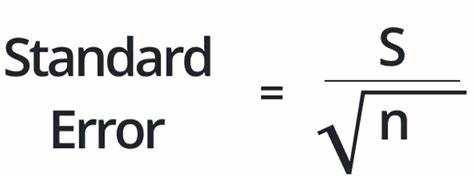
В современном мире машинного обучения и искусственного интеллекта понятия статистики и вероятности приобретают всё большую значимость. Среди них стандартная ошибка становится объектом повышенного внимания как исследователей, так и рецензентов научных конференций и журналов. Но что такое стандартная ошибка и почему вокруг неё возникает столько обсуждений, особенно в контексте таких крупных конференций, как NeurIPS? Чтобы разобраться, нужно вернуться к основам и понять, что именно измеряет стандартная ошибка и какое место она занимает в оценке результатов экспериментов. Стандартная ошибка представляет собой статистическую меру разброса оценок вокруг истинного среднего значения некоторой величины. Проще говоря, если вы запускаете эксперимент несколько раз, результаты будут немного отличаться из-за различных источников случайности — это может быть разная инициализация алгоритма, случайное разбиение данных на обучающую и тестовую выборки или вообще элементы случайного шума в системе.
Стандартная ошибка помогает понять, насколько среднее значение, полученное в результате эксперимента, близко к «настоящему» значению, которое можно было бы получить, если бы провели бесконечное число экспериментов. Казалось бы, это важный инструмент, который позволяет отличить стабильные и воспроизводимые подходы от тех, которые дают разрозненные результаты. Однако в последние годы наблюдается своего рода бюрократизация вопроса, когда научные конференции вводят строго регламентированные требования к описанию и отображению стандартных ошибок и других статистических метрик. Особенно это проявляется в рамках конференции NeurIPS, где с 2021 года внедряется всё более длинный и детальный чеклист, регулирующий требования по статистической отчетности. Теперь авторы должны не просто указать наличие error bars, а подробно описывать источники вариабельности, методы подсчёта, предположения об ошибках и форму различных доверительных интервалов.
Почему эта бюрократическая тяга возникла именно в сфере машинного обучения? Во-первых, потому что этот научный сектор стал очень популярным и коммерчески значимым: приход крупных компаний, инвестиции в модели, чей запуск требует больших ресурсов, и высокая степень конкуренции заставляют рефлексировать над качеством результатов. Во-вторых, сама природа алгоритмов машинного обучения включает элементы случайности, из-за чего необходимо понимать, насколько результат устойчив к изменению случайных параметров или данных. Но возникает вопрос: как много пользы приносят эти тщательно прописанные статистические регламенты? Многие исследователи и практики замечают, что иногда требования выглядят как формализм ради формализма, который больше затрудняет публичные отчёты, чем помогает повышать качество исследований. Особенно это заметно в ситуациях, когда данные ограничены — например, в бенчмарках с редкими задачами, где набор тестов насчитывает всего пару десятков примеров. В таких случаях использование классических статистических выводов, связанных с нормальными распределениями, кажется почти невыполнимым и неуместным.
Если модель может решить один из пятнадцати тестов, уже это стоит внимания, а попытка навешивать на это стандартные ошибки и доверительные интервалы напоминает попытки измерить вес листа бумаги с помощью складных весов для слонов. Другой немаловажный аспект касается сути самой статистики в контексте исследований в области искусственного интеллекта. Зачастую прорывные идеи и инновации здесь появляются не из-под палки строгих методологических правил, а благодаря интуиции, творческому подходу и экспериментальному «ощущению правильности». Вспомним крупные архитектурные изменения, новые оптимизаторы, неожиданные шаги с нормализациями и активациями — они редко базировались на детальных статистических проверках и вычислениях, скорее, они росли на почве проб и ошибок, пристального анализа результатов в живую и инженерного чутья. В этом плане растущая бюрократия вокруг стандартизации представления статистики не всегда гармонирует с природой исследовательского процесса и может даже восприниматься как препятствие.
И тем не менее, желание быть ответственными и прозрачными перед научным сообществом и широкой публикой вполне оправдано. Особенно когда результаты исследований начинают влиять не только на академическую среду, но и на прикладные области, где ошибки могут привести к негативным последствиям. Введение чеклистов в NeurIPS — это попытка систематизировать и повысить ответственность, хотя и очень спорная по своей реализации. Критики указывают на то, что расширение чеклистов превращается в бесконечный бюрократический процесс, который ухудшает восприятие науки и не гарантирует улучшения качества публикуемых статей. Вопрос стандартизации и контроля также затрагивает аспект воспроизводимости исследований.
Отчасти чеклисты требуют описания методов подсчёта ошибок, чтобы читатель мог понять и при необходимости воспроизвести эксперимент. Но если код не обязательно должен быть доступен, ограничивается и возможность независимой проверки результатов. Это связано с тем, что значительная часть исследований исходит из корпоративных структур, где модели и данные – коммерческая тайна. Такая ситуация создает парадокс: контролировать статистическую отчетность, не позволяя проследить логику решения реальных экспериментов, становится малоэффективно. К тому же, некоторые в научном сообществе задаются вопросом, почему именно статистические нормы, возникшие в биомедицинских и социальных науках, должны полностью переноситься на машинное обучение и искусственный интеллект.
В тех сферах распределения данных и эффектов зачастую имеют определённую природу и требования к проверке гипотез. В AI же данные и алгоритмы могут быть гораздо более сложными и нерегулярными, что ставит под сомнение пригодность классических построений доверительных интервалов и стандартных ошибок. Важно понимать, что стандартная ошибка – полезный инструмент, когда она действительно помогает определить, является ли результат устойчивым и на сколько он отражает закономерность, а не случайный шум. Но без чёткого понимания и разумной интерпретации он может превратиться в бесполезный формализм, который лишь усложняет коммуникацию внутри научного сообщества. Подводя итог, можно сказать, что стандартизация описания ошибок и других статистических оценок на конференциях, подобных NeurIPS, свидетельствует о стремлении к более ответственной и прозрачной науке.
Однако необходимость и эффективность таких бюрократических процедур остаются предметом дискуссий. Важно оставить место для творческого, интуитивного подхода к построению моделей, одновременно не забывая об элементарной ответственности перед результатами и их интерпретацией. И, возможно, самое главное — помнить, что статистика должна служить средством выражения знаний и понимания, а не самоцелью, ради которой создаются бесконечно растущие списки требований.



![100 Cameras: Tokyo Metro [video]](/images/A9C4571A-FB10-4085-A216-E71A4B9FE5A3)

