Развитие больших языковых моделей (LLM) открывает новые горизонты для искусственного интеллекта, в частности в области обработки и генерации текстов. Однако одна из ключевых проблем, с которой сталкиваются разработчики и исследователи — это организация и поддержание памяти модели, что влияет на качество и осмысленность создаваемого контента. Несмотря на впечатляющие успехи в понимании и генерации языка, современные LLM ограничены размером контекстного окна и возможностями хранения информации для длительных взаимодействий. Рассмотрим основные трудности и существующие подходы к проектированию памяти LLM, а также возможные пути их преодоления. Первая значимая проблема связана с ограничением контекста.
В ранних версиях моделей, таких как GPT-3, размер контекстного окна составлял около 4000 токенов, включая как входные данные, так и ответы. Это означает, что модель одновременно «помнила» лишь несколько страниц текста. При создании объемных произведений, например, романов или аналитических отчетов, такой объем памяти явно недостаточен для удержания всей необходимой информации. Автор, словно амнезиак, вынужден восстанавливать детали, делать предположения и часто повторять информацию, создавая риск потери последовательности и связности сюжета или аргументации. Другой важный аспект — необходимость учета различных контекстных «фреймов» или референтных систем, в которых знания актуальны.
Например, утверждение «Берлин — столица Германии» верно сегодня, но было бы неверным для периода 1945-1990 годов, когда столица Западной Германии была Бонн. В фантастических произведениях или альтернативных историях эта информация может меняться в зависимости от творческого контекста автора. Такой временной и пространственный контекст сложно формализовать и интегрировать в память модели простыми методами. Зачастую именно игнорирование таких нюансов приводит к ошибкам и несогласованности генерации. Современные системы часто пытаются решать проблему хранения мощных знаний с помощью векторных эмбеддингов.
Это способ представления текстов в виде точек в многомерном пространстве, где семантически близкие тексты располагаются рядом. Несмотря на свою эффективность для поиска схожей информации и рекомендаций, векторные базы данных имеют ограничения. Хранение цепочек и последовательных эпизодов, где важен порядок событий, усложняется, поскольку векторная близость не всегда способна отразить причинно-следственные связи. Кроме того, растет сложность объяснения, почему два вектора оказались близки или далеки, а также смещение данных в зависимости от набора обучения и выбранных метрик. Альтернативой векторным подходам служат графы знаний.
В этой парадигме информация хранится в виде узлов и связей между ними, где связи могут иметь различное семантическое значение, например, отношения «отец — сын» или «произошло после». Такой способ отображения приближает модель к человеческому восприятию и позволяет более явно фиксировать контекст, временную последовательность и пространственные характеристики. К примеру, события могут быть связаны в хронологическом порядке, а персонажи — в семейных или социальных отношениях. Тем не менее, и графы знаний сталкиваются с вызовами масштабируемости и хранения: при большом объеме данных графы могут становиться слишком разветвленными и трудно управляемыми. Для борьбы с этим активно применяются методы создания мета-документов — обобщенных информационных узлов, которые агрегируют данные из множества связанных документов и позволяют оптимизировать запросы к памяти.
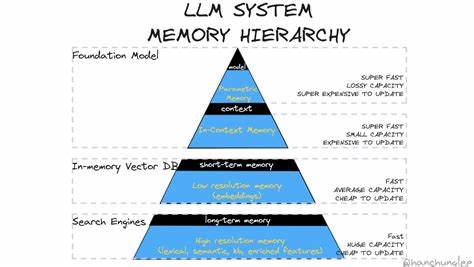
Такие мета-документы могут хранить результаты ранее выполненных запросов, списки предпочтений или обобщенные выводы, тем самым служа своего рода кэшем и инструментом повышения эффективности. Важно отметить, что в процессе работы системы память должна быть динамична, уметь забывать устаревшие или малополезные связи и при этом сохранять важные. Для этого применяются алгоритмы релевантности и частотности обращения к отдельным элементам памяти, а также оценки полезности определенных связей и узлов с помощью моделей. Такой подход напоминает процесс забывания и реконсолидации воспоминаний у человека, что способствует поддержанию актуальности знаний и снижению шумов при поиске информации. Еще одной ключевой характеристикой является необходимость хранения эпизодических воспоминаний — последовательных описаний событий, происходящих с моделью или агентом в процессе взаимодействия с окружением.
Это обеспечивает сохранение чувства времени и причинно-следственных связей, помогает строить повествовательные конструкции и логику. Такие эпизоды могут объединяться в ежедневные, недельные и даже годовые обзоры, образуя иерархическую структуру памяти, что особенно эффективно при построении долгосрочных моделей поведения и анализа. Технологии для реализации памяти довольно разнообразны и часто включают интеграцию внешних баз данных, таких как SQL, где детали могут быстро извлекаться и обновляться. Таким образом, сложные факты и справочные данные хранятся вне ядра модели, что снижает нагрузку на контекст и позволяет использовать специализированные запросы. Также для временного хранения и работы с текущим состоянием часто применяются так называемые «черновики» или «scratchpad» — текстовые логи, куда регулярно добавляются новые сведения и куда периодически вносятся исправления и очистки.
Такая система позволяет модели сохранять локальный контекст действий и размышлений, но при разрастании требует интеллектуального управления, чтобы избежать циклических ошибок и потери ключевой информации. В целом, проектирование памяти больших языковых моделей является сложной инженерной и научной задачей. Требуется тонкая балансировка между объемом хранимой информации, скоростью доступа к ней и способностью модели эффективно использовать знания в заданном контексте. Также нельзя забывать о том, что память — неотъемлемая часть личности, мотивации и целевых установок агента, поэтому важна интеграция разных видов памяти для формирования единообразного и когерентного восприятия мира. В будущем, вероятно, появятся новые гибридные методы, сочетающие нейросетевые подходы с структурированными хранилищами знаний и агентными системами, где память будет одновременно постоянной и адаптивной, способной к непрерывному обучению и самоорганизации.
Некоторые исследователи предполагают появление моделей с так называемой «многоуровневой памятью», где локальные кратковременные данные плавно интегрируются в долговременные репозитории с учетом актуальности и полезности. Таким образом, память больших языковых моделей — это не просто хранилище данных, а живой и изменчивый механизм, который требует глубокого понимания, инновационных технологий и творческого подхода. Решение этих задач окажет фундаментальное влияние на развитие искусственного интеллекта, расширит возможности взаимодействия машин и человека и приблизит создание по-настоящему интеллектуальных систем, способных полноценно понимать и поддерживать диалог на любые темы.