Большие языковые модели (LLM) уже давно становятся неотъемлемой частью современного цифрового мира. Они используются в поисковых системах, чат-ботах, системах перевода и многих других сферах. Несмотря на впечатляющие успехи, многие LLM сталкиваются с проблемой так называемых галлюцинаций - ситуацию, когда модель уверенно выдаёт ложную либо недостоверную информацию. Эта проблема в значительной мере подрывает доверие к ИИ и ограничивает возможности его широкого применения, особенно в критически важных областях, таких как медицина, юриспруденция и образование. Однако новые исследования предлагают эффективное решение, позволяющее повысить точность и надёжность LLM без привлечения внешних баз данных или дополнительного обучения моделей.
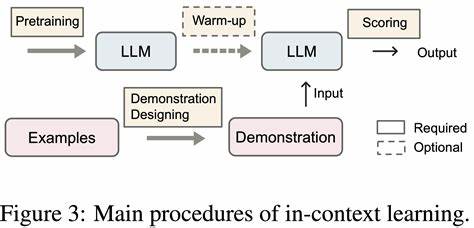
Говорится о подходе, при котором используется информация не только из последнего слоя модели, но и из всех промежуточных слоёв - метод, известный как Self Logits Evolution Decoding (SLED). Большие языковые модели устроены по принципу трансформеров и состоят из многих слоёв, которые последовательно обрабатывают ввод. Каждый слой генерирует числовые значения, называемые логитами, которые в конечном итоге позволяют модели выбрать следующий токен (слово или часть слова) для формирования ответа. Обычно при создании текста учитывается только логит последнего слоя, а все предыдущие промежуточные данные игнорируются. Но именно здесь часто таится корень ошибок и некорректных ответов.
Задействование же всех слоёв даёт несколько мнений модели на каждый шаг генерации, что позволяет выявлять потенциальные ошибки и более точно интерпретировать контекст. Новая техника SLED заключается в том, что логиты каждого слоя преобразуются с помощью того же финального проекционного слоя, что и последний слой. Это приводит к получению вероятностных распределений токенов для каждого слоя, из которых затем формируется усреднённое и взвешенное по важности распределение. Такое объединение информации разных этапов работы модели позволяет скорректировать слишком уверенные и ошибочные предсказания, опираясь на более глубокий контекст и внутренние представления, которые предыдущие слои уже сформировали. Практический пример помогает лучше понять преимущества SLED.
Рассмотрим задачу из области математики - вычисление стоимости покупки с условием скидки. Традиционная модель может предсказать простую арифметическую операцию, не учитывая скидку, потому что на основании статистики из обучающих данных это более распространённый сценарий. Но промежуточные слои, анализируя информацию глубже, могут "заподозрить" необходимость дополнительного действия. Объединяя их мнения, SLED позволяет LLM сгенерировать правильное решение, включающее применение скидки, и тем самым дает корректный результат. Этот подход успешно протестирован на нескольких языковых моделях, включая GPT-OSS, Mistral и Gemma, а также показал универсальность при работе как с базовыми, так и дообученными моделями.
На различных тестовых наборах данных, включая задачи с выбором из множества вариантов и открытые вопросы, SLED продемонстрировал значительное повышение точности, вплоть до 16 процентов по сравнению с традиционными методами декодирования и другими техниками улучшения достоверности, например DoLa. Одной из важных особенностей SLED является отсутствие необходимости привлечения дополнительных внешних знаний или дообучения модели. Это значительно упрощает внедрение метода в существующие системы, экономит ресурсы и сохраняет масштабируемость решений. Единственным незначительным минусом является незначительное увеличение времени генерации текста - примерно на 4 процента, что в реальных условиях почти незаметно для пользователя, учитывая ценность улучшенной качества ответов. Помимо повышения фактической точности, метод SLED также совместим с другими техниками декодирования, что делает его гибким инструментом для комплексного решения проблемы галлюцинаций.
Его можно комбинировать с уже существующими алгоритмами, что усиливает защиту от появления неправдоподобной информации и повышает общую надёжность LLM. Перспективы развития этой технологии очень широки. В ближайшем будущем возможно интегрирование SLED с методами контролируемого обучения и адаптации моделей под специфические задачи и домены. Также интересны направления, связанные с расширением применения принципов мультислойного декодирования на другие типы данных и задач, включая визуальные вопросы, генерацию программного кода и создание длинных текстов. Таким образом, инновационный подход, основанный на использовании логитов всех слоёв языка, открывает новые горизонты для повышения качества и достоверности ответов больших языковых моделей без необходимости усложнять архитектуры и увеличивать требования к аппаратному обеспечению.
Это важный шаг к более интеллектуальным, надежным и доверительным системам искусственного интеллекта, которые смогут эффективно помогать людям в разнообразных сферах жизни и бизнеса. .