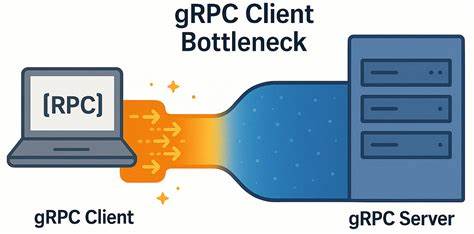
gRPC давно зарекомендовал себя как мощная и эффективная платформа для межсервисного взаимодействия, построенная на основе протокола HTTP/2 и обеспечивающая высокопроизводительные удалённые вызовы процедур (RPC). Однако, несмотря на все преимущества, разработчики нередко сталкиваются с неожиданными ограничениями в производительности при работе с gRPC в условиях сетей с очень низкой задержкой. Одна из таких проблем — узкое место на стороне клиента, которое при тщательном анализе оказалось следствием особенностей работы каналов и потоков HTTP/2. Рассмотрим этот феномен, его проявления, причины и практические пути оптимизации на реальном примере из разработки распределённой базы данных YDB. YDB использует gRPC для предоставления API, и именно в процессе нагрузочного тестирования этого сервиса была выявлена масштабируемая проблема, которая может касаться многих систем, использующих gRPC.
Суть проблемы заключалась в том, что при сокращении числа серверных узлов кластера производительность клиентов не возрастала пропорционально, а возрастала клиентская латентность и возникали ресурсы кластера, простаивающие без нагрузки. Такое поведение ставило под сомнение эффективность масштабирования и работу клиентов под высокой нагрузкой. Для понимания сущности проблемы важно вспомнить архитектуру gRPC клиента. gRPC строится на основе каналов связи (channels), каждый из которых оперирует своим TCP-соединением через HTTP/2. При создании канала можно указывать параметры конфигурации, которые влияют на использование TCP соединений.
При этом неожиданно оказалось, что при одинаковых параметрах несколько каналов могут использовать одно TCP-соединение и, соответственно, совместно ограничиваться лимитами HTTP/2 на количество параллельных потоков. По умолчанию, одно соединение HTTP/2 ограничено 100 параллельными потоками, то есть одновременными RPC-вызовами. При достижении этого лимита все дополнительные вызовы откладываются в очередь, что приводит к замедлению общего исполнения. Официальные рекомендации по gRPC предполагают два варианта обхода этой проблемы — это создание отдельного канала для каждого направления интенсивной нагрузки или использование пула каналов с уникальными конфигурациями, чтобы избежать повторного использования одного соединения. Однако на практике эти рекомендации могут оказаться недостаточными или плохо понятными в части реализации.
На основе микробенчмарка ping, разработанного командой YDB, была воспроизведена ситуация, когда каждый рабочий клиентский процесс создавал свой канал с одним активным запросом (closed-loop тест с равным числом активных запросов и клиентов). Тест запускался на двух физических машинах с процессорами Intel Xeon Gold и скоростным сетевым подключением в 50 Гбит/с, где время RTT около 0.04 мс, обеспечивая практически идеальные условия для низкой латентности. Результаты тестирования показали, что пропускная способность не масштабировалась пропорционально росту числа параллельных запросов. При десятикратном увеличении числа клиентов прирост производительности составил лишь около 3.
7 раза, при двадцатикратном — всего около 4 раз. При этом латентность растёт почти линейно с количеством активных клиентов, что сильно ограничивает возможности повышения нагрузки. Для понимания корня происходящего была проведена детальная сетевая диагностика с использованием tcpdump и Wireshark. Не было выявлено проблем с самим сетевым соединением — отсутствовало сжатие пакетов, не было долгих задержек ACK, окно TCP было достаточным и настроено оптимально, Nagle отключён. Сервер отвечал быстро.
Задержка же появлялась на стороне клиента в промежутке между подтверждением ответа сервера и отправкой следующего запроса примерно на 150–200 мкс. По сути, клиент «выдерживал паузу», что сильно ограничивало поток данных. Это говорит о том, что узким местом выступает не сеть и не сервер, а внутренняя логика клиента или механизм очередей gRPC. Кроме того, повторные попытки создавать несколько каналов на каждого рабочего клиента с одинаковыми параметрами не дали улучшения, поскольку все эти каналы продолжали использовать одно и то же TCP-соединение. Ключ к решению был найден в использовании уникальных параметров при создании каждого канала.
В частности, задавая для каждого канала свой специальный аргумент, предотвращающий повторное использование существующего соединения (например, GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL), удалось добиться значительного роста производительности. Производительность выросла почти в 6 раз для обычных RPC и в 4.5 раз для потоковых RPC. При этом рост латентности с увеличением конкуренции запросов стал гораздо более умеренным. Следовательно, первостепенная рекомендация для высокопроизводительных gRPC клиентов в сетях с низкой задержкой — создавать каналы с уникальными параметрами, чтобы получить независимые TCP соединения и избежать взаимной блокировки защиты потоков HTTP/2.
Особенно это актуально для сценариев с большим количеством одновременных запросов на одного или нескольких клиентов. Интересно отметить, что при большем сетевом RTT, например, 5 мс, проблема практически исчезает из-за доминирования сетевой задержки над внутренними паузами клиента. Это говорит о том, что рассматриваемое узкое место становится значимым лишь в условиях современных высокоскоростных сетей с минимальной задержкой, где даже микрозадержки клиента могут существенно влиять на производительность. Важно также отметить, что мониторинг TCP соединений с помощью утилиты lsof помогает быстро выявить, сколько физических соединений использует клиент, а анализ с помощью сетевых сниферов укажет на паттерны задержек в RTT. Выводы из этого опыта особенно ценны для разработчиков RTS-систем, high-frequency trading, распределённых баз данных и иных критичных к латентности решений, где gRPC применяется как транспортный слой.
Эффективное управление каналами gRPC, грамотное распределение нагрузки между TCP соединениями и понимание особенностей HTTP/2 потоков позволяет избавиться от скрытых узких мест и полностью раскрыть потенциал аппаратного обеспечения и сетевой инфраструктуры. В общем виде принцип оптимизации сводится к тому, чтобы не допускать совместного использования одного TCP соединения несколькими каналами с интенсивным одновременным трафиком и гарантировать независимость сетевых путей. Это снижает очередь RPC и устранит ограничения, накладываемые по умолчанию настройками gRPC. Помимо этого, стоит помнить о других факторах, влияющих на производительность. Использование таск-сетов для закрепления потоков на однопроцессорных ядрах в одном NUMA-узле повышает постоянство измерений и снижает контекстные переключения.
Минимизация объектов и простая логика на клиенте позволяют исключить накладные расходы, чтобы не мешать детальной диагностике. При возникновении высокой латентности или слабой масштабируемости в gRPC приложениях первым этапом диагностики следует проверить сколько у клиента активно TCP соединений и насколько они загружены параллельными потоками. Использование различных параметров каналов для создания множества независимых подканалов — простой и проверенный способ получить резкий рост пропускной способности и понизить латентность при большой нагрузке. В заключение можно отметить, что gRPC — действительно мощный и производительный механизм, однако, как и в любой сложной системе, существует множество тонкостей реализации, которые при игнорировании могут существенно ограничивать возможности. Понимание архитектурных особенностей HTTP/2, лимитов по параллельным потокам и поведения клиента под нагрузкой позволяет точечно устранять «узкие места» и добиваться максимальной эффективности.
Искать и устранять настоящие узкие места в системе, а не заниматься оптимизацией уже узких компонентов, — принцип, который подтверждается на практике благодаря исследованиям команды YDB. Их опыт показывает, что производительность систем зависит не только от мощности оборудования и оптимизации серверной части, но и от тонких деталей клиентской реализации, что особенно важно в условиях современных сверхнизкозадержечных сетей.


![Helix 25.07: What's New? [video]](/images/982CBC07-1A6F-439B-A1A5-8D6C3290237C)
![NHTSA: Withdrawing Proposal for Speed Limiting Devices [pdf]](/images/AAF2E185-F191-4E48-A9F0-00C42C5418F9)
