В последние годы тема искусственного интеллекта стала центральной в дискуссиях о будущем технологий, экономики и общества. В этом контексте проект AI2027 привлёк большое внимание благодаря своей смелой гипотезе о том, что уже к 2027 году может наступить эпоха суперинтеллекта, способного в течение короткого времени автоматизировать огромные сегменты экономики. Однако, несмотря на внешнюю убедительность и большое количество исследовательских материалов, представленных авторами AI2027, внутри модели и её прогнозов скрывается ряд существенных проблем, которые вызывают серьёзное сомнение в достоверности предсказанных сроков. В данном подробном рассмотрении мы разберём ключевые аспекты, от которых зависит качество и надёжность временных прогнозов AI2027, и укажем на их критические слабости. Одним из основополагающих элементов модели AI2027 является концепция «временных горизонтов» (time horizons) — метрики, отражающей время, за которое ИИ способен выполнить задачи на уровне, сопоставимом с человеком, и с заданной вероятностью успеха.
Исходя из анализа роста этой метрики по данным внешних исследований, например отчёта METR, авторы AI2027 пытаются спрогнозировать, когда машины смогут превзойти человека в сфере разработки ИИ. Однако уже здесь начинается цепочка проблем. Во-первых, модель подразделяет прогноз на два возможных сценария роста времени: экспоненциальный и сверхэкспоненциальный, при этом каждой кривой отводится примерно по 40% вероятности. Но выбранная форма сверхэкспоненциального роста вызывает значительные вопросы. Она предполагает, что каждое последующее удвоение «временного горизонта» происходит быстрее на фиксированный процент (например, на 10%), что математически ведёт к точке бесконечности за конечный промежуток времени — что является нелогичным с точки зрения реального прогресса.
Это приводит к абсурдным результатам, например, отрицательным или комплексным значениям показателя через несколько лет, что невозможно трактовать физически или практично. Некорректность и сугубо эмпирическая природа выбранной кривой, а также отсутствие у неё серьёзного концептуального обоснования, существенно снижают доверие к таким прогнозам. Во-вторых, параметры модели, включая исходные значения «временного горизонта» и скорость его роста, зачастую принимаются без учёта неопределённости или на основе субъективных оценок. Это особенно критично, поскольку данные METR ещё не прошли полноценную рецензию и могут содержать систематические ошибки, например из-за сравнения ИИ с неэкспертами среди людей, а не с ведущими специалистами отрасли. Кроме того, недавно наблюдаемый ускоренный рост производительности ИИ в данных METR мог быть кратковременным всплеском, а не устойчивым трендом — однако в модели AI2027 это не всегда корректно учитывается.
Ещё одной неочевидной проблемой является неправильное понимание роли промежуточных ускорений (intermediate speedups), которые рассматриваются как фактор ускорения разработки ИИ за счёт автоматизации самой исследовательской деятельности. Модель использует сложные формулы для вычисления текущей и будущей скорости прогресса, но при обратном прогнозировании (backcast) получаются крайне спорные значения, не согласующиеся с реально наблюдаемыми темпами развития за последние годы. Другими словами, модель завышает эффект ускорения, искажая картину реального научного прогресса. Описанные проблемы усугубляются в более сложной, предпочитаемой авторами AI2027 модели «benchmarks and gaps», которая должна опираться на оценки предельных результатов ИИ на эталонных тестах (например, Re-bench) и дополнительные параметры, отражающие сложность внедрения и развития технологий. Однако реализация этой модели также вызывает серьёзные вопросы.
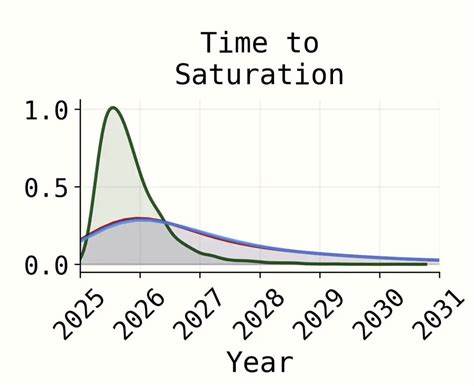
Основная претензия — использование логистической функции для прогнозирования насыщения на Re-bench, где авторы фактически задают верхнюю границу производительности субъективно, не подтверждая её объективными данными. При этом реальный код, лежащий в основе расчётов, игнорирует эту аппроксимацию и вместо неё использует интуитивные предположения о сроках достижения «насыщения», что создаёт диссонанс между публичными заявлениями и реальными методами моделирования. Помимо технических недостатков модели, критика AI2027 касается коммуникации и презентации результатов. Авторы часто представляют упрощённые и визуально привлекательные графики, которые не отражают полноту или надёжность исходных моделей. Например, широко обсуждаемый график прогресса «сверхчеловеческого программиста» не является результатом полной модели, а представляет её резко упрощённую версию без интеграции ключевых факторов, что создаёт впечатление большей точности и обоснованности предположений, чем есть на самом деле.
Это вызывает обеспокоенность относительно того, как подобные представления могут вводить в заблуждение читателей и влиять на общественные или политические решения. Несмотря на обоснованную критику, стоит отметить, что авторы AI2027 выразили готовность к диалогу и признали ряд ошибок и недочётов, планируя улучшить документацию и модель в будущих обновлениях. Тем не менее фундаментальные вопросы о выборе параметров, методологии и концептуальной обоснованности коррекции временных шкал остаются нерешёнными. Разнообразие альтернативных подходов, каждый из которых может быть обоснован аргументами и успешно описывать часть исторических данных, показывает, что прогнозирование темпов достижения суперинтеллекта остаётся задачей крайне высокой сложности и неопределённости. Этот феномен усугубляется нехваткой долгосрочных эмпирических данных, высокой чувствительностью моделей к параметрам и полной неопределённостью в области возможных технологических прорывов.