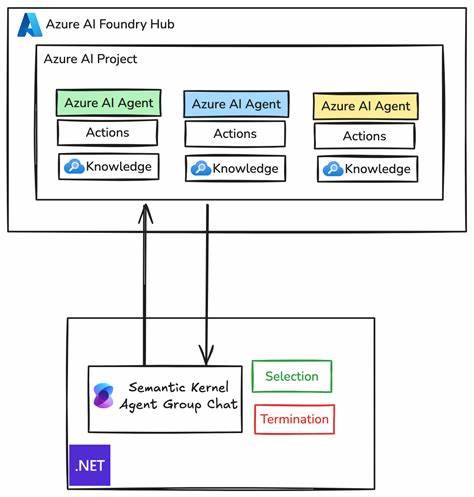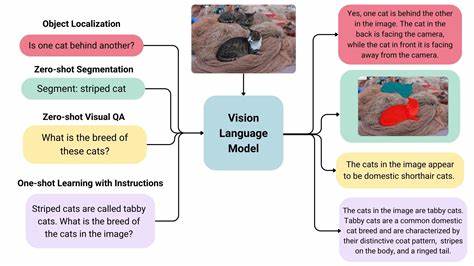
Современные технологии на стыке машинного зрения и обработки естественного языка стремительно меняют представление о системах навигации, особенно в условиях закрытых помещений, где традиционные методы позиционирования имеют ограничения. Создание внутренних карт, способных интерактивно и точно определять местоположение пользователя, становится реальностью благодаря визуально-языковым моделям (VLM). Эта категория моделей искусственного интеллекта, совмещающая визуальную информацию и тексты, позволяет машинной системе не только видеть, но и понимать содержимое изображений. Такой прогресс открывает дверь к новым решениям в области внутренней локализации, где фотография может стать основой для точного определения позиции внутри сложных пространств, например, крупных торговых центров, офисных зданий или музеев. Исторически системы внутренней локализации опирались на такие технологии, как Bluetooth Low Energy (BLE) маячки или Wi-Fi трекинг, позволяющие с определённой точностью отслеживать устройство пользователя.
Однако эти методы зачастую требуют специального оборудования и могут быть нерентабельными или неточными в деталях, таких как дифференциация конкретных зон или комнат. Благодаря VLM появилась возможность создавать более интеллектуальные и доступные системы, использующие изображения, сделанные на смартфон, для понимания окружения и определения места нахождения пользователя. Основой подхода является использование фотографии, сделанной в интерьере, и сопоставление распознанных на ней объектов с заранее размеченной картой или планом здания. Сначала пространство разбивается на ключевые области – коридоры, магазины, санитарные узлы и другие объекты, а затем для каждой точки внутри коридора определяется набор видимых магазинов или ориентиров в зависимости от направления обзора. Это позволяет формировать карту доступных «визуальных признаков» с привязкой к реальным координатам пространства.
Процесс разметки пространства и аннотирования объектов можно существенно упростить с помощью современных подходов к программированию, таких как «vibe coding», позволяющего быстро создавать специализированные инструменты для разметки, адаптированные под конкретную задачу. Эти инструменты помогают не только определить местоположение и тип объекта на карте, но и собрать данные о том, какие ориентиры видны с каждой позиции и направления, что важно для будущего сопоставления с изображением пользователя. После сбора и разметки данных необходим алгоритм, способный анализировать фото с камеры и извлекать из него список видимых объектов, например названия магазинов или уникальные визуальные характеристики. В этой задаче хорошо себя показали современные API и VLM, которые могут извлекать из изображения семантическую информацию, определять текст на вывесках и другие характерные детали. Полученная информация сортируется и нормализуется, чтобы далее сопоставляться с предобработанными позициями и ориентирами на карте.
Важным аспектом метода является сопоставление «видимых» с позиции объектов с тем, что обнаружено на фотографии. В результате этой операции формируется набор возможных положений пользователя в пространстве, каждая из которых представлена как точка на карте с определённым направлением взгляда. Хоть на начальном этапе этот метод может давать несколько возможных локаций, ближе к истинному положению пользователя, дальнейшие улучшения — интеграция видео, данных с сенсоров смартфона и использование фильтров частиц — способны значительно повысить точность. Практическая демонстрация подхода показала впечатляющие результаты. Простое фото определённого участка торгового центра, сделанное на смартфон, позволило локализовать пользователя с удивительной точностью, несмотря на наличие некоторой неоднозначности.
Это подтверждает потенциал визуально-языковых моделей не только как инструментов для распознавания изображений, но и как основы для систем позиционирования в реальном времени. Несмотря на успехи, разработка полноценной системы внутренней навигации на базе VLM сталкивается с рядом вызовов. К ним относятся необходимость поддержания актуальности карт и аннотаций, вариативность освещения и условий съёмки, а также обработка изображений с частично закрытыми или изменёнными объектами. Кроме того, для полноценной реализации таких решений требуется интеграция с другими источниками данных и сенсорами, что повысит надёжность и стабильность определения позиции. Вопросы экологии и ресурсов также заслуживают внимания.
Тренировка и использование больших моделей искусственного интеллекта требуют значительных вычислительных мощностей, которые оказывают влияние на энергопотребление. Поэтому важно искать баланс между функциональностью и эффективностью, начиная с прототипов и переходя к оптимизированным реализациям. С появлением новых AR-устройств и увеличением вычислительных возможностей смартфонов, потенциал использования VLM для внутренних навигационных систем только возрастёт. Это позволит создавать более интуитивные и персонализированные решения для пользователей, помогая им ориентироваться в сложных пространствах без необходимости иметь при себе дополнительное оборудование. Перспективы применения данной технологии выходят за рамки торговли и навигации покупателей в торговых центрах.
Робототехника, особенно в условиях помещений, где GPS недоступен, может выиграть от подобной локализации, совершенствуя алгоритмы перемещения и взаимодействия с окружающей средой. Также могут появиться инновационные игровые и образовательные приложения, основанные на глубоком понимании внутреннего пространства. В заключение стоит подчеркнуть, что прототипирование внутренних карт с использованием визуально-языковых моделей — это пример того, как современные технологии искусственного интеллекта начинают воплощать в жизнь концепции, которые ещё несколько лет назад казались фантастикой. Пусть текущие решения пока находятся на этапе экспериментов и требуют доработки, открывающиеся горизонты и возможности вдохновляют на дальнейшие исследования и разработки, которые в ближайшем будущем смогут значительно улучшить качество и удобство внутренней навигации в самых разных сферах жизни.