Человеческие оценки играют важнейшую роль во многих сферах науки и бизнеса, от обработки данных и машинного обучения до медицинской диагностики и социальных исследований. Несмотря на то, что в эпоху инновационных технологий часто говорят об автоматизации и искусственном интеллекте, человек по-прежнему остаётся основным источником качественных меток и разметки данных. Однако человеческие суждения подвержены влиянию субъективности, контекста и временных факторов, что вызывает вопросы о качестве таких данных. В связи с этим специалисты сталкиваются с необходимостью понимать и измерять достоверность и надёжность человеческих оценок, чтобы гарантировать максимальную точность и воспроизводимость результатов. Понимание ключевых понятий: надёжность и достоверность Прежде чем перейти к практическим методам измерения, важно разобраться в основных терминах.
Надёжность — это степень последовательности и стабильности измерений во времени или между разными оценщиками. Если разные люди, оценивающие один и тот же объект при схожих условиях, дают очень похожие результаты, то говорят о высокой надёжности измерений. Достоверность, в свою очередь, отражает, насколько измерение соответствует тому, что оно пытается измерить — то есть насколько полученные данные представляют реальную сущность, концепцию или характеристику объекта. Высокая достоверность гарантирует, что оценка отражает именно тот признак, который был предметом измерения, а не иной сопутствующий фактор. Эти два понятия взаимосвязаны: надёжность является необходимым, но недостаточным условием для достоверности.
Без стабильных измерений мы не можем добиться правдивых результатов. Тем не менее, даже стабильные, повторяемые данные могут быть невалидными, если наша методика оценивает не то, что нужно. Проблемы человеческой оценки: источники ошибок и субъективности Несмотря на кажущуюся простоту задачи, человеческая оценка часто сопряжена с множеством невидимых проблем. К ним относятся: Субъективность восприятия — жизненный опыт, культурные особенности и личные предпочтения каждого человека влияют на его восприятие и принятие решений. Неоднозначность или контекст задачи — некоторые объекты сложно классифицировать однозначно.
Например, вопрос «Насколько смешна шутка?» не имеет объективного критерия. Изменчивость понятий во времени — стандарты и понимания меняются, как и сами объекты оценки. Ошибки и усталость — психологические факторы также вносят шум в оценочные данные. Учитывая эти сложности, непременно нужен системный подход к оценке качества человеческих меток. Методики оценки надёжности: от коэффициента Каппа к межгрупповым сравнениям Самым известным показателем для измерения согласия между двумя оценщиками является коэффициент Каппа.
Он учитывает вероятность случайного совпадения ответов и показывает, насколько наблюдаемое согласие выше случайного уровня. Значения Каппа варьируются от -1 (полное расхождение) до 1 (совершенное согласие). Положительные значения, как правило, выше 0,6, считаются признаком хорошей надёжности. Однако Каппа применяется при сравнении двух оценщиков и номинальных (категориальных) данных. Для более сложных сценариев разработаны обобщённые метрики, которые учитывают множество оценщиков и различные типы исходных данных.
Современная концепция, известная как Cross-Replication Reliability (xRR), расширяет измерения надёжности на сравнение между разными группами оценщиков. Это особенно важно, когда необходимо проверить, насколько люди с разным опытом — например эксперты и обычные пользователи — сходятся во мнениях. В этом случае xRR измеряет степень совпадения оценок между группами и становится инструментом не только надёжности, но и валидности. Валидация оценок: нужен ли эталон и как с ним работать? Проверка валидности напрямую связана с наличием «золотого стандарта» — набора данных, метки в котором считаются максимально точными и истинными. Однако такие данные часто труднодоступны, а иногда даже невозможны из-за субъективного характера задачи.
В таких ситуациях эксперты выступают в роли эталонных оценщиков. Тем не менее и здесь возникают сложности — частое расхождение мнений даже у специалистов, изменчивость концепций и неоднозначность вопросов усложняют построение единого стандарта. Поэтому применение xRR для интерпретации сходства между экспертными и неспециализированными оценками становится мощным инструментом, обеспечивая количественную оценку валидности без необходимости наличия абсолютной истины. Статистические подходы и модели для измерения качества оценок Помимо непараметрических показателей, таких как Каппа и xRR, значительное внимание уделяется параметрическим моделям, которые позволяют глубже анализировать данные и берут на себя учет вариативности и системных смещений. Одним из ключевых параметров является Интра-классовая корреляция (Intraclass Correlation Coefficient, ICC).
Она рассчитывается на основе вариации между объектами и вариацией, обусловленной оценщиками и случайной ошибкой. При этом ICC отражает степень, в которой наблюдаемые оценки отражают истинный рейтинг объектов. Для количественных (континуальных) данных модели обычно основаны на нормальном распределении. Для бинарных или категориальных данных применяют вариации моделей с логистической регрессией и соответствующими аппроксимациями дисперсии. Использование этих моделей позволяет не только оценить надёжность, но и прогнозировать эффект изменения числа оценщиков с помощью известных формул, таких как формула Спирмена-Брауна.
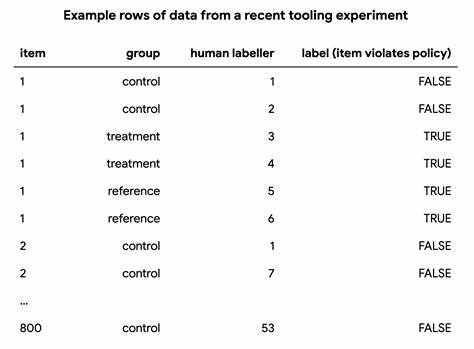
Это помогает оптимизировать исследовательские дизайны, экономя ресурсы и повышая эффективность сбора данных. Практический пример: оценка изменений в инструментальных платформах Рассмотрим пример изучения влияния обновлений инструментов для разметки данных в задаче модерации контента. При наличии экспертов, чьи оценки считаются эталонными, и двух групп обычных оценщиков, которые работают с разными версиями инструментов (контроль и эксперимент), можно сравнить качество данных и сделать вывод о том, какое изменение положительно влияет на результаты. Анализ межэкспертной надежности показал, что хотя контрольная группа демонстрировала более высокие показатели согласованности, она при этом переоценивала нарушения политики, что снижало валидность их оценки по сравнению с экспертами. Экспериментальная группа с новыми инструментами, несмотря на снижение надёжности, обеспечила более близкие к экспертным метки, подтверждённые значениями xRR и его нормализованной версии.
Таким образом, совокупное рассмотрение как надежности, так и валидности — критично для полноценного понимания качества человеческих рейтингов и принятия обоснованных решений по улучшению процессов сбора данных. Заключение Качество данных, получаемых с помощью человеческих оценок, оказывает существенное влияние на результаты исследовательских проектов, моделей машинного обучения и бизнес-приложений. Несмотря на присущие человеческому фактору неопределённости и субъективности, комплексное использование метрик надежности и валидности позволяет добиться высокого уровня качества и уверенности в результатах. В мире, где субъективные и абстрактные оценки становятся частью анализа и принятия решений, важно применять продвинутые статистические методы и осознано подходить к организации сбора данных. Инструменты, такие как коэффициент Каппа, модифицированные показатели межрецензентской надежности и модели с использованием ICC, наряду с концепцией cross-replication reliability, позволяют выявлять слабые места и систематически улучшать процессы разметки.
Эффективное понимание и использование этих методов открывает путь к тому, чтобы все больше и больше человеческих оценок можно было воспринимать как надежные и достоверные данные, что становится основой инноваций в области искусственного интеллекта, медицины, социальных наук и многих других областях.