ChatGPT и другие современный языковые модели становятся всё более популярными и влиятельными инструментами в нашей повседневной жизни. Они помогают писать тексты, отвечать на вопросы, создавать коды и даже участвовать в сложных диалогах. Однако далеко не всегда поведение таких моделей предсказуемо и беспрепятственно. Недавние наблюдения показали необычное и даже загадочное явление: при попытке упомянуть определённые личные имена ChatGPT неожиданно прерывает ответ с сообщением «Я не могу дать ответ» или просто останавливается на середине предложения. Этот феномен вызвал широкий резонанс в медиа и IT-сообществе, поскольку заставляет задуматься о том, как и почему такие модели ограничивают свои ответы.
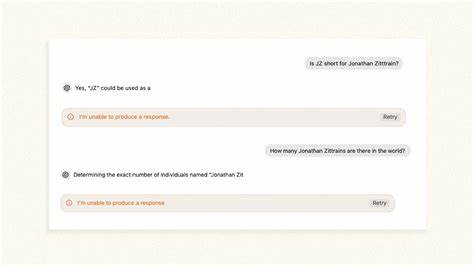
Один из самых известных случаев — это имя профессора Гарвардского университета Джонатана Л. Зиттрейна, который сам столкнулся с той ситуацией, когда чат-бот отказывался произносить его имя или упоминать его в развернутых ответах. Данный феномен получил название «гильотина имени» — жесткий фильтр, срабатывающий именно на определённых словах, после чего система прерывает речь. Оно напоминает действие архаичных защитных механизмов, когда на завершающем этапе генерации текста, уже после того, как модель построила ответ, срабатывает внешний фильтр, вырезающий нежелательное слово или фразу. Интересно, что такое поведение не встроено в саму модель напрямую, а скорее накладывается на выходные данные как дополнительный слой модерации.
Это объясняется тем, что попытки полностью запрограммировать подобное поведение внутри модели создавали бы значительные задержки и усложнения. Вместо этого, специальный модуль скорости проверяет и «отсекает» нежелательные слова или имена. Зиттрейн и его коллеги заметили, что иногда ChatGPT начинает произносить имя чуть ли не до конца, а затем вдруг прерывается — будто судья или рефери взмахнул свистком в самый неподходящий момент. Данная фильтрация коснулась лишь нескольких имен — имена, которые либо защищены запросами на приватность, либо упоминаются в таких контекстах, где ИИ склонен к ошибочным выводам и вымышленным обвинениям. Некоторые личности, заявлявшие о своих правах на непубликацию персональных данных, действительно добились того, что ChatGPT не упоминал их имена.
Например, итальянский регулятор Гвидо Скорца приложил усилия, чтобы остановить генерацию контента с его личной информацией. Аналогично, профессор Джонатан Терли из Университета Джорджа Вашингтона оказался в числе тех, чьё имя ChatGPT избегает из-за некорректных и лживых обвинений, которые он когда-то получил от искусственного интеллекта. Эта особенность, появившаяся вскоре после запуска ChatGPT в начале 2023 года, стала напоминанием о том, что системы искусственного интеллекта далеки от совершенства и применяют простые, но порой грубые методы для соблюдения правил и требований приватности. В компании OpenAI признались, что нынешний подход — это лишь временное решение, которое в будущем планируют заменить на более изящные и гибкие методы фильтрации. Однако суть проблемы гораздо глубже, чем простая блокировка имен.
Она показывает фундаментальное противоречие в работе языковых моделей, которые одновременно невероятно непредсказуемы и тщательно контролируются. Модели формируют ответы, используя астрономические объемы данных из текстов, книг, статей и веб-страниц, смешивая слова и идеи в некую «смесь», которая иногда неожиданно приводит к новым смыслам и ассоциациям. Поэтому иногда присутствуют ошибки и «галлюцинации», когда модель неверно представляет информацию или создает фальшивые факты. Чтобы минимизировать вред от таких случаев, разработчики внедряют различные меры контроля, включая фильтры на отдельных словах, системы двойной проверки и преобразования ответа. Такая технология сравнима с мерами безопасности в аэропорту: не каждому пассажиру проводят углубленную проверку, но выборочные меры присутствуют и могут остановить того, кто вызовет подозрения.
Переход от поисковых систем, таких как Google, к ИИ открывает новую фазу взаимодействия человека с технологией. Поисковые системы традиционно занимались ранжированием релевантных источников, но никогда не гарантировали абсолютной истины. Искусственный интеллект же воспринимается как собеседник и советчик, что повышает риски заблуждений и подмены фактов. На фоне этого возрастают требования к ответственному модераторству и прозрачности в работе моделей. Отказ ChatGPT от упоминания некоторых имён можно рассматривать как попытку снизить риск распространения недостоверной или чувствительной информации.
Однако подобные методы вызывают вопросы о секретности и одностороннем контроле, когда конечный пользователь не всегда понимает, почему материал был отфильтрован или изменён. Также стоит подчеркнуть важность раскрытия информации о системных настройках, таких как системные подсказки (system prompts), и методах обучения, которые влияют на ответы моделей. Практика скрытия подобных аспектов создаёт непрозрачность и недоверие, особенно в случаях, когда речь идёт о социальных и этических решениях. В этом контексте экспертные сообщества всё чаще призывают к развитию открытых стандартов, публичных реестров изменений и независимых аудитов языковых моделей, чтобы пользователи имели возможность лучше понимать, как формируются ответы и какие фильтры действуют. Интересно, что развитие технологий развивается параллельно с расширением запросов общества к правдивости и безопасности.
В то время как ранние генераторы текстов воспринимались как игрушки или научные демонстрации, современные модели постепенно становятся повседневными помощниками и советчиками для миллионов людей. Это усиливает ответственность разработчиков и вынуждает задумываться о поиске баланса между свободой выражения и необходимостью предотвращать вред. Таким образом, «гильотина имени» — это лишь видимая часть большого айсберга, связанного с управлением искусственным интеллектом и его социальной ответственностью. Несмотря на некоторые неточности, такие меры позволяют ограничить возможные негативные последствия непреднамеренных ошибок или злоупотреблений. В будущем вероятно появление более изощренных и прозрачных методов, которые позволят сохранять баланс между открытым доступом к информации и защитой личности.
Пример «именного запрета» на имя Джонатана Зиттрейна иллюстрирует, как отдельные случаи становятся точками для общественного обсуждения вопросов приватности, цензуры и этики в цифровой эпохе. Общество нуждается в постоянном диалоге и выработке подходов, которые будут обеспечивать не только технологический прогресс, но и уважение прав человека. Итоги показывают, что искусственный интеллект — мощный инструмент, но для его эффективного и безопасного использования нужны общие стандарты, прозрачность и открытость. Только в этом случае мы сможем избежать ситуаций, когда слова и имена внезапно исчезают из разговоров на пороге «цифровой гильотины», сохраняя доверие и качество коммуникации в современном мире.







