В современном мире информационных технологий многие компании и инженеры сталкиваются с необходимостью создавать и поддерживать высокоэффективные распределённые системы, которые способны обрабатывать постоянно меняющийся поток запросов. Несмотря на активное обсуждение таких терминов как масштабируемость и производительность, часто они воспринимаются как синонимы, что является значительным заблуждением, способным привести к неправильным решениям в архитектуре систем. Чтобы построить устойчивую и эффективно работающую инфраструктуру, важно чётко понимать, что масштабируемость — это не то же самое, что производительность. Производительность в контексте распределённых систем традиционно измеряется двумя основными показателями: латентностью и пропускной способностью. Латентность — это время, необходимое системе для обработки одного запроса в среднем, а пропускная способность — количество запросов, которые система способна обработать за единицу времени.
Хотя уменьшение латентности интуитивно кажется идеальным способом улучшения производительности, на практике сделать это значительно сложнее, чем увеличить пропускную способность. Снижение латентности сталкивается с серьёзными ограничениями и законом убывающей отдачи, что вызвано физическими, сетевыми и вычислительными факторами. Наоборот, повышение пропускной способности обычно достигается добавлением новых вычислительных ресурсов, что проще реализовать, но зачастую сопровождается увеличением латентности. Именно поэтому современные распределённые системы склонны к оптимизации именно пропускной способности, позволяя обрабатывать больше запросов вместе с некоторым компромиссом по времени отклика. Для лучшего понимания разницы между масштабируемостью и производительностью полезно обратиться к простейшей модели, состоящей из двух основных элементов: вычислительных узлов (коробок) и задач (джобов).
В данной модели каждая задача — это абстракция, описывающая работу, которую система должна выполнить, будь то обработка HTTP-запроса, транзакция или запрос к базе данных. Вычислительный узел представляет собой виртуальную машину, контейнер или процесс, способный параллельно обрабатывать задачи. Простые правила этой моделизации гласят, что каждая задача занимает фиксированное время для выполнения (латентность), каждый вычислительный узел работает с одинаковой скоростью и способен выполнять только одну задачу одновременно. Несмотря на то, что эти упрощения не отражают полной картины реальных систем, они отлично подходят для демонстрации основных принципов масштабируемости и производительности. Если система состоит из одного вычислительного узла, её пропускная способность прямо связана с латентностью и вычисляется как обратная величина латентности.
Однако система из одного узла едва ли может называться распределённой. При добавлении множества узлов пропускная способность увеличивается пропорционально количеству узлов, так как каждый новый узел может одновременно обрабатывать дополнительные задачи. Именно здесь проявляется ключевое различие между масштабируемостью и производительностью: при постоянной латентности мы можем улучшать пропускную способность, просто увеличивая количество узлов. Однако эту гибкость невозможно считать бесплатной: каждый вычислительный узел требует вложений, что увеличивает затраты на инфраструктуру. Показатель стоимости тесно связан с пропускной способностью, поскольку для обработки большего количества задач необходимы дополнительные ресурсы, что выражается в росте затрат.
Отсюда следует важный вывод для бизнеса — увеличение производительности через увеличение масштабируемости требует дополнительных финансовых вливаний. Одна из важных характеристик распределённой системы — это изменчивость нагрузки либо скорости прихода задач (JobRate). В реальности количество запросов может как резко увеличиваться, так и снижаться в течение коротких периодов времени. Способность системы адаптироваться к этим изменениям — один из главных признаков её масштабируемости. Если пропускная способность системы меньше текущей нагрузки, то часть запросов не будет обработана, что в большинстве случаев приводит к потере данных и негативно сказывается на пользовательском опыте.
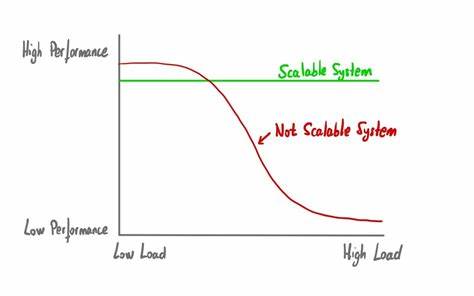
Такие пропуски называются ошибками и считаются критическими сбоями. С другой стороны, если пропускная способность системы существенно превышает нагрузку, это приводит к низкой загрузке ресурсов, а значит расходам на оборудование и обслуживание, не приносящим реальной отдачи. Значимым показателем становится коэффициент загрузки (utilization), который выражает отношение нагрузки к пропускной способности. Значение близкое к 1 означает оптимальное использование ресурсов, тогда как значения ниже показывают недогруженность, а выше единицы — перегруженность и потерю задач. Оптимальная система — это та, которая поддерживает стабильный уровень загрузки независимо от изменений нагрузки.
Для этого пропускная способность должна динамически изменяться, что возможно только при наличии механизма быстрого создания и удаления вычислительных узлов. Способность изменять количество активных узлов в зависимости от текущей необходимости — и есть сама суть масштабируемости. На практике данный процесс не всегда прост. Сложность заключается не только в эффективном управлении ресурсами, но и в координации работы множества компонентов, которые по-разному реагируют на изменение нагрузки и масштабируются неравномерно. Неудивительно, что многие компании предпочитают использовать облачные решения и серверные платформы, которые обеспечивают необходимый уровень масштабируемости за счёт экономии на операционных издержках и автоматизации процессов.
Интересно, что серверныеless-платформы, предоставляющие масштабируемость по требованию, могут обходиться значительно дороже в расчёте на единицу производительности. Исследования показывают, что затраты на серверлессы могут превышать те, что связаны с виртуальными машинами, в 100 раз при сопоставимой пропускной способности. Тем не менее компании выбирают такую модель, отдавая приоритет гибкости и удобству масштабирования, способным покрыть резкие скачки нагрузки, которые традиционные системы могли бы не выдержать. Таким образом, масштабируемость — это способность менять пропускную способность системы, адаптируясь под изменяющуюся нагрузку, тогда как производительность — это показатель самой пропускной способности и латентности без учёта динамики нагрузки и изменений ресурсов. Часто в разговорах о компаниях, совершенствующих свои IT-системы, под улучшением масштабируемости понимают просто увеличение скорости работы, однако это лишь одна из сторон медали.