Отображение исландских личных имён в пользовательских интерфейсах сильно отличается от стандартных систем, и связано это с уникальной грамматической особенностью — склонением имён по четырём падежам: именительному, винительному, дательному и родительному. Каждому падежу соответствует своя форма имени, и использование неправильной формы воспринимается носителями языка как ошибка, что особенно ощутимо в программных продуктах, которые взаимодействуют с пользователями на исландском языке. Основная сложность для разработчиков заключается в том, что данные с именами обычно хранятся в форме именительного падежа. При интеграции таких имён в предложения, где требуется другой падеж, приходится либо переписывать структуру предложения, чтобы сохранить именительный падеж, либо использовать местоимения вместо имени — оба варианта нежелательны с точки зрения качества и натуральности языка. Ранее для решения этой задачи была написана библиотека на JavaScript, которая позволяет применять падежи к исландским именам, используя лишь их форму в именительном падеже.
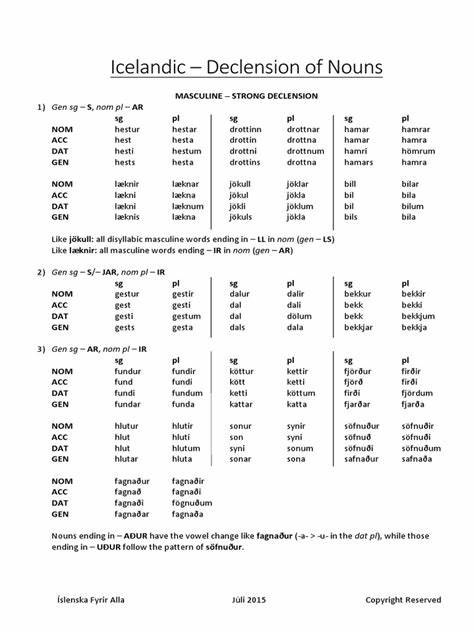
В основе этой библиотеки лежит идея не кодировать правила вручную, а выводить их из большого объёма публичных данных Морфологической базы данных Исландии (DIM), предлагающей обширные сведения о склонении слов и имён. Было принято решение использовать формат K — специализированные CSV-данные, содержащие формы имён в разных падежах. Например, для имени "Guðmundur" доступны формы "Guðmundur" (именительный), "Guðmund" (винительный), "Guðmundi" (дательный), "Guðmundar" (родительный). Такие данные позволяют построить структуру, где каждая форма сопоставлена с соответствующим падежом. Однако объём материала огромен — в базе свыше 7 миллионов записей, и лишь около 3,600 из них относятся к утверждённым личным именам Исландии.
Для фильтрации используется реестр персональных имён, в котором сгруппированы как одобренные, так и отклонённые имена. Выделив лишь утверждённые, можно обеспечить надёжную основу для создания словаря склонений. Наивный вариант реализации функции смены падежа выглядел бы, как поиск конкретной формы имени в массиве форм и возврат соответствующей по индексу падежа. Этот подход работал, но он приводил к слишком большому размеру включаемых данных — около 30 кБ сжатого объёма — и отсутствию поддержки имён, которые не входили в исходный список. Это затрудняло использование библиотеки в условиях ограниченного размера бюджета загрузки веб-приложения.
Для оптимизации было решено использовать метод сжатия данных, основанный на выделении максимально длинного общего префикса у всех форм имени и хранении только суффиксов. Так, для имени "Guðmundur" общий префикс форм — "Guðmund", а суффиксы к падежам представлены как "ur", "", "i", "ar". Сама функция applyCase получает именительный вариант имени, выделяет его префикс, используя длину первого суффикса, и добавляет нужный суффикс для выбранного падежа. Далее была построена хеш-таблица, сопоставляющая имена и их суффиксные схемы. Однако задача решила лишь частично проблему, поскольку при встрече с неучтёнными именами решить их склонение невозможно простым хешированием.
Анализ показал, что имена с похожими окончаниями часто склоняются по схожим шаблонам. Это навело на мысль использовать структуру данных «префиксное дерево» или trie, в которой ключи — имена, записанные в обратном порядке, что удобно для совпадений по суффиксам. Стандартное применение trie предполагает вставку каждого символа как узла дерева. При записи ключей в обратном порядке узлы с общими суффиксами оказываются в одних и тех же частях дерева, что облегчает обнаружение паттернов. Для примера, множество имён, заканчивающихся на "ur", будет иметь общий путь по символам "r", "u" в корне дерева.
Функция поиска (lookup) в таком дереве осуществляет обход по символам ключа с конца и возвращает значение, связанное с соответствующим узлом. Тем не менее, дерево, построенное на множестве имён и их шаблонах склонения, оказывается избыточным, поскольку поддеревья с одинаковыми значениями являются избыточными. Для уменьшения размера реализации была применена процедура сжатия trie путём рекурсивного объединения поддеревьев, все листья которых имеют одинаковое значение. В результате подобные поддеревья заменяются на один узел с соответствующим значением, а дочерние узлы удаляются. Это значительно сокращает количество узлов и, следовательно, объем занимаемой памяти.
Важным аспектом является обработка случаев, когда обнаруживаются неоднозначности. Например, некоторые окончания встречаются у имён, склонение которых отличается. Такие разветвления препятствуют сжатию, так как значение для листьев в поддереве разное. В таких ситуациях trie допускает возвращать значение ближайшего родительского узла с определённым значением, что позволяет прогнозировать склонение для имён, отсутствующих в базе. На практике сжатие trie дало впечатляющее сокращение размеров структуры: с более чем 10 тысяч узлов до около полутора тысяч.
Глубина поиска уменьшилась, и большинство имён было определено по суффиксам длиной 3 или меньше. Это даёт сокращение не только по памяти, но и по времени поиска. Дальнейшее улучшение достигнуто слиянием листовых узлов с одинаковыми значениями, расположенными рядом. Такой подход позволяет уменьшить число листьев почти вдвое, значительно снизив размер конечного trie. Визуальный анализ показал, что для имён с частыми окончаниями степень регулярности склонения очень высока, что усиливает эффективность применяемой компрессии.
В итоге финальный размер сериализованного сжатого trie составил всего 3.27 кБ в сжатом виде, что позволило встроить библиотеку в веб-приложения с минимальным влиянием на размер итогового пакета. Таким образом, был достигнут баланс между степенью точности склонений и ограничением по размеру. Практическое тестирование показало, что сжатый trie сгенерировал корректные формы склонения в 74% случаев для имен, отсутствовавших в исходных данных. Еще 12% случаев корректно возвращали исходное имя без изменений, а остальные ошибочные случаи встречались довольно редко.
Для более распространённых имён с отсутствующими данными точность повышалась, а общий процент ошибок снижался до порядка 21% для тех же тестов. Для организаций с высокими требованиями к грамматической точности, таких как судебные системы, была выпущена более строгая версия библиотеки, которая отказывается склонять имена за пределами утверждённого списка. Эта версия весит приблизительно 15 кБ в сжатом виде, но гарантирует абсолютную точность склонения, что критично для официальных документов. Важным аспектом разработки было сохранение открытости и возможности дальнейшего расширения. Открытие данных и инструментов, таких как DIM и реестр имён, позволило построить надежный инструмент на основе фактической грамматической информации, а алгоритмы trie и последовательно внедряемые техники сжатия сделали библиотеку удобной для внедрения в разные проекты.
Опыт решения проблемы склонения исландских имён демонстрирует эффективное применение структур данных и алгоритмов для минимизации объёма приложений при сохранении функциональности и качества. Методология может быть применена и к другим языкам с богатой грамматикой, где склонение и словоизменение играют ключевую роль. Такой подход открывает путь для улучшения локализации, создания более естественных пользовательских интерфейсов и повышения удовлетворённости пользователей за счёт точного и корректного отображения имён в контексте языка. Автор проекта продолжает работу над улучшением рекомендованных моделей и расширяет возможности библиотеки, ориентируясь на баланс между размером, производительностью и точностью, благодаря чему решения остаются актуальными и удобными для разработчиков по всему миру.