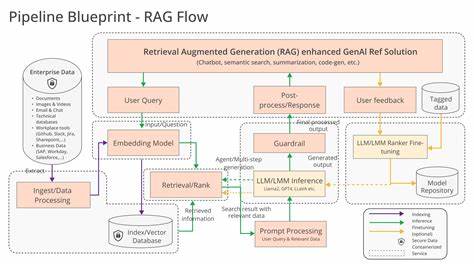
Retrieval-Augmented Generation, или RAG, является одной из наиболее перспективных технологий в сфере обработки естественного языка и информационного поиска. Эта методика сочетает в себе возможности векторного и текстового поиска с генеративными способностями больших языковых моделей (LLM), что позволяет создавать интеллектуальные приложения для быстрого доступа к релевантной информации в больших объемах данных. В современном мире, где количество деловой и учебной документации растет экспоненциально, платформа Vespa предлагает мощное решение для построения масштабируемых RAG-приложений с высоким качеством выдачи и гибкой архитектурой. Ключевая задача при разработке RAG-приложений — обеспечить быстрое и точное извлечение релевантного контекста для LLM из больших коллекций документов. Для этого необходима правильная выборка единиц поиска, построение эффективных моделей данных, настройка многофазного ранжирования и интеграция с внешними генеративными системами.
Vespa предлагает инструменты, которые позволяют решить данные задачи на профессиональном уровне и разрабатывать приложения, способные выдерживать большие нагрузки и объемы данных. При разработке RAG-приложения на Vespa важно начать с понимания и моделирования ваших данных. Примером может служить документ-ориентированная коллекция, содержащая корпоративные документы, записи встреч, обучающие материалы и логи работы. В такой структуре рекомендуется выбирать единицей поиска не отдельные предложения или страницы, а документы или их крупные части — от 1000 символов и выше. Это позволяет избежать дублирования контекста и повысить качество релевантности с минимальными накладными расходами по обработке.
В Vespa можно автоматически разбивать текстовый контент на фиксированные по длине блоки — чанки — по 1024 символа, которые индексируются и встраиваются (эмбеддятся) отдельно. Для каждого чанка вычисляются векторные представления, которые дополняются традиционными текстовыми индексами с использованием bm25. Для эффективного поиска и ранжирования используются гибридные запросы, объединяющие текстовые и векторные операторы, что значительно повышает полноту и точность выдачи. Плюсом Vespa является возможность использования бинаризированных векторных представлений, что значительно снижает затраты памяти и ускоряет вычисления с минимальной потерей качества. При этом Vespa поддерживает раскодирование бинарных векторов обратно во float-формат для более точного расчета косинусного сходства, что позволяет повышать качество ранжирования в последующих фазах.
Важным аспектом является хранение метаданных и сигналов о качестве документов в виде структурированных полей. К таким полям относятся отметки времени создания и модификации, показатели популярности, пользовательские метки «избранное» и активность использования. Это позволяет применять эффективные фильтры и усиливать рейтинг документов, которые более релевантны и востребованы для конечного пользователя. Для управления запросами Vespa предлагает мощный механизм query-профилей. Это специальные настройки, которые позволяют централизованно управлять параметрами ранжирования, обработкой и выдачей результатов без необходимости изменения клиентского кода.
Используя наследование, можно создавать базовые профили для обычного поиска и расширять их для задач RAG, Deep Research или гибридных сценариев. Такой подход заметно упрощает масштабирование и адаптацию приложения под разные потребности. Ранжирование в Vespa строится по многофазному принципу. Первая фаза — это быстрый отбор кандидатов, для которого выбираются вычислительно недорогие признаки, такие как bm25 и упрощенные метрики векторного сходства. Эта фаза отвечает за максимальное расширение выборки с акцентом на полноту — важно не пропускать релевантные документы.
Данные для первой фазы собираются с помощью инструментов VespaFeatureCollector. На их основе можно обучить простую линейную модель — например, логистическую регрессию. Важное преимущество: коэффициенты модели можно динамично передавать в запросы, что позволяет гибко менять вес признаков без обновления сервера. Такой механизм гарантирует плавную настройку ранжирования и быстрое тестирование гипотез. Вторая фаза ранжирования позволяет использовать более сложные модели — градиентные бустинговые деревья (GBDT) или даже нейросети.
За счет меньшего количества кандидатов эти модели могут включать дорогие и тонкие признаки: тексты, агрегаты по чанкам, метаданные и взаимодействие различных сигналов. Обучение проводится на расширенных наборах признаков, которые собираются во время предшествующих этапов с использованием VespaFeatureCollector и занимает важное место в общем процессе. Обучение GBDT-модели проводится с применением современных методов кросс-валидации и отбора признаков, что помогает избежать переобучения и повысить обобщающую способность ранжировщика. В результате достигается значительный прирост качества релевантности без значительного увеличения задержек ответа приложения. Особое внимание уделяется оценке качества обоих этапов ранжирования и всей retrieval-фазы в целом.
Vespa предлагает интеграцию с тестовыми инструментами, которые измеряют метрики recall, precision, MRR, NDCG и другие ключевые показатели релевантности и производительности. Поддержка подробных логов и диагностики упрощает поиск узких мест и настройку системы. Для интеграции с LLM Vespa предоставляет возможность вызова генеративных моделей через OpenAI-совместимые API или локальные модели. Это позволяет выстроить end-to-end pipeline, где извлеченный контекст передается языковой модели, которая формирует осмысленные ответы, резюмирует данные или выполняет другие задачи. Безопасность и управление ключами API реализованы через хранилища секретов и сервисные конфигурации Vespa Cloud.
Фреймворк Vespa предлагает удобный шаблон для разработки RAG-приложений в виде хорошо структурированного пакета с разделением логики обработки, схем, моделей и политик ранжирования. Такой подход облегчает сопровождение и развитие проектов. Использование нескольких источников текстовых полей и отдельных эмбеддингов позволяет повысить качество поиска за счет разнообразия сигналов. Так, заголовки и основной текст индексируются и встраиваются отдельно, что дает возможность оптимального взвешивания разных частей документа. Выбор модели эмбеддинга — баланс между скоростью, объемом памяти и точностью.
Vespa поддерживает популярные open-source модели, а также предоставляет инструменты для дообучения и конвертации под свои нужды. Использование многоразмерных и бинарных векторов снижает расходы без ущерба для качества. Перспективой развития RAG-систем на Vespa является внедрение этапа глобального ранжирования, который может использовать кросс-энкодеры или дополнительные сложные модели для улучшения порядка выдачи топовых документов. Это критично для пользовательских интерфейсов, хотя для LLM-генерации важность точного порядка ниже. В итоге построение RAG-приложений с Vespa — это процесс, базирующийся на глубоком понимании данных, грамотной архитектуре и многофазном ранжировании с использованием современных моделей.
Приведенная методология и шаблоны кода позволяют создавать высокоэффективные системы, готовые к масштабированию и интеграции с различными LLM и инструментами. Такой подход открывает возможности для автоматизации поиска и анализа знаний любого масштаба, что делает Vespa одним из лучших инструментов для профессиональных разработчиков интеллектуальных информационных сервисов.