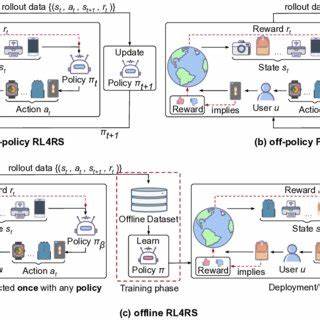
Обучение агентов с подкреплением (Reinforcement Learning, RL) становится все более значимым направлением исследований и практических разработок в области искусственного интеллекта. Одним из ключевых аспектов успешного применения RL является сбор и использование данных, на основании которых агент учится принимать решения. Традиционно обучение происходит в интерактивном режиме, когда агент начинает с нуля и в режиме реального времени взаимодействует со средой, постепенно улучшая свою стратегию. Однако такой подход требует значительных вычислительных ресурсов и времени, а также может быть непрактичен или невозможен в ряде случаев. В таком контексте особое внимание приобретает концепция offpolicy обучения и генерация офлайн данных, которые позволяют значительно расширить возможности и эффективность обучения RL агентов в различных средах.
Offpolicy обучение в RL означает тренировку агента на основе данных, собранных не текущей стратегией агента, а с помощью другой политики. Это дает возможность использовать ранее накопленные данные, собранные другими алгоритмами, экспертами или случайным образом, для улучшения текущей модели. Особенно ценно это в тех случаях, когда взаимодействие с реальной средой дорогостоящее, небезопасное или ограниченное по времени. Генерация офлайн данных позволяет заранее собрать набор траекторий или опытов — последовательностей состояний, действий и полученных вознаграждений — которые затем используются для тренировки модели. Важным преимуществом такого подхода является возможность параллелить процесс сбора данных на разных устройствах или средах и повторно использовать данные для улучшения эффективности обучения.
Для генерации офлайн данных применяется множество стратегий. Одной из основных является запуск различных политик, включая случайные, жадные или смешанные подходы, которые создают разнообразный и репрезентативный датасет по возможным состояниям среды. Это необходимо для качественного обобщения, поскольку RL агенту предстоит справляться не только с привычными, но и с нестандартными ситуациями. В условиях, когда среда сложна, динамична или непредсказуема, оффлайн данные обеспечивают стабильность обучения и снижают риски переобучения на ограниченном опыте. Дополнительным плюсом является возможность проведения детального анализа и оценки политик без постоянного взаимодействия с тестовой средой, что ускоряет разработку и внедрение решений.
Также использование оффлайн политик особенно полезно для обучения автономных систем, роботов и других интеллектуальных агентов в условиях, где онлайн обучение может привести к ошибкам с серьезными последствиями. Одной из современных тенденций в области RL является интеграция offpolicy методов с глубокими нейронными сетями, что открывает простор для создания сложных моделей поведения и принятия решений в непредсказуемых сценариях. Соединение оффлайн данных с глубоким обучением помогает создавать агенты, способные к быстрому адаптивному обучению за счет обширного предобученного опыта и эффективно использовать его без необходимости полного перезапуска обучения с нуля. Однако несмотря на многочисленные преимущества, генерация и использование оффлайн данных требуют тщательного подхода к качеству и разнообразию собираемого опыта. Слабая вариативность данных, ошибки в аннотации или несоответствие реальным условиям среды могут привести к снижению производительности агента и появлению неожиданных сбоев.
Поэтому современные исследования уделяют внимание методам оценки и фильтрации оффлайн данных, а также разработке алгоритмов, способных эффективно работать с неидеальной информацией. Потенциал применения offpolicy обучения и офлайн данных в области RL огромен. Уже сегодня такие технологии находят применение в финансовых моделях, управлении робототехникой, автономных транспортных средствах, системах рекомендаций и многом другом. Они позволяют сэкономить ресурсы, повысить безопасность экспериментов и ускорить выход на рынок инновационных решений. В целом, offpolicy обучение и генерация офлайн данных представляют собой важный шаг в эволюции методов искусственного интеллекта.
Они открывают возможности для создания более устойчивых, адаптивных и эффективных агентов, способных справляться с вызовами реального мира. В ближайшем будущем грамотное применение этих подходов станет одним из ключевых факторов успеха в области интеллектуальных систем и автоматизации процессов во многих сферах экономики и науки.