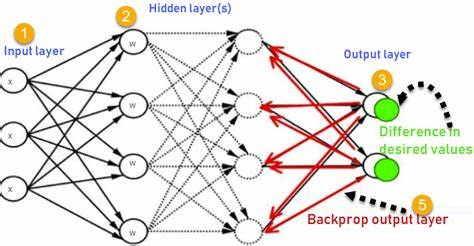
В современном цифровом мире нейронные сети занимают ключевое место в инфраструктуре искусственного интеллекта и машинного обучения. Их способность решать сложные задачи, которые ранее казались непосильными для классических алгоритмов, делает их незаменимыми в самых разных сферах — от распознавания образов и обработки естественного языка до предсказаний в финансовом секторе и медицинских диагностик. Чтобы понять, почему нейронные сети так востребованы, а их обучение эффективно, необходимо разобраться в базовых принципах, которые лежат в их основе, и в процессе, известном как обратное распространение ошибки или backpropagation. Нейронные сети — это вычислительные модели, вдохновлённые работой биологического мозга. Они состоят из множества взаимосвязанных узлов — нейронов, образующих несколько слоёв: входной, скрытые слои и выходной.
Каждый нейрон получает сигналы от нейронов предыдущего слоя, производит вычисления и передаёт результат дальше. Главная особенность нейронных сетей — их способность к обучению, то есть изменению весов связей между нейронами, чтобы улучшать качество предсказаний или классификаций. Это особенно важно, когда речь идёт о данных с высокой сложностью и большим количеством вариаций. Классические алгоритмы часто не справляются с такими задачами, тогда как нейронные сети с правильно настроенными параметрами способны выявлять закономерности в огромных объёмах информации. Почему же нейронные сети стали таким прорывом в искусственном интеллекте? Ответ кроется в их универсальности и гибкости.
Они способны моделировать очень сложные нелинейные зависимости, с чем традиционные методы обработки данных и машинного обучения часто оказываются бессильны. Например, в области обработки изображений нейронные сети могут распознавать объекты, даже если они находятся в нестандартных ракурсах или освещении. Аналогично, в задачах обработки речи и текста они помогают не только понимать отдельные слова, но и учитывать контекст. Сердцем процесса обучения нейронной сети является оптимизация её параметров — весов и смещений. Эта оптимизация основана на минимизации ошибки предсказания, то есть разницы между желаемым результатом и фактическим выходом сети.
Для того чтобы понять, как именно корректируются веса, необходимо познакомиться с алгоритмом обратного распространения ошибки, который предложил Джеффри Хинтон в 1986 году. Обратное распространение — это метод, с помощью которого нейронная сеть «учится» на своих ошибках. После того как сеть совершает предсказание и получает оценку ошибки, этот алгоритм распространяет сигнал ошибки обратно через слои нейронов, вычисляя градиенты функции ошибки по отношению к каждому весу. Полученные градиенты используются для корректировки весов в направлении уменьшения ошибки, что и позволяет постепенно улучшать точность сети. Процесс обратного распространения тесно связан с понятием градиентного спуска, который представляет собой метод поиска минимального значения функции ошибки.
На практике обучение нейронной сети происходит итеративно: сеть получает входные данные, делает предсказание, рассчитывает ошибку, затем с помощью обратного распространения корректирует веса и повторяет эти шаги множество раз, пока ошибка не станет достаточно мала. Одним из ключевых факторов эффективности обучения является выбор правильной функции активации для нейронов. Наиболее популярными являются сигмоидные функции, ReLU (Rectified Linear Unit) и их варианты. Они позволяют придавать модели нелинейность, необходимую для решения сложных задач. Кроме того, существуют различные архитектуры нейронных сетей, адаптированные под конкретные области применения.
Например, сверточные нейронные сети (CNN) отлично подходят для обработки изображений, рекуррентные нейронные сети (RNN) — для анализа последовательностей и текстовых данных, а трансформеры резко повысили качество понимания языков благодаря своей способности к параллельной обработке информации и самообучению внимания. Важным аспектом при обучении нейронных сетей является наличие большого объёма высококачественных данных. Чем разнообразнее и репрезентативнее набор данных, тем лучше сеть сможет обобщать и работать с новыми случаями. Недостаток данных может привести к переобучению — когда модель слишком точно подстраивается под обучающие примеры и плохо работает на новых, не знакомых данных. В результате эффект от обучения снижается.
Помимо теоретической составляющей, реализация нейронных сетей и обратного распространения тесно связана с вычислительными ресурсами. Благодаря развитию мощных графических процессоров (GPU) и специализированных вычислительных архитектур обучение нейронных сетей стало значительно быстрее и масштабируемее. Это позволило применять сложные модели с миллионами параметров и добиваться высоких результатов в задачах реального мира. В заключение стоит подчеркнуть, что нейронные сети являются мощным инструментом, способным решать широкий спектр задач, которые традиционные методы не в силах обработать. Обратное распространение ошибки — фундаментальный алгоритм, который обеспечивает эффективное обучение моделей, позволяя им самостоятельно выявлять сложные закономерности в данных.
Понимание принципов работы нейронных сетей и алгоритмов их обучения является ключом к успешному применению технологий искусственного интеллекта в самых различных сферах — от медицины и науки до промышленности и бизнеса.