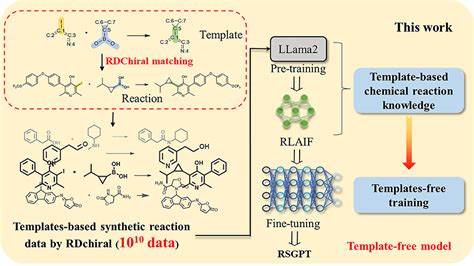
Ретросинтез — важный этап в органическом синтезе, который позволяет определять последовательность химических реакций, приводящих к получению целевого молекулы из доступных исходных компонентов. Традиционные методы ретросинтеза опираются на знания опытных химиков и часто требуют значительных временных и интеллектуальных затрат. В последние годы наблюдается стремительное развитие искусственного интеллекта, особенно глубокого обучения, который открывает новые горизонты в автоматизации и ускорении процесса синтеза. Одним из значимых достижений в этой области стала разработка модели RSGPT — генеративного трансформера, специально обученного для планирования ретросинтеза на основе огромного объёма данных. RSGPT базируется на архитектуре трансформера и вдохновлён стратегиями крупных языковых моделей, таких как LLaMA2.
Основная сложность при создании эффективной модели для ретросинтеза заключается в дефиците обучающих данных: реальных химических реакций доступно лишь порядка миллионов, что недостаточно для обучения масштабных моделей. Для решения этой проблемы была применена инновационная методика генерации синтетических данных с использованием шаблонно-ориентированного алгоритма RDChiral. В результате появилась база, включающая около 10 миллиардов реакций, значительно расширяющая химическое пространство и разнообразие реакций, доступных для обучения. Процесс генерации синтетических данных состоит из нескольких этапов. Сначала молекулы из крупных химических баз PubChem, ChEMBL и Enamine расщепляются на фрагменты с помощью алгоритма BRICS.
Затем эти фрагменты сопоставляются с реакционными центрами шаблонов, выделенных из базы USPTO-FULL, что позволяет предсказать возможные продукты реакции. Такая методика гарантирует, что создаваемые реакции сохраняют химическую обоснованность и соответствуют реальным закономерностям реакций. После формирования массива огромных данных RSGPT проходит фазу предобучения, в ходе которого модель учится прогнозировать взаимосвязи между продуктами, реагентами и шаблонами реакций. Это достигается посредством четырёх взаимодополняющих задач самообучения, в рамках которых модель учится на основе продуктов предсказывать реагенты и шаблоны, и наоборот. Такая комплексная стратегия способствует формированию глубокого понимания химических реакций.
Дополнительно к предобучению применяется метод усиленного обучения с обратной связью от искусственного интеллекта (RLAIF). Здесь сгенерированные моделью реакции проверяются алгоритмом RDChiral на соответствие исходным продуктам, и на основе этой валидации формируется награда, которая направляет обучение модели. Эта технология заменяет традиционные ресурсоёмкие методы обучения с привлечением человеческой экспертизы и эффективно корректирует поведение модели, делая её более точной и надежной. Финальная стадия — дообучение на специальных наборах данных, таких как USPTO-50k, USPTO-MIT и USPTO-FULL, адаптирует модель под конкретные области химических реакций и повышает точность предсказаний на известных реакционных пространствах. Результаты тестирования RSGPT впечатляют.
На классическом тестовом наборе USPTO-50k модель демонстрирует точность Top-1 равную 63.4%, что значительно превышает показатели предыдущих шаблонных, полушаблонных и шаблонно-свободных методов. При использовании методов аугментации данных точность ещё выше — достигает 77%. Эти результаты свидетельствуют о том, что предварительное обучение на масштабных синтетических данных и применение RLAIF оказывают существенное влияние на повышение эффективности модели. Кроме того, RSGPT успешно справляется с многошаговым планированием синтеза сложных молекул, включая фармацевтические препараты, что подтверждает её потенциал для практического применения в химии и фармацевтике.
Модель предсказывает последовательности реакций, схожие с литературными маршрутами, а иногда предлагает альтернативные эффективно реализуемые планы синтеза. Несмотря на очевидные успехи, в работе с RSGPT существуют и вызовы. Генерация синтетических данных, хотя и позволяет масштабировать обучение, не полностью исключает появление некоторых менее обоснованных реакций. Также использование RDChiral ограничено реакциями с числом реагентов от 1 до 3, что ограничивает разнообразие реакций. Кроме того, при генерации реакций пока не учитываются параметры условий реакции, такие как растворители или температура, что влияет на полноту моделирования.
Будущие исследования направлены на расширение функционала модели, улучшение качества и разнообразия используемых данных и интеграцию дополнительных химических факторов. В целом, создание RSGPT знаменует новый этап в области компьютерного синтеза и искусственного интеллекта в химии. Легкость масштабирования, высокая точность и способность обучаться на больших данных открывают широкие возможности не только для автоматизации ретросинтетического анализа, но и для разработки новых лекарственных препаратов, материалов и каталитических систем. Модель помогает преодолевать ограничения традиционных методов и способствует ускорению научных открытий. Будущие перспективы развития включают интеграцию RSGPT с визуальными и графическими представлениями молекул, расширение возможностей по обработке многошаговых синтезов и внедрение адаптивного обучения на основе реакционных условий.
Такой подход позволит создавать интеллектуальные инструменты, способные поддерживать химиков при проектировании сложных молекулярных структур и оптимизации синтетических маршрутов. Таким образом, RSGPT демонстрирует, как синергия больших данных, современных методов глубокого обучения и химического моделирования может кардинально преобразить процесс планирования синтеза, делая его более доступным, эффективным и интеллектуальным.







