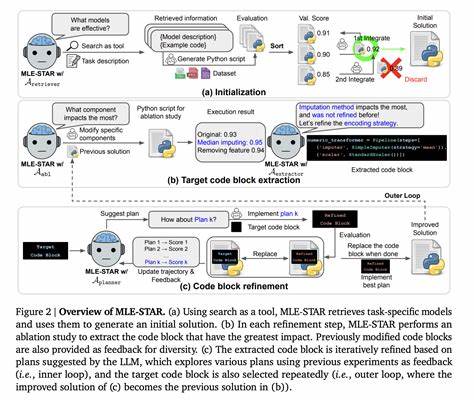
В эпоху цифровых технологий и больших данных эффективность инструментов анализа и обработки информации становится ключевым фактором успеха. Среди наиболее популярных средств для быстрой работы с данными традиционно числились электронные таблицы. Их интуитивно понятный интерфейс и визуальная близость к математическим выражениям позволяли миллионам пользователей выполнять расчёты и анализы без глубоких знаний программирования. Однако с ростом масштабов и усложнением вычислительных моделей классические таблицы всё чаще сталкиваются с проблемами производительности, типовых ошибок и сложности отладки. Именно эта ситуация послужила толчком к созданию нового поколения языков программирования, объединяющих в себе декларативный стиль и реактивную архитектуру — последний пример такого подхода представлен в разработке компании Decipad.
Основная проблема стандартных электронных таблиц — их неспособность масштабироваться при возрастании количества взаимозависимых формул. Каждое изменение значения вызывает цепочку пересчётов, которая зачастую растет экспоненциально, что негативно сказывается на отзывчивости и удобстве работы. При этом пользователи часто сталкиваются с концептуальными сложностями в виде кольцевых зависимостей, когда формулы ссылаются друг на друга, создавая бесконечные циклы, либо с типовыми ошибками, которые проявляются только во время выполнения, усложняя выявление и исправление. Потребность в инструменте, сочетающем простоту электронных таблиц с надёжностью и гибкостью языков программирования, стала очевидной. Ответом на эти вызовы стал реактивный декларативный язык, который позволяет описывать не пошаговые инструкции, а желаемый результат.
Такой язык обеспечивает автоматическое и мгновенное обновление результатов при изменении входных данных за счёт построения и поддержания графа зависимостей. Важной особенностью является строгая типизация, позволяющая выявлять ошибки ещё на этапе анализа кода, а не в процессе выполнения. Кроме того, отсутствуют традиционные циклы, такие как for или while — их заменяют выражения на основе функций высшего порядка и автоматического отображения операций на коллекции данных. Функция авто-маппинга стала одним из краеугольных камней языка. Она позволяет применять операции сразу ко всей коллекции элементов без необходимости явно задавать циклы.
Это заимствовано из функционального программирования, языков обработки данных и массивно-векторных языков, таких как APL или Haskell. Пользователь просто описывает, что хочет сделать с набором данных, а система сама элемент за элементом применяет соответствующую функцию. Такой подход не только упрощает синтаксис, но и открывает возможности для внутренних оптимизаций и параллельного выполнения. Использование функций высшего порядка, таких как filter, sum, mean и group, позволяет выразить сложные фильтрации, агрегации и группировки понятным и лаконичным образом. Это повышает читаемость кода, облегчает оптимизацию и расширяет потенциал для автоматического параллелизма без лишних усилий со стороны пользователя.
Таким образом, язык не перегружает пользователя деталями реализации, давая ему возможность фокусироваться на логике анализа данных. Ещё одной важной составляющей является грамматика языка, построенная с учётом естественной интуиции пользователей, знакомых с электронными таблицами, но стремящихся к расширению возможностей. Парсер на основе Nearley обеспечивает гибкую структуру синтаксиса, которая не ломается при введении новых конструкций, будь то сложные функции, операции с таблицами или фильтрация данных. Простой и понятный синтаксис снижает порог входа и способствует быстрому обучению. Типовая система оценки выражений выполняет роль «стража» качества — ошибки выявляются ещё на этапе парсинга и анализа, что предотвращает появление невалидных вычислений в процессе исполнения.
Поддержка базовых и комплексных типов, таких как числа, строки, булевы значения, даты, а также коллекции и таблицы, создаёт надежный фундамент для разнообразных сценариев использования. Наличие функций с определёнными параметрами и анализ возвращаемых типов повышает гибкость и предотвращает логические ошибки. Важную роль в повышении производительности играет механизм отслеживания зависимостей. Создавая направленный ацикличный граф, система точно знает, какие выражения зависят от изменившихся значений. Такая архитектура способна минимизировать объём перерасчётов, перезапуская только те вычисления, которые действительно затронуты изменениями, что является краеугольным камнем эффективности реактивных систем.
Инкрементальные вычисления становятся сердцем производительности. Благодаря механизму, который сперва выявляет все пострадавшие выражения, затем очищает кешированные значения и пересчитывает данные в правильном порядке, удаётся поддерживать быструю и корректную реакцию даже в условиях интенсивных изменений. Внедрение кеширования, отложенных вычислений и параллельного исполнения повышает масштабируемость и отзывчивость системы. Реализация реактивной архитектуры не ограничивается лишь ядром языка — взаимодействие с пользователем играет не менее значимую роль. Система сбора и обработки изменений с использованием событийной модели и продвинутой обработки потоков изменяющихся значений обеспечивает его плавность и оперативность.
Выбор буфера с фиксированным временным окном, а не типичного дебаунса, позволяет аккумулировать большое количество быстропротекающих изменений, не теряя их и не создавая ощутимых задержек. Ошибка — неизбежный спутник любой сложной системы. Поэтому был разработан продуманный механизм её обработки: ошибки изолируются, чтобы не нарушать работу всей вычислительной цепочки, а пользователю предоставляется максимально информативная диагностика с указанием контекста, расположения в коде и советами по исправлению. Такая стратегия снижает общую хрупкость системы и облегчает выявление проблем. Когда дело касается масштабируемости, внимательное отношение к оптимизации производительности становится необходимостью.
Управление памятью реализовано посредством механизма кеширования с использованием метода устранения наименее востребованных данных. Это позволяет высвобождать ресурсы без ущерба для быстроты отклика. Параллельное выполнение независимых задач распределено по рабочим потокам и веб-воркерам, что позволяет эффективно использовать многозадачность современных вычислительных платформ. Пользовательский опыт дополнен интеграцией языка с редактором кода, обеспечивающим подсветку синтаксиса, интеллектуальное автодополнение, мгновенный предварительный просмотр результатов, а также различные подсказки об ошибках и демо-режимы. Повышение уровня интерактивности значительно упрощает процесс разработки и анализа со стороны конечного пользователя, делая работу более комфортной и эффективной.
Анализ опыта разработки показывает, что благодаря выбору парсер-комбинаторов удалось построить управляемую и расширяемую грамматику. Статика типизации значительно сократила количество ошибок до этапа выполнения. Архитектура реактивных вычислений позволила масштабирваться вплоть до сотен взаимозависимых выражений без проблем с производительностью. Авто-маппинг сделал синтаксис более элегантным и простым в использовании, а отказ от традиционных циклов заставил пользователей мыслить в терминах преобразования данных, что положительно сказалось на качестве кода. Тем не менее, проект столкнулся с трудностями.
Борьба с кольцевыми зависимостями требовала особого внимания, а сложность в построении системы помощи пользователю и подробной диагностики становилась серьезным вызовом. Помимо этого, оптимизация работы с большими массивами данных, особенно в контексте авто-маппинга, остаётся областью для дальнейших исследований и совершенствования. Также эксперты отмечают необходимость развивать документацию и тестирование для повышения устойчивости и удобства языка. Результатом стала мощная вычислительная платформа, способная обеспечить мгновенную реакцию на изменения и поддержку сложных моделей анализа данных, не жертвуя при этом простотой и понятностью синтаксиса. Открывается перспективы применения подхода в многочисленных сферах, где важна оперативность, интерактивность и надёжность обработки информации — от финансового анализа и инженерных расчётов до научных исследований и образования.
В заключение можно сказать, что создание реактивного декларативного языка, который совмещает грамматическую простоту и продвинутые алгоритмы инкрементальных вычислений, становится важным шагом на пути к более умным, адаптивным и масштабируемым системам. Такой язык меняет представление о том, как можно взаимодействовать с данными, влекущим за собой повышение производительности и снижение барьеров для пользователей с различным уровнем технического опыта. Если вы заинтересованы в разработке похожих систем или хотите применить идеи реактивности и декларативности в своих проектах, опыт Decipad предлагает много ценных уроков и вдохновения. Возможно, именно гибридный подход — объединяющий простоту описания и сложность под капотом — будет ключом к созданию следующего поколения инструментов для анализа и обработки данных.