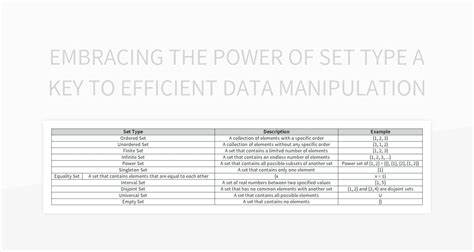
В мире современного программирования и разработки API часто встречается задача обработки запросов, в которых клиент может спросить определённое количество элементов. На первый взгляд кажется логичным считать запрос с нулевым числом элементов ошибочным состоянием, которое необходимо обработать через возвращение ошибки. Однако, более глубокий анализ и практический опыт дают понять, что принятие пустого множества как полноценного результата — важная и полезная концепция для проектирования надёжных, понятных и удобных в использовании API. Когда разработчики создают методы, например, для чтения данных или получения списка элементов, параметр, указывающий максимальное количество возвращаемых записей, часто используется для ограничения объёма данных. В некоторых случаях параметр равен нулю.
Без правильной обработки такого варианта программы могут неожиданно упасть или вести себя непредсказуемо. Если метод просто возвращает ошибку при параметре 0, клиентский код вынужден добавлять лишние проверки и усложнять логику, что противоречит принципам простоты и устойчивости. Пустое множество в программировании представляет собой коллекцию, которая существует, но не содержит элементов. Это принципиально отличается от отсутствия коллекции как таковой, когда вместо значения возвращается null или аналогичный индикатор. Различие между пустой коллекцией и отсутствием коллекции очень важно для архитектуры API, поскольку null-значение требует от потребителя специальной обработки.
Для API, ориентированного на удобство и предсказуемость, наличие пустого множества позволяет исключить лишние проверки и свести к минимуму вероятность ошибок. Рассмотрим ситуацию с пользовательским интерфейсом, где виджет отображает список элементов. Количество элементов для отображения может зависеть от размера окна и других факторов. При уменьшении размера окна результат вычисления может стать равным нулю, и, следовательно, запрос на получение нулевого количества элементов — естественный и логичный сценарий. Если API не умеет корректно обрабатывать такой запрос, приложение может получить неожиданный сбой, что негативно скажется на опыте пользователя и репутации разработчика.
Когда API позволяет запросить и получить пустой результат, он снимает с клиентов ответственность за проверку и модификацию входных параметров на предмет нуля. Такое решение соответствует принципу максимальной простоты взаимодействия и минимизации потенциальных краевых случаев. Оно также улучшает читаемость и поддержку кода, поскольку разработчикам не нужно строить дополнительную защиту вокруг запросов с нулём. В реальной практике есть примеры, когда библиотеки или платформы плохо поддерживают запросы с нулевым количеством. Некоторые функции, возвращающие коллекции или буферы, при параметре ноль могли возвращать null или вовсе ошибку.
Современные рекомендации и лучшие практики однозначны: возвращать не null, а пустую коллекцию или объект, инкапсулирующий пустоту. Такой подход упростит сериализацию, десериализацию и интеграцию с другими системами, например, при работе с JSON, где пустой массив и null интерпретируются по-разному. Сообщество разработчиков делится мнениями по этому поводу: многие высказываются в пользу строгого отделения пустых коллекций от null, что уменьшает риск возникновения NullReferenceException и аналогичных ошибок. Благодаря этому можно применять fluent-интерфейсы и цепочки вызовов без громоздких проверок на null. При проектировании API подобная гибкость и устойчивость к вариантам использования критически важна.
Несмотря на очевидные выгоды, некоторые всё ещё придерживаются мнения, что запрос с параметром ноль — это ошибка и метод должен сообщать об этом. Их аргументы связаны с тем, что программный интерфейс должен информировать потребителя об ошибочных запросах, ведь в реальной жизни никто не заказывает ноль единиц товара или не просит ноль литров топлива. Однако аналогии с реальной жизнью в программировании не всегда применимы. Компьютерные программы должны быть готовы работать с любыми целочисленными значениями и предусматривать все логические исходы, в том числе и нулевые. Обработка нулевого запроса как успешного с возвращением пустого множества улучшает устойчивость системы, избавляет клиентов от необходимости писать сложную и уязвимую логику для обработки краевых случаев, что экономит время и силы в долгосрочной перспективе.
Это особенно ценно в крупных системах с множеством компонентов, где ошибка в одном месте может привести к каскаду проблем. Кроме того, отказ от ошибок в случае нулевого параметра позволяет создавать более универсальные методы и функции с простыми контрактами. Такой дизайн способствует развитию бесшовного API, при котором поведение методов предсказуемо в любых условиях. Потребитель API может спокойно использовать методы без опасений, что неучтённый краевой случай породит исключение. Важным аспектом является и влияние на тестирование и отладку.
Методы, корректно обрабатывающие пустые входные значения и возвращающие пустые коллекции, значительно проще покрывать тестами и поддерживать. Разработчики получают более чистый и устойчивый код, что сокращает время реакции на ошибки и улучшает качество программного продукта. В качестве примера можно рассмотреть работу с потоками байтов. При чтении с потока функция может принять параметр, сколько байтов нужно прочитать. Запрос на чтение нуля байтов — легитимная операция, и чтение не должно приводить к ошибке или исключению.




![100 Cameras: Tokyo Metro [video]](/images/A9C4571A-FB10-4085-A216-E71A4B9FE5A3)