Современные технологии искусственного интеллекта продолжают стремительно развиваться, особенно в сфере мультимодального понимания, где модели объединяют визуальную и текстовую информацию для более сложного анализа и генерации данных. Одним из наиболее перспективных направлений в этой области становится концепция машинного ментального изображения, которая открывает новые горизонты для улучшения способности моделей рассуждать, сочетая внутренние визуальные представления с языковыми конструкциями. Эта статья посвящена глубокому исследованию технологии машинного ментального изображения и тому, каким образом латентные визуальные токены помогают моделям искусственного интеллекта достигать качественно нового уровня мультимодального мышления. Традиционные модели зрения и языка (Vision-Language Models, VLMs) показали впечатляющие результаты в задачах понимания и генерации текста на основе визуальной информации и наоборот. Однако их основной недостаток заключается в том, что они вынуждены переводить все визуальное понимание в текстовую форму.
Такой подход ограничивает потенциал моделей, особенно в задачах, где требуется более глубокое, интуитивное визуальное мышление, напоминающее человеческое внутреннее воображение. В ответ на эту проблему последовали попытки научить модели генерировать явные изображения в процессе рассуждений. Тем не менее, такой путь сопряжён с серьёзными сложностями из-за высокой вычислительной нагрузки и необходимости масштабного предварительного обучения на генерацию изображений, что негативно сказывается на эффективности решения логических и когнитивных задач. Идея машинного ментального изображения, предложенная научной группой во главе с Зеяном Янгом и его соавторами, вдохновлена тем, как человек оперирует внутренними визуальными образами во время размышлений. Человеческий разум способен создавать, модифицировать и использовать мысленные образы, которые существенно упрощают понимание сложных концепций и принятие решений.
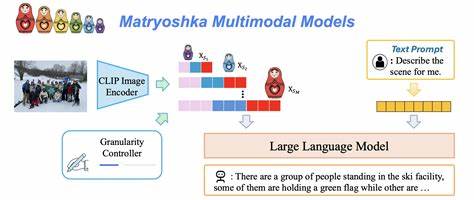
Экспериментируя с моделями глубокого обучения, исследователи разработали инновационную архитектуру под названием Mirage, обеспечивающую внутреннюю визуализацию без необходимости всякий раз генерировать явные изображения. Ключевая технология Mirage базируется на использовании латентных визуальных токенов — своеобразных скрытых представлений, которые модель может интегрировать вместе с текстовыми токенами при формировании ответа. Таким образом, модель ведёт параллельную мультимодальную цепочку рассуждений, свободную от традиционного кодирования исключительно в текстовой форме, и без затратных операций рендеринга пиксельных изображений. Более того, на старте обучения latent visual tokens подвергаются дистилляции с помощью эталонных визуальных эмбеддингов, что позволяет обеспечить адекватное соответствие внутреннего представления реальным визуальным сценам. Затем, в процессе перехода к чисто текстовой супервизии, модель учится адаптировать свою визуальную траекторию так, чтобы она максимально способствовала выполнению конкретной задачи.
Благодаря применению методов усиленного обучения, архитектура Mirage в итоге вполне успешно интегрирует мультисенсорные знания и на уровне стратегии решает задачи, которые требуют комплексного анализа данных и формирования выводов, их объединяющих. Этот подход позволяет модели реализовать так называемое машинное ментальное изображение — симбиоз визуального и текстового мышления, где внутренние визуальные символы служат инструментом упрощения работы с информацией, схожим по назначению с человеческой способностью визуализировать проблемы. Практическое применение подобной технологии оказалось впечатляющим. Тесты на различных независимых бенчмарках подтверждают, что Mirage превосходит традиционные модели в режиме только текстового вывода, особенно в задачах, где визуальная интуиция и межмодальное связывание информации дают конкурентное преимущество. Речь идёт о ситуациях, требующих понимания сложных взаимодействий объектов, пространственных отношений, а также абстрактного представления визуальных концепций.
Mirage демонстрирует особую устойчивость в условиях ограниченной информации, где способности к ментальному моделированию играют решающую роль. Стоит отметить, что инновационный подход, предложенный в Mirage, меняет само представление о том, как создаётся и используется знание в системах искусственного интеллекта. Помимо повышения эффективности и качества мультимодального понимания, он открывает перспективы для более естественных и гибких интерфейсов взаимодействия с машинами. Например, будущие ассистенты и роботы смогут использовать внутреннее визуальное мышление для более точного и понятного объяснения собственных действий и решений, что значительно повысит доверие пользователей и расширит области применения ИИ. В контексте развития технологий машинного обучения, концепция машинного ментального изображения представляет собой важный шаг на пути к созданию систем, способных не просто анализировать данные, но и творчески мыслить, моделировать и адаптироваться.
Возникает возможность построения ИИ, которые не ограничены простым воспроизведением информации, а обладают внутренними средствами визуализации, позволяющими им оперировать абстракциями похожим образом, как это делает человеческий мозг. С учётом динамического развития области, перспективы дальнейших исследований в направлении латентных визуальных токенов и метода ментального изображения выглядят крайне многообещающими. Комбинация различных методик — от трансформеров и самообучающихся агентов до новых форм усиленного обучения и самоорганизации — может привести к качественному прорыву в понимании и усложнении взаимосвязей между зрительным восприятием и языковой обработкой в искусственном интеллекте. В заключение, технология машинного ментального изображения с применением латентных визуальных токенов открывает новый уровень мультимодального мышления для моделей искусственного интеллекта. Mirage демонстрирует, что отказ от явной генерации изображений в пользу внутренней визуальной репрезентации не только повышает эффективность обучения, но и расширяет функциональные возможности систем, делая их более адаптивными и интеллектуальными.
Это, без сомнения, повлияет на будущее разработки интеллектуальных систем, приближая их к естественным способностям человеческого мышления и воплощая идеи взаимного синтеза визуального и лингвистического восприятия в единую целостную модель.