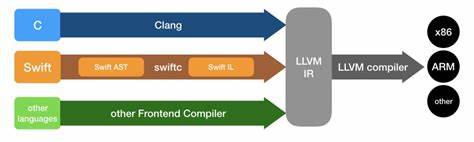
LLVM позиционируется как современная и эффективная платформа для компиляции, обещая высокопроизводительные low-level реализации и продвинутую оптимизацию. Однако многочисленные практические тесты и анализ реального машинного кода показывают, что за громкими заявлениями часто скрываются серьезные недостатки, влияющие на качество и скорость генерируемых программ, особенно в критических областях, таких как работа с большими числами и многобитными операциями. Ключевым направлением критики становится runtime-библиотека compiler-rt, в которой реализованы базовые операции над целочисленными типами, включая 128-битное деление и умножение с проверкой переполнения. Несмотря на заявления о наличии в библиотеке высокотехнологичных и оптимизированных реализаций, в действительности код часто не только не оптимален, но и иногда хуже, чем в более старых компиляторах вроде GCC. Примеры функций __ucmpdi2() и __popcountti2() демонстрируют неэффективные и архаичные алгоритмы, которые тормозят оптимизатор LLVM и ведут к ухудшению производительности конечных программ.
Особое внимание уделяется нарушению соглашений о вызовах под Microsoft ABI. В тестах показано, что LLVM генерирует такую машинную инструкцию, в которой многословные агрегации передаются и возвращаются в регистрах несоответствующим образом, создавая несовместимость с Visual C++ и фактор риска нестабильной работы при смешивании кода, скомпилированного разными компиляторами. Это сильный удар по утверждениям LLVM о полной совместимости с MSVC и обусловливает необходимость либо обходных решений, либо отказа от использования LLVM в определенных критичных проектах под Windows. Производительность 128-битного деления и умножения с проверкой переполнения оставляет желать лучшего. Измерения на современных процессорах AMD Ryzen 5 3600, EPYC 7262 и Intel Core i5-6600 показывают, что выполнение этих операций в LLVM может быть в 9–17 раз медленнее, чем в GCC.
Это связано с тем, что LLVM часто вызывает нецелесообразные цепочки функций, затратно реализует общие операции через более сложные вызовы и не использует эффективные аппаратные инструкции, где это возможно. Код для 64-битного деления и умножения ещё хуже — генерация избыточных инструкций, дублирование вычислений остатка и частного, многократные вызовы вспомогательных функций вместо использования одной оптимальной, накладные копирования и операции с регистрами приводят к значительным потерям по времени исполнения. Что касается оптимизации, LLVM проявляет слабость в ряде распространенных функций низкого уровня: абсолютные значения, сравнения, сдвиги, ротации и операции над битами реализованы с использованием неэффективных паттернов. В порой предпочтительных вариантах отсутствует разумное удаление лишнего кода, устранение условных переходов при возможности, и генерация более коротких последовательностей машинных инструкций, что негативно отражается на скорости и потреблении ресурсов. Немаловажным минусом выступает неумелое обращение с ресурсами в Windows.
Примером служит дублирование огромных исполняемых файлов в стандартных установщиках LLVM, занимающих сотни мегабайт при одинаковом содержимом, что говорит о непроработанном управлении хранилищем и игнорировании возможностей NTFS вроде хардлинков. Это приводит к неоправданному расходу места на диске и замедляет процесс обновления. В теоретическом плане также вызывает сомнения позиция по кросс-компиляции. Несмотря на официальные заявления о способности LLVM компилировать код целевых архитектур независимо от платформы сборки, на практике невозможность связывания объектных файлов смешанных архитектур с одних и тех же пакетов (32-битных для 64-битных и наоборот) ухудшает гибкость и заставляет устанавливать большие параллельные пакеты, что дополнительно нагружает систему и усложняет настройку среды разработки. В целом, анализ показывает, что LLVM нередко не подтверждает свои амбициозные заявления.
Автоматическая генерация машинного кода страдает от неэффективных шаблонов, неполной или некорректной поддержки ABI, а runtime-библиотеки содержат устаревшие и плохо оптимизированные реализации критически важных функций. Это приводит к ухудшению производительности, снижению совместимости и увеличению расходов ресурсов. Для разработчиков, использующих LLVM, особенно в высокопроизводительных приложениях и под управлением Windows, важно знать о таких ограничениях. При выборе компилятора стоит провести собственные испытания и учитывать реальное качество конечного кода, а не только декларации производителя. Многие операции целочисленной арифметики большой размерности никак не оптимизированы, что может стать узким местом при построении сложных систем.
Ситуация требует дальнейших усилий команды разработчиков LLVM по улучшению runtime-библиотек, более тщательного соответствия ABI, а также внедрения продвинутых оптимизаций на уровне генерации кода, например, с учетом суперскалярной архитектуры современных процессоров. Перенимать опыт из проверенных временем решений и взаимодействовать с сообществом открытого ПО станет хорошим шагом для повышения качества проекта. Подытоживая, можно отметить, что LLVM, несмотря на все достоинства и инновационность, пока демонстрирует серьезные пробелы в реализации и оптимизации низкоуровневых компонентов. Пользователям рекомендуется внимательно анализировать особенности генерации кода, проводить сравнения с альтернативами и осознавать, что для некоторых задач GCC или другие компиляторы всё ещё могут оставаться более подходящими в плане эффективности и совместимости.