Data Science Weekly — это одно из ведущих изданий, которое еженедельно собирает и публикует самые важные новости, статьи и исследования из области науки о данных, машинного обучения, искусственного интеллекта и инженерии данных. Выпуск №606, опубликованный 3 июля 2025 года, не стал исключением и предлагает глубокий анализ современных трендов и новинок, которые заслуживают внимания каждого специалиста и энтузиаста индустрии. В современном быстро меняющемся мире Data Science играет ключевую роль в цифровой трансформации бизнеса и общества. Одной из тем, привлекших особое внимание, стала вторая редакция книги "Data and Reality". Автор подчеркивает основные проблемы работы с данными — тот факт, что данные зачастую неполны, нечётко определены и искажены из-за ограниченного понимания самих процессов сбора и интерпретации.
Эта мысль резонирует с вызовами, с которыми сталкиваются многие компании: как обеспечить корректный и осмысленный сбор данных, избегая ловушек ложных предпосылок и искаженного восприятия. Примечательна и статья об алгоритмах организации книжных полок, которая подчеркивает важность стратегического позиционирования пустых пространств при сортировке больших массивов данных. На первый взгляд, это может показаться мелочью, но в масштабах, где число записей достигает сотен миллиардов, эффективное распределение пустых промежутков помогает минимизировать трудозатраты при обновлении и добавлении новых элементов. Эта концепция может быть с успехом применена к различным задачам в компьютерных науках — от систем управления базами данных до социальных сетей. Значительный интерес вызывает анализ статистически необычных ресторанов в небольших американских городах.
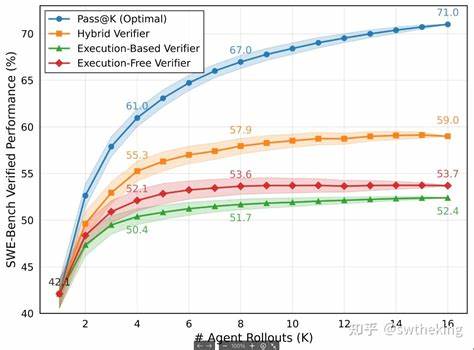
Использование данных для выявления нерутинных феноменов, таких как нехарактерные для региона заведения, позволяет лучше понять социальную и культурную динамику сообществ, выявить уникальные тенденции и потенциально новые бизнес-возможности. Этот подход отражает растущую роль аналитики данных в выявлении сложных паттернов и аномалий, которые традиционно были недоступны человеческому восприятию. Область больших языковых моделей (LLM) также не остаётся без внимания. Новый проект LLMZip демонстрирует возможности современных моделей, таких как LLaMA-7B, в предсказании следующего токена и оценке энтропии английского языка, что приводит к улучшению алгоритмов без потерь сжатия текста. Эта инновация открывает перспективы для более эффективного хранения и передачи текстовой информации, а также формирования новых методов сжатия с использованием ИИ.
Для разработчиков и пользователей языка программирования R значим событием стало внедрение форматировщика кода Air от Posit в систему Homebrew. Эта интеграция облегчает установку и позволяет повысить качество и удобство написания кода, что в свою очередь способствует улучшению рабочих процессов исследователей данных и аналитиков. Подобные шаги играют большую роль в демократизации инструментов и повышении их доступности для пользователей по всему миру. Важной темой для обсуждения стала ситуация на рынке труда в области байесовской статистики. Многие специалисты задумываются, стоит ли углубляться в этот методологический подход или лучше сосредоточиться на более востребованных навыках.
Советы и мнения сообщества подчеркивают, что байесовские методы всё ещё имеют значительный потенциал, особенно в сложных задачах с неопределённостью, хотя и требуют высокого уровня подготовки. В выпуске также рассматриваются основные принципы работы графических процессоров (GPU). Понимание архитектуры и оптимизаций CUDA, а также особенностей матричных умножений, помогает специалистам лучше использовать вычислительные мощности для обучения и вывода моделей глубокого обучения. Эта техническая база важна для достижения максимальной производительности и эффективности в проектах, связанных с большими объемами данных. Одним из интереснейших новшеств последних месяцев стала концепция «контекст-инжиниринга».
Вектор развития LLM от простых запросов к сложным системам, где важна точная подача контекста и инструментов для выполнения задачи, делает контекст-инжиниринг ключевым навыком для AI-инженеров. Создание динамичных, адаптивных систем, способных максимально полно использовать возможности ИИ, становится новой нормативной практикой в индустрии. Проникновение маркетинга в сферу open-source проектов тоже выросло. Эксперты делятся опытом, как разработчики могут эффективно продвигать свои проекты, находить заинтересованных пользователей и контрибьюторов, преодолевая зачастую сложный переход от технической деятельности к коммуникации и маркетингу. Всплеск интереса вызвала публикация о применении крошечных рекуррентных нейронных сетей в нейронауке и психологии.
Использование небольших моделей для выявления когнитивных стратегий адаптивного поведения помогает глубже понять механизмы принятия решений у животных и человека. Такая междисциплинарная работа расширяет границы самих методов Data Science, соединяя технические решения с биологическими и поведенческими науками. Новым словом в управлении базами данных стало использование Vitess для Postgres, проект, возглавляемый одним из создателей Vitess и сооснователем PlanetScale. Идея масштабирования и шардинга Postgres через Multigres призвана решить проблемы с производительностью и управляемостью в условиях роста данных, что является одной из наиболее острых задач сегодня. Выпуск также обращается к проблемам надёжности и устойчивости моделей машинного обучения.
Представлен подробный гайд по причинам сбоев и способам их предотвращения, что критически важно для промышленного применения ML-технологий. Понимание природы ошибок и нестабильностей моделей помогает разработчикам строить более качественные и предсказуемые системы. Интервью с доктором Хэдли Викхэмом, одним из ключевых фигур в сообществе R и Posit, открывает инсайты в процесс разработки популярных инструментов Data Science. Обсуждаются философия создания ПО и будущее инструментальных средств, подчеркивая значимость правильного дизайна и поддержки сообществ. Проект по изучению необычных применений Python в популярных библиотеках демонстрирует, что даже в широко используемых инструментах можно найти нестандартные и эффективные решения, расширяющие возможности языка и упрощающие жизнь разработчиков.
Выпуск затрагивает и спорную тему деградации Data Science как дисциплины. Обсуждение вызвано восприятием роста применения генеративного ИИ в аналитических задачах, что порой снижает качество и глубину анализа. Это хороший повод задуматься о балансе между автоматизацией и экспертным знанием. Новые инструменты, такие как Kokoro TTS, расширяют возможности взаимодействия с текстом, предлагая поддержку множества языков и форматов. Такие решения становятся важным дополнением к арсеналу специалистов, работающих с большими объемами мультимедийных данных.
Значительный интерес вызвали также наиболее популярные ссылки предыдущей недели, включая материал о собеседованиях в Data Science, визуализации машинного обучения и перспективы токенизации данных. Эти темы отражают актуальные вызовы и возможности для профессионального роста и образовательных инициатив. Data Science Weekly — это источник, который помогает оставаться в курсе последних тенденций и технологий, сочетая теоретические исследования и практические советы. От новичков до опытных специалистов, подписчики получают ценную информацию для развития своих навыков и адаптации к быстро меняющимся реалиям индустрии. Продолжая следить за обновлениями, эксперты и энтузиасты могут уверенно смотреть в будущее, используя интеллект, данные и технологии для решения всё более сложных задач.
Выпуск 606 – яркое подтверждение того, что мир Data Science стремительно развивается и предлагает новые возможности для творчества, инноваций и профессионального роста.