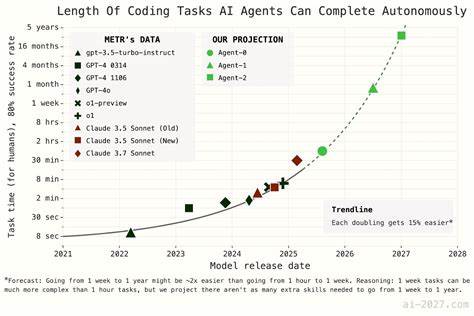
Прогнозирование будущего искусственного интеллекта – особенно в отношении сроков его достижения суперчеловеческого уровня – всегда сопровождалось многочисленными вызовами и спорами. Одним из знаковых проектов в этой области стала работа AI 2027, в которой группа исследователей попыталась не только описать возможный сценарий развития ИИ к 2027 году, но и подкрепить его программным моделированием и данными. Несмотря на широчайшее распространение, вирусность и внимание ведущих экспертов, модели AI 2027 подверглись масштабной и глубокоуважаемой критике, указывающей на серьезные недостатки как в их построении, так и в выводах. Рассмотрение и анализ этих проблем важны для понимания сложностей прогнозирования и для формирования реалистичных ожиданий относительно будущего ИИ. Основополагающим элементом AI 2027 была попытка моделирования временных горизонтов достижений искусственного интеллекта, который так называемый "суперчеловеческий кодер" (SC), способен выполнять задачи AI-исследователя в 30 раз быстрее и дешевле человека.
Для этого использовались данные из отчёта METR, в котором анализировалось, как ИИ справляется с реальными R&D-задачами и как меняется со временем "временной горизонт" – то есть время, за которое AI с заданной вероятностью (80%) способен выполнить задачу определённой сложности. Однако базовая структура прогнозных моделей, особенно метода временного горизонта, вызывает немало вопросов. В основе заложены две ключевые модели роста – "экспоненциальная" и "суперэкспоненциальная" кривая, причем обе несут в себе существенные методологические спорности. Экспоненциальная модель предполагает стабильное удвоение времени достижения новых уровней навыков ИИ, однако она игнорирует неопределенность в текущих параметрах, таких как исходное значение и скорость удвоения. Это создаёт ложную уверенность в тренде, который на самом деле может меняться из-за временных колебаний или артефактов передачи данных.
Гораздо более спорной оказалась суперэкспоненциальная кривая. В AI 2027 её описывают так: время удвоения навыков сокращается на 10% с каждым следующим удвоением. По сути, каждая ступенька прогресса даётся легче предыдущей. Несмотря на то, что этот параметр критичен для итоговой модели, в оригинальной версии ему не придали должного внимания и не заложили варьируемость. Главная проблема в том, что формула приводит к математическому краху модели, поскольку приносит в итоге бесконечные или комплексные (воображаемые) значения, что физически не имеет смысла.
Такой вид кривой, хоть и может служить приближением в краткосрочной перспективе, становится ошибочным в долгосрочном прогнозе. Концептуальные аргументы, которыми AI 2027 обосновывает выбор этих кривых, выглядят слабо и недостаточно подкреплены эмпирическими данными. Например, тезис о том, что сокращение задержки между внутренним созданием модели и её публичным релизом ведет к ускорению прогресса, противоречит логике: если время с момента завершения обучения до выпуска уменьшается, реальный прогресс происходит медленнее, чем кажется. Также утверждения о том, что задачи более долгосрочные (недели, месяцы, годы) становятся «легче» по сравнению с более короткими, не подкреплены конкретными метриками и скорее вызывают вопросы о применимости для ИИ, поскольку на данный момент ИИ лучше справляется с задачами, имеющими большое количество обучающего материала и короткие инструкции. Важным аспектом модели является концепция «промежуточных ускорений» (intermediate speedups), которая учитывает, что наличие ИИ в исследовательских процессах ускорит разработку дальнейших ИИ.
При детальном разборе оказалось, что математическая реализация этой идеи в модели не совпадает с предположениями о текущем ускорении – при попытках обратного прогноза (backcast) модель выдавала слишком большой разброс в скорости развития, не совпадая с реальными наблюдаемыми темпами ускорения развития ИИ. Вторая модель, так называемая «benchmark and gaps», которая позиционировалась авторами как основная и более точная, оказалась ещё более спорной. В ней используется метрика Re-bench, оцененная на основе логистической кривой обучения моделей ИИ, с прогнозом насыщения производительности выше, чем у лучших людей. Однако этот прогноз построен на предположении, а не на данных – сама логистическая кривая в большинстве случаев не соотносится с наблюдаемыми показателями и была исключена из реального кода моделей. Таким образом, ключевой «референсный» компонент модели, на котором строятся дальнейшие вычисления, на самом деле отсутствует или формален, что ставит под сомнение надежность всего прогноза.
Кроме того, для параметров моделирования во второй методологии используются произвольные оценки, без тщательного обоснования или эмпирической валидации. Например, предполагаемая скорость удвоения и время достижения порогов меняются искусственно для получения нужного результата. Это создает впечатление, что более сложная модель не добавляет объективной точности, а лишь нагружает результаты неэффективными и не подтвержденными параметрами. Обновленная версия модели, представленная в 2025 году одним из авторов, хоть и включила ряд улучшений: учёт неопределённости параметров, более детальное описание влияния различных факторов и демонстрацию влияния разных предположений, всё же не разрешила главных проблем. Новшества в модели лишь отодвинули прогнозируемые даты появления суперчеловеческих кодеров на пару лет вперёд, но по-прежнему оставили нерешёнными проблемы с выбором функций роста и обоснованием параметров.
Экспертные критики подчёркивают, что при столь ограниченных и неполных данных, а также крайне сложных и изменяющихся влияющих факторах, попытки построить точные годовые прогнозы выглядят слишком оптимистично. История технологических прорывов показывает, что прогресс часто бывает скачкообразным и непредсказуемым, а многочисленные внешние факторы – от экономики до политики – оказывают существенное влияние, зачастую неожиданное. AI 2027 иллюстрирует распространённый вызов в области прогнозирования ИИ: как сочетать реальную динамику быстро развивающейся технологии с ограниченной и неоднородной информацией, как оценить новые качества и стратегии, появляющиеся в ИИ, не сводя всё к механическим математическим зависимостям. Авторы, имея доступ к сложным методам и экспертным знаниям, в итоге построили модели, которые по ряду критических аспектов либо не соответствуют историческим данным, либо не имеют чёткой концептуальной поддержки. Подобные случаи учат, что любые прогнозы базируются на предположениях, которые должны являться прозрачными, доказуемыми и воспроизводимыми.
Прогнозы с высокой степенью неопределённости требуют большой осторожности при их восприятии и использовании в стратегическом планировании. Внезапное принятие моделей типа AI 2027 как «истинных» может приводить к преждевременным, а иногда и контрпродуктивным решениям. Более того, присутствует опасность, что широкое распространение данных моделей формирует ложное чувство уверенности и сужает взгляд экспертов и менеджеров на реалии развития ИИ, не учитывая возможные альтернативные сценарии, как более быстрые, так и более медленные. В действительности диапазон возможностей куда шире и множество факторов, таких как ограничения вычислительных ресурсов, регулирование, социальное восприятие и новые методологии, могут кардинально влиять на темпы прогресса. Таким образом, глубокий анализ AI 2027 демонстрирует необходимость развития более комплексных и обоснованных подходов к прогнозированию развития искусственного интеллекта.