Машинный перевод давно считается одной из самых сложных задач в области обработки естественного языка. С развитием глубокого обучения технологии перевода значительно продвинулись вперёд, но по-прежнему оставались трудности, связанные с качеством и скоростью обработки текстов. Своеобразным прорывом в этой сфере стала архитектура трансформер, предложенная в 2017 году, которая полностью изменила подход к переводу и обработке последовательностей. Благодаря исключению рекуррентной обработки и внедрению инновационного механизма внимания трансформер позволяет эффективно параллелить вычисления и достигать высокого качества перевода даже при обучении на гигантских объемах данных. В основе трансформера лежит идея само-внимания, которая заменяет последовательное считывание текста системой RNN (рекуррентных нейронных сетей).
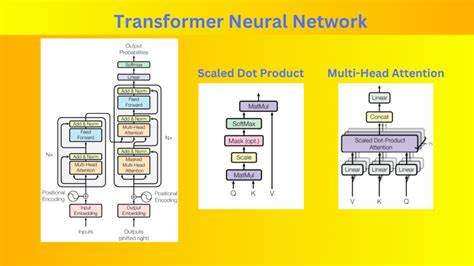
Ранее при использовании RNN каждый токен обрабатывался по очереди, что ограничивало скорость обучения и не позволяла в полной мере захватывать сложные зависимости между словами в предложении. Трансформер же способен обрабатывать весь входной текст параллельно, что значительно ускоряет обучение и повышает качество извлечения смысловых связей между словами. Концепция само-внимания подразумевает, что каждый элемент входной последовательности одновременно становится и запросом, и ключом, и значением в механизме внимания. Этот подход помогает модели взвешивать важность каждого слова относительно других в разных контекстах перевода. Для усиления возможностей внимательной обработки текстов трансформер использует многоголовое внимание, благодаря которому система может одновременно рассматривать несколько аспектов связи между словами, например, синтаксический, семантический и морфологический контексты.
Такой механизм позволяет модели лучше улавливать разные уровни смысла и структуры фраз. Помимо внимания, важной частью архитектуры является позиционное кодирование, которое компенсирует отсутствие рекуррентного порядка. Оно вводит дополнительную информацию о позиции каждого слова в последовательности, что позволяет системе учитывать порядок слов и сохранять смысл при изменении структуры предложения. Также трансформер включает в себя несколько слоев глубокой обработки, где каждый слой содержит механизм внимания, нормализацию и позиционно независимую полностью связанную сеть с нелинейными активациями. Важным техническим элементом стала реализация остаточных связей, которые облегчают обучение глубоких сетей и предотвращают затухание градиентов.
При работе с задачей машинного перевода трансформер разделён на две основные части: энкодер и декодер. Энкодер последовательно преобразует входной текст, извлекая из него значимые признаки, а декодер генерирует перевод, используя как внутреннее представление исходного текста, так и уже сгенерированные слова в целевом языке. Одной из ключевых особенностей декодера является маскированное внимание, при котором он не может видеть будущие токены в процессе генерации перевода, что гарантирует корректное предсказание последовательности токенов в режиме автопрогнозирования. Кроме того, реализуется перекрёстное внимание декодера к выходам энкодера, что помогает находить соответствия между исходными и целевыми словами при переводе. В сравнении с предыдущими системами на базе RNN, трансформер оказался более эффективным и точным.
Отсутствие последовательной обработки позволяет лучше использовать вычислительные ресурсы современных GPU, что отражается в значительно более высокой скорости обучения. На практике модели на основе трансформера достигают лучших оценок BLEU на стандартных датасетах для перевода, таких как WMT'14. Также архитектура трансформера более устойчива к проблемам запоминания длинных зависимостей в тексте, которые часто затрудняли обучение рекуррентных моделей. Разработчики экспериментировали с вариациями архитектуры, включая модели только с декодером, популярные в LLM (больших языковых моделях) типа GPT. Такие модели, хотя и уступают классической энкодер-декодерной структуре в некоторых задачах, при правильной настройке могут эффективно справляться и с переводом, демонстрируя гибкость и универсальность архитектур на основе внимания.
Оптимизация обучающих процедур, таких как использование функции GELU вместо ReLU и внедрение пред-слойной нормализации, улучшает стабильность и скорость сходимости моделей. Подобные усовершенствования стали стандартом в современных трансформерах и способствуют более быстрому достижению высоких результатов. Одной из задач трансформерных моделей остаётся высокая требовательность к вычислительным ресурсам, обусловленная квадратным ростом памяти из-за хранения матриц внимания по длине контекста. Однако продолжающиеся исследования и инженерные решения, включая разреженное внимание и различные методы сжатия контекста, направлены на снижение этих ограничений. В итоге, трансформер стал фундаментом не только для машинного перевода, но и для широкого спектра задач в области обработки естественного языка, включая генерацию текста, анализ тональности, ответы на вопросы и создание мультимодальных систем.
Его способность обрабатывать длинные последовательности параллельно и эффективно связывать в них важные элементы обеспечивает высокую производительность и гибкость. Таким образом, архитектура трансформера представляет собой революционный шаг в развитии искусственных нейронных систем. Для машинного перевода она предлагает более точное и быстрое преобразование языков, что открывает новые возможности для создания качественных и масштабируемых систем автоматического перевода в различных сферах — от повседневного общения и бизнеса до наук и культуры. С появлением все более мощных вычислительных платформ и оптимизированных моделей трансформеры продолжают совершенствоваться, делая машинный перевод еще более доступным, надёжным и естественным для пользователей по всему миру.