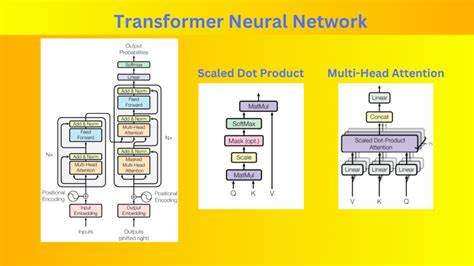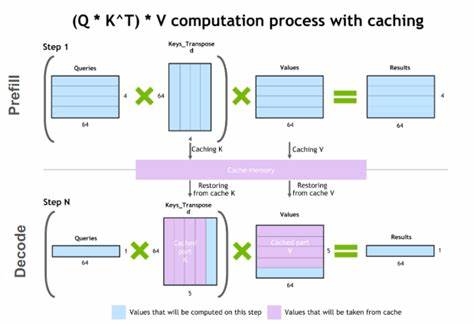
В последние годы большие языковые модели (LLM) стали неотъемлемой частью современного цифрового мира, применяясь в самых разных областях: от чат-ботов и интеллектуальных помощников до комплексных систем обработки естественного языка. Одной из важнейших задач при развертывании таких моделей является обеспечение высокой скорости отклика и эффективности работы с множеством последовательных запросов. Для решения этой задачи активно внедряются технологии кэширования, среди которых особое внимание заслуживает метод Prefix K/V Caching. Prefix K/V Caching – это специализированный подход к хранению и быстрому доступу к прошлым вычислениям модели, в частности, к предварительно обработанным префиксам запросов и ответов. Данная технология направлена на снижение избыточных вычислительных затрат при работе с многократными и временно связанными запросами, что позволяет экономить ресурсы серверов и ускорять процесс генерации ответов.
В современном ландшафте LLM-систем кэширование префиксов становится особенно актуальным в условиях, когда диалог или задача состоит из нескольких шагов, и каждый следующий запрос логически продолжает предыдущий. Благодаря хранению значений ключей и значений (key/value), относящихся к частям запросов и ответов, система избегает повторных дорогостоящих вычислений и существенно повышает производительность на многоходовых взаимодействиях. Основные типы кэшей, которые применяются в рамках Prefix K/V Caching, включают высокоскоростную кэш-память на основе HBM (High Bandwidth Memory), кэш на хост-машине, а также распределённые кэши, использующие сетевые ресурсы между вычислительными узлами. Кэширование в HBM обеспечивает минимальные задержки и высокую пропускную способность за счёт близости к GPU, однако ограничено по размеру. Наоборот, хост-машинный кэш более емкий, но уступает HBM по скорости, что создаёт необходимость в эффективной иерархии кэширования для оптимального баланса производительности и объёма.
Одним из сложных вызовов при внедрении этой технологии является обеспечение слаженной работы между кэшами на разных уровнях и поддержание их актуальности. При этом важно учесть, что префиксы запросов часто имеют временную кластеризацию, то есть запросы в рамках одного диалога или сессии связаны между собой, что требует гибкой стратегии управления Кэш-памятью, чтобы поддерживать «горячие» префиксы доступными и минимизировать потери производительности из-за очистки или устаревания данных. В связке с технологией Prefix K/V Caching современные решения выделяют подходы, при которых происходит самонастройка кэширования под размер доступной памяти сервера. Это позволяет автоматически подстраиваться под вычислительные условия и оптимизировать работу LLM-сервера без необходимости ручной настройки, что существенно облегчает масштабирование и развертывание подобных систем в продуктивных средах. Кроме традиционных индивидуальных кэшей, задействованных напрямую внутри GPU-хостов, важной тенденцией становится использование East/West (E/W) кэшей, которые делятся между несколькими вычислительными узлами внутри дата-центра для более эффективного обмена данными.
Тем не менее, данный подход сталкивается с конкуренцией за ресурсы с другими высокоприоритетными коммуникациями, например внутренними соединениями между компонентами кластера, что требует комплексных решений для балансировки загрузки и минимизации конфликтов. При этом технологии, ориентированные на расширение возможностей Prefix K/V Caching, не ограничиваются лишь аппаратными кэшами. В перспективе активно разрабатываются возможности интеграции хранилищ с объектным доступом и SSD-накопителей для повышения доступного объёма кэша за счет использования более дешевых и емких носителей при сохранении приемлемых скоростей доступа. Другим направлением развития становится стандартизация методов обнаружения и работы с кэш-данными, что способствует созданию экосистемы взаимосвязанных решений, обеспечивающих удобное и эффективное использование кэш-памяти разных типов и на разных уровнях. Особенно это актуально для крупных интеграторов и разработчиков инфраструктуры – универсальные протоколы и интерфейсы позволяют быстрее и проще встраивать технологию в существующие решения.
Важным аспектом является также управление нагрузкой на систему кэширования. Это включает в себя реализацию механизмов обратного давления (backpressure), которые обеспечивают сбалансированное наполнение кэша и предотвращают его переполнение, а также поддержку актуальных данных для избежания ситуаций с устаревшей информацией, что критично для непрерывной и стабильной работы LLM-сервисов. Использование кэширования префиксов в LLM открывает новые возможности в сфере многократных обращений и диалоговых взаимодействий, позволяя не только ускорить отклик, но и значительно снизить требования к вычислительным ресурсам. Такой подход способствует более экономичному использованию дорогостоящих вычислительных архитектур, включая GPU и TPU, а также облегчает масштабируемость систем, что крайне важно в условиях растущей нагрузки и увеличивающейся сложности моделей. В итоге, Prefix K/V Caching представляет собой ключевой элемент современной архитектуры работы с большими языковыми моделями, направленный на повышение эффективности, масштабируемости и надежности их эксплуатации.
Внедрение продвинутых методов кэширования позволяет создавать более отзывчивые, адаптивные и экономичные решения, что является критическим для успешного применения LLM в различных сферах бизнеса и науки.