В современном мире искусственный интеллект занимает центральное место в преобразовании того, как мы получаем и обрабатываем информацию. Технологии, такие как большие языковые модели (LLM), обещают радикально изменить доступ к знаниям, делая их более открытыми и доступными, однако за этим прогрессом скрывается сложная сеть вопросов насчет того, кто и как контролирует эти данные, кто формирует цифровую инфраструктуру и к каким последствиям это приводит для общества в целом. На первый взгляд, кажется, что появление генеративного искусственного интеллекта открывает новую эру демократизации знаний. Инструменты, например ChatGPT или Claude, предоставляют возможность синтезировать и анализировать огромные объемы информации за считанные секунды. Это создает ощущение, что знания перестали быть прерогативой вузовских институтов или крупных компаний, теперь чтобы получить ценную информацию, достаточно лишь уметь правильно сформулировать вопрос.
Тем не менее, этот относительный доступ не гарантирует свободу или истинную демократизацию. За красотой интерфейса часто скрывается инфраструктура, которая находится под контролем приватных корпораций, использующих закрытые модели обучения и извлекающих выгоду из данных пользователей без прозрачности и согласия. Модель генеративного ИИ как правило не является абсолютно открытой и нейтральной. Например, даже так называемые «открытые» модели, как DeepSeek, выдающие общедоступные веса модели, при этом сохраняют закрытый код обучения. Более того, технические требования для эффективного использования таких моделей, включая мощные вычислительные ресурсы и глубокие знания машинного обучения, существенно ограничивают круг реальных пользователей.
В этом заключается существенная проблема — теоретическая открытость кода и моделей не является синонимом доступности и использования во благо общества. Техническая и финансовая инфраструктура, необходимая для запуска и интеграции сложных моделей ИИ, распределена крайне неравномерно. Это подрывает изначальную идею открытого программного обеспечения, поскольку лишь немногие крупные организации или хорошо финансируемые специалисты могут позволить себе использовать эти инструменты с максимальной эффективностью. Такая ситуация ведет к централизации контроля над знаниями и технологиями в руках ограниченной группы, повторяя старые паттерны власти и исключая большую часть общества из участия в строительстве цифрового будущего. Искусственный интеллект и инфраструктура, лежащая в его основе, никогда не бывают абсолютно нейтральными.
Мы часто слышим утверждение, что модели ИИ «просто отражают интернет», однако это не учитывает тот факт, что данные тщательно отбираются, модели настраиваются на определённые задачи и лица, принимающие решения об их применении, несут ответственность за включение или исключение тех или иных точек зрения. В результате алгоритмы могут непреднамеренно маргинализировать неклассические источники знаний и укреплять уже существующие социальные предубеждения. Эта скрытая власть над созданием и распространением знаний особенно опасна, когда инфраструктура ИИ остается непрозрачной и неподотчетной обществу. Она может усиливать доминирующие нарративы и создавать условия для контроля над общественным сознанием. Вместе с тем появляются разнообразные движения и инициативы, направленные на сопротивление таким тенденциям.
Исследователи, активисты и технологи предлагают альтернативные модели этического управления искусственным интеллектом, концепции инклюзивного дизайна и более открытых данных. Все эти усилия призваны показать, что ИИ — это не судьба, а результат проектных решений, определяющих, кто получает выгоду, кто виден в информационном пространстве и кто влияет на распределение власти. Необходимо также рассмотреть очень важный аспект сбора и контроля данных, на которых обучаются современные модели. Часто для тренировки ИИ используются огромные объемы информации, собранной с открытого интернета, приватных платформ и даже взаимодействий с пользователями без их осознанного согласия. В процессе использования чат-ботов и других сервисов пользователи генерируют ценную поведенческую информацию, которая аккумулируется и становится коммерческим активом компании.
В отличие от академических наборов данных, используемых для исследований и доступных для изучения обществом, такие данные часто скрыты за коммерческой тайной и юридическими соглашениями о неразглашении. Это приводит к новой форме «экранирования» знаний, когда общедоступная информация и пользовательский вклад превращаются в частную собственность. Такая практика усиливает асимметрию сил и может способствовать развитию норм наблюдения, а также снижать возможности для построения общественной цифровой инфраструктуры, основанной на принципах подотчетности и согласия. Без соответствующих юридических и технических гарантий подобная динамика может привести к ухудшению общественного доверия и сужению пространства для открытого диалога. В условиях наводнения генеративным контентом критически важным становится умение контекстуализировать, верифицировать и управлять знаниями.
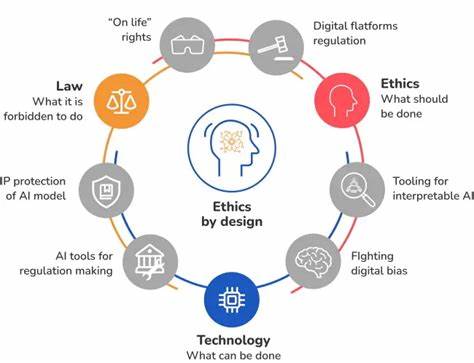
Для этого необходима инфраструктура, построенная на принципах этичности, открытости и участия. Без протоколов, которые обеспечивают прозрачное происхождение данных, децентрализованные идентификаторы и принципы управления, знания, получаемые с помощью ИИ, остаются уязвимыми для манипуляций и приватизации. Международные организации, такие как World Wide Web Consortium (W3C) и Decentralized Identity Foundation (DIF), разрабатывают стандарты и модели, направленные на усиление суверенитета данных и децентрализацию контроля. В их видении управление идентичностью, правами и данными переходит от крупных платформ к самим пользователям и сообществам. Такой подход предлагает интеграцию ИИ в системы, где главенствует человеческий агентный контроль, а не безликая автоматизация.
В эпоху искусственного интеллекта протоколы и стандарты приобретают еще большее значение, потому что они служат каркасом для подотчетного и ценностно ориентированного управления технологиями. Без них мы рискуем повторить негативные явления, присущие раннему интернету: централизацию власти, непрозрачность механизмов и социальное отчуждение. Выдающиеся мыслители, например Элинор Остром, а также движения вроде RadicalxChange, обращают внимание на важность совместного управления и прозрачных правил, благодаря которым пользователи получают право участвовать в принятии решений и формировании будущего технологий. Скорость развития технологий, масштаб и эффективность давно считаются ключевыми показателями прогресса. Однако появление ИИ предлагает задуматься о новых критериях — доверии, достоинстве и глубоком уважении к многообразию человеческого опыта.
Будущее искусственного интеллекта не определяется лишь его функциональными возможностями, оно зависит от того, как мы будем формировать этические нормы, дизайн и политику, лежащие в основе этих технологий. Если мы стремимся к будущему, где знания действительно становятся силой освободительной, нам необходимо создавать инфраструктуру, которая отражает общественные ценности и работает в интересах общества. Без этики и продуманного дизайна масштабный интеллект превращается не в инструмент свободы, а в средство новых форм контроля. Поэтому важно понимать, что искусственный интеллект — это не просто технологический феномен, а прежде всего политический и социальный вызов, требующий активного участия всех слоев общества в формировании новых норм и правил.