использования прокси-серверов, VPN или вредоносных программ, искажающих данные о системе пользователя. В-третьих, это может быть отражение разнообразия локальных и непопулярных операционных систем, разработанных для специфических задач.
Нарастающий тренд в появлении 'неизвестных' ОС также совпал со временами появления новых альтернативных операционных систем. Например, Haiku OS, основанная на BeOS, вышла на этап бета-тестирования в 2018 году, что совпало с ростом сегмента «неизвестные» в статистике. Хотя влияние такой системы на общую статистику сомнительно, это служит примером того, как новые платформы могут не распознаваться привычными методами анализа. Также стоит отметить, что часть трафика, который попадает под категорию «неизвестные ОС», может приходиться на разнообразных роботов и сканеров, несмотря на заявления о фильтрации. Некоторые боты изначально маскируются под обычных пользователей, но при этом не передают достаточно данных для точного определения операционной системы.
В то время как большинство аналитических сервисов учатся фильтровать такие источники, полного отсева добиться сложно. Важным моментом является отличие между «неизвестными» на уровне браузера и операционной системы. Браузеры зачастую указывают информацию о платформе в заголовках запросов, но эта информация может быть изменена, отсутствовать или быть повреждена. В результате средства аналитики, ориентированные на автоматический сбор данных, просто не могут распознать систему, и заход классифицируется как неопределённый или неизвестный. Это может включать редкие платформы, устаревшие версии ОС, пользовательские сборки, а также системы с минимальным пользовательским интерфейсом или серверные решения.
Рассматривая проблему с практической точки зрения, высокое число неизвестных ОС в статистике может представлять затруднения для бизнеса и маркетологов. Отсутствие четкого понимания о том, на каких платформах взаимодействует аудитория, затрудняет оптимизацию приложений и сервисов под реальные условия эксплуатации. Поэтому важно сочетать данные автоматической статистики с дополнительными исследованиями, опросами и обратной связью от пользователей. Важной тенденцией в развитии аналитических сервисов является постоянное улучшение методов распознавания платформ пользователей. Используются уже более продвинутые методы анализа User-Agent, дополнительные параметры сети и поведения, а также машинное обучение для корректной классификации устройств и систем.
Такие технологии позволяют снижать долю неопределённых данных и повышать качество статистики. Однако полностью исключить категорию «неизвестное» сложно, учитывая постоянное появление новых систем и нестандартных конфигураций. Подводя итог, можно утверждать, что термин «неизвестные операционные системы» отражает сочетание множества факторов, связанных с технологическими, пользовательскими и методологическими аспектами сбора статистики. Значительная доля таких данных не значит, что в мире существует огромное количество скрытых или экзотических ОС. Скорее, это индикатор того, что современные методы сбора информации имеют свои ограничения и сталкиваются с разнообразием современных цифровых устройств и настроек.
Для пользователей и специалистов, работающих с аналитикой, имеет смысл учитывать наличие таких неопределённых данных и стремиться к их минимизации за счёт комплексного подхода к сбору и обработке информации. Внимание к проблеме «неизвестных ОС» помогает лучше понимать структуру аудитории и улучшать процессы адаптации программных решений к реальным условиям рынка. В конечном счёте, это ведёт к повышению качества взаимодействия с конечными пользователями и успеху технологических продуктов.