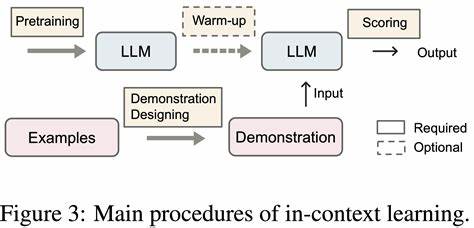
В современном мире искусственный интеллект стремительно развивается, открывая новые горизонты и меняя наш взгляд на технологии. Одним из наиболее обсуждаемых феноменов последнего времени стало обучение в контексте, или In-Context Learning (ICL) - способность моделей автогрессионного типа решать задачи, опираясь лишь на примеры, приведённые в запросе, без дополнительного обучения. Эта особенность вызывает живой интерес и вопросы о том, можно ли считать обучение в контексте полноценным процессом обучения в традиционном понимании. Ключевой смысл ICL заключается в умении модели обрабатывать представленные ей "на лету" примеры и использовать их для генерации ответов, фактически запоминая и применяя паттерны из текущего запроса. При этом сама модель не претерпевает изменений в своих весовых коэффициентах, то есть не происходит классического обновления параметров, что отличает ICL от привычного процесса обучения.
Многие исследователи отмечают, что такая способность моделей исключительно через подачу нескольких примеров в промпт позволяет им показывать впечатляющие результаты в решении новых задач. Однако возникает дискуссия, насколько данный феномен можно отнести к процессу обучения, ведь модель опирается в первую очередь на уже заложенные в неё знания, полученные на этапе предварительного тренинга, а не приобретает новые в результате взаимодействия с текущим запросом. С математической точки зрения, обучение в контексте можно рассматривать как разновидность обучения, поскольку модель внутри себя как бы адаптируется к задаче, используя внутреннее представление и входящие данные, но без явного изменения параметров. Это делает ICL мощным инструментом, позволяющим гибко и быстро переключаться между задачами при помощи минимальных примеров, что обладает огромным потенциалом в разных областях. Одним из важных аспектов, выявленных в практических исследованиях, является то, что эффективность ICL сильно зависит от качества и количества подаваемых примеров.
Чем больше примеров в контексте, тем надёжнее и точнее модель способна делать предсказания, но рост числа примеров не всегда линейно улучшает результаты, иногда они становятся менее чувствительны к нюансам структуры и стиля подачи запросов. Кроме того, при большом количестве примеров модель начинает вычленять закономерности из текста, что может приводить к избирательной чувствительности к распределению данных и особенностям формулировок. Важную роль играет и стиль, в котором построен запрос или подаются примеры - например, цепочка рассуждений (chain-of-thought), которая часто значительно улучшает качество ответов, но одновременно повышает зависимость от форматирования и формулировок. При этом, несмотря на заметные успехи, исследование показывает, что обучение в контексте не является универсальным решением и не обладает полноценной способностью к обобщению на новые, принципиально отличающиеся задачи. Модель остаётся ограниченной в своей способности к адаптации, поскольку базируется на информации, заложенной при предварительном обучении, и не в состоянии полностью перестроить внутренние представления для радикально новых условий.
Нельзя не отметить, что традиционные методы обучения с обновлением весов, или fine-tuning, по-прежнему остаются важнейшей составляющей долгосрочного улучшения моделей. Они обеспечивают более устойчивое и глубокое понимание новых данных, чего не хватает подходу ICL, воспринимающему задачи скорее как шаблоны в контексте с ограниченной памятью. Помимо теоретических аспектов, обучение в контексте уже нашло реальное применение в сфере обработки естественного языка, генерации текстов, перевода, а также в более сложных интеллектуальных задачах. Это позволяет создавать интерактивные системы с быстрым откликом и адаптацией к пользовательским запросам без необходимости переобучения моделей, что значительно экономит ресурсы и время. В целом, обучение в контексте представляет собой важный шаг вперёд в развитии искусственного интеллекта, расширяя представления о том, как машины могут демонстрировать гибкость и адаптивность.
Несмотря на то, что это не классическое обучение в строгом смысле, его эффективность и потенциал трудно переоценить. Множество открытых вопросов требует дальнейших исследований, особенно в области улучшения общих способностей к генерализации и снижении зависимости от стиля и структуры примеров. В будущем комбинация ICL с другими методами и подходами, вероятно, приведёт к созданию ещё более мощных и универсальных интеллектуальных систем. Таким образом, обучение в контексте - это инновационный механизм, который расширяет горизонты возможностей языковых моделей, позволяя им решать задачи быстро и эффективно, но при этом он не является абсолютной заменой традиционному обучению. Он скорее дополняет существующие методы, предлагая новый взгляд на то, как можно использовать знания и адаптироваться к разнообразным проблемам, стоящим перед современными системами искусственного интеллекта.
.