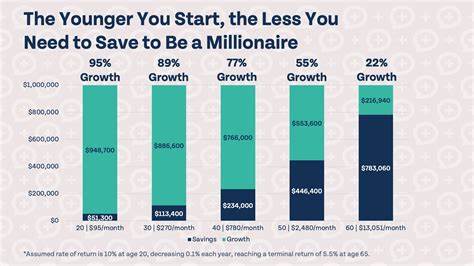
Программное обеспечение постепенно проникает во все сферы жизни, становясь основой для управления сложными системами — от медицины и транспорта до финансов и космоса. При этом история знает множество примеров странных и порой катастрофических багов, которые приводили к сбоям, убыткам и даже гибели людей. Рассмотрение этих случаев — не просто повод для удивления или смеха, а важный урок, который помогает разработчикам и инженерам совершенствовать процессы разработки, тестирования и эксплуатации ПО. Одна из ключевых проблем, влияющих на появление таких багов, — это невероятная сложность современных систем. Чем больше слоёв, интеграций и участников задействовано в проекте, тем ближе мы подходим к парадоксу: даже малейшая неточность или ошибочное предположение в коде может вызвать цепную реакцию с катастрофическими последствиями.
Ярким примером таких цепочек стала трагедия с Boeing 737 MAX 8 в 2018 году. Программный модуль для автоматической стабилизации полёта неправильно интерпретировал данные датчика, что приводило к дестабилизации самолёта. Пилоты не имели возможности однозначно отключить эту функцию, и всего лишь несколько строк кода повлияли на гибель множества людей. Этот случай показывает, как опасно, когда программное обеспечение выполняет действия без полноценного информирования пользователя. В эру больших и распределённых систем ключевым моментом становится не только устранение одиночных ошибок, но и выявление ситуации, когда мелкие сбои в разных компонентах накладываются друг на друга, обостряя проблему.
Концепция модели швейцарского сыра прекрасно этому соответствует — когда один слой защиты содержит дырки, это не всегда фатально, но в моменты совпадения дефектов на нескольких уровнях риск аварии резко возрастает. Оттого тестирование должно учитывать не только изолированные варианты, но и потенциальные взаимодействия между фрагментами кода и инфраструктуры. Интригующий пример из мира IT — инцидент 2009 года, когда обновление системы Google Safe Browsing, предназначенной для защиты пользователей от вредоносных сайтов, привело к тому, что в результатах поиска все сайты показывались как опасные, включая сам Google. Ошибка была связана с опечаткой — инженеру удалось невзначай присвоить символ «/» в фильтре, что по сути охватывало все ресурсы ниже домашнего каталога. Такая проблема напоминает о том, как важно проводить многоступенчатое тестирование, даже если кажется, что изменения очень простые.
Но не только современные цифровые сервисы поддаются странным ошибкам. Космическая отрасль тоже не застрахована от роковых багов. Примером служит потеря миссии NASA с марсоходом стоимостью 125 миллионов долларов в 1999 году. В результате смешения единиц измерения — одни инженеры использовали английскую систему, другие метрическую — навигационные расчёты привели аппарат к слишком низкой орбите. Результат — разрушение аппарата атмосферой Марса и крах десятимесячного космического путешествия.
Этот случай подчёркивает необходимость согласованности в коммуникациях между разными группами, а также важность интеграционного тестирования систем на стыках взаимодействия. Истории о необычных ошибках сопровождаются забавными и поучительными случаями обработки данных. Например, сотрудник компании Sun Microsystems в 1990-х годах с именем Steve Null бесследно исчезал из баз данных системы, потому что строковое значение «Null» обрабатывалось как отсутствие данных. Аналогично, случаи, когда автоматическое удаление данных ошибочно срабатывало на реальных, казалось бы, тестовых наименованиях или, наоборот, не учитывало риск удаления важных записей, показывают, что программная логика должна гибко и подробно обрабатывать входящие данные, не допуская упрощений и категоричных предположений. Внимание также заслуживает феномен автоматической корректировки в Excel, который воспринимает комбинации символов SEP15 или MARCH5 как даты.
Этот казус привёл к тому, что значимое количество научных публикаций содержало неверно преобразованные данные о генах, что ставило под сомнение точность исследований. Задача разработчиков — учитывать, что иногда «улучшения» программ могут стать причиной скрытых дефектов, и создавать механизмы для контролируемого управления такими искажениям. Финансовые алгоритмы, хоть и кажутся гораздо более формализованными, не застрахованы от абсурдных багов. Так, на Amazon одна книга оказалась выставлена по невероятной цене — более 23 миллионов долларов, что стало результатом зацикливания двух конкурирующих ценообразующих автоматических систем. Одна цена была всегда чуть ниже другой, вторая — несколько выше, что в итоге создавали неустойчивый цикл повышения стоимости.
Происходящее наглядно показывает, насколько важно тщательно прорабатывать логику автоматизированных процессов и учитывать возможность бесконечных циклов. Отчёты о таких ошибках помогают индустрии идти вперёд. NASA после трагедии с марсоходом внедрило жёсткое стандартизированное использование единиц и улучшило коммуникации между командами. Другие организации, столкнувшись с последствиями багов, совершенствуют методики тестирования, документацию и процессы взаимодействия. В программировании дают уроки и самые, казалось бы, простые ошибки: например, установка Linux в 2011 году сопровождалась проблемой, когда из-за отсутствия пробела в команде удаления файлов уничтожался не один каталог, а целая структура данных.
Такой баг мог быть совершенен всего лишь потому, что человек не обратил внимание на нюанс синтаксиса системы. Что же можно извлечь из изучения самых странных, необычных и порой катастрофичных багов? Главный вывод — мир и проекты невероятно сложны, и в ошибках кроется не столько вина отдельного человека, сколько системный вызов. Не стоит делить баги на мелкие и крупные — зачастую именно цепочка мелочей, взаимосвязей и несовпадений приводит к сбоям. Это значит, что внимание должно уделяться не только деталям кода, но и структуре взаимодействий, коммуникациям, инженерной культуре и процедурам проверки. Неустанное тестирование, включая интеграционное и стрессовое, одно из важнейших средств против подобных трагедий и курьёзов.
Также важным аспектом является готовность организаций учиться на ошибках и внедрять изменения. Истории с Boeing, NASA и крупными интернет-компаниями показывают: понимание природы багов, открытость к расследованию и совершенствование процессов — путь к построению более надёжных систем. Разработчикам рекомендуется относиться к каждой строчке кода, к каждому предположению и каждому взаимодействию между системами как к потенциальной точке риска. Несмотря на огромные свершения информационных технологий, ошибки нельзя отбрасывать как неловкие промахи или исключения. Они — зеркала сложности и возможностей для роста.
Они помогают формировать культуру ответственности, глубокого анализа и постоянного самосовершенствования. В конечном счёте, чем больше мы знаем про самые удивительные баги прошлого, тем лучше можем подготовиться к вызовам будущего в программировании и инженерии систем.