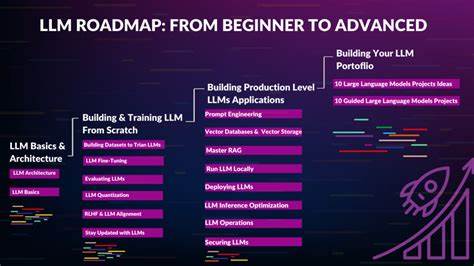
В последние годы большие языковые модели (LLM) стали ключевым направлением в области искусственного интеллекта и обработки естественного языка. Многие специалисты и энтузиасты стремятся понять, как работают эти модели, и научиться строить, обучать и внедрять собственные LLM. Однако путь к освоению этой технологии часто путает неподготовленных новичков массивом теоретических предпосылок и сложных концепций. В этой статье раскрывается оптимальный план обучения большим языковым моделям, позволяющий избежать излишней теоретической нагрузки и сосредоточиться на действительно необходимых знаниях и навыках. Освоение больших языковых моделей – задача многоуровневая, где важно не просто знать теорию, а понимать суть, приобретать практические умения и уметь применять полученные знания в реальных проектах.
Именно такой подход обеспечивает уверенное продвижение от основ к сложным темам и выводит на уровень построения полноценной модели. Основой для понимания LLM является фундаментальная математика: линейная алгебра и теория вероятностей, необходимые для работы с нейронными сетями и трансформерами. Для того чтобы не погружаться в традиционные сложные математические курсы, хороший старт — это визуальные и интуитивные объяснения в формате видео и интерактивных лекций. Например, серия образных видео, доступных на YouTube-каналах с объяснениями линейных преобразований и вероятностных концепций, помогает быстро усвоить базовые элементы. Сочетание визуализации и простых примеров глубоко формирует понимание того, как работают матрицы и вероятности в контексте обучения моделей.
Параллельно с изучением математических основ стоит погружаться в практические методы, связанные с языком программирования Python и фреймворком PyTorch. В современном мире машинного обучения именно эти инструменты являются стандартом для разработки и экспериментирования с нейронными сетями. Лучший способ построить фундамент – самостоятельное создание autograd-системы с нуля для понимания управления вычислительными графами, что можно реализовать через микро-проект, подобный Micrograd, разработанный известным специалистом в области ИИ. Такой проект дает не только понимание автоматического дифференцирования, но и подготовку к обучению более сложных архитектур. Следующий этап — освоение архитектуры трансформеров, без которых невозможна работа современных LLM.
Трансформеры базируются на ключевых концепциях — токенизации, эмбеддингах и механизме внимания. Изучение начинается с визуальных объяснений, затрагивающих принципы self-attention и последовательность операций, которые позволяют моделям эффективно обрабатывать текст. Понимание разницы между методами предобучения, как BERT с Masked Language Modeling (MLM) и GPT с Causal Language Modeling (CLM), помогает ориентироваться в различных подходах и их применении. Приобретение этих знаний подкрепляется проектом по созданию мини-GPT — простейшей, но полностью работоспособной модели трансформера, построенной с нуля. Для того чтобы LLM действительно стали мощным инструментом, важно освоить вопросы масштабирования и обучения на больших данных.
Изучение «законов масштабирования» демонстрирует, как увеличение параметров и данных влияет на качество модели и производительность. Понимание этих принципов подкрепляется изучением распределённого обучения, которое позволяет использовать несколько GPU одновременно. Техники, такие как Data Parallelism, Tensor Parallelism и Pipeline Parallelism, позволяют распределять вычислительную нагрузку и оптимизировать процесс обучения. Реальная практика с использованием инструментов, таких как HuggingFace Accelerate, позволяет выявить узкие места и научиться их преодолевать, что является критичным навыком для реальных проектов. Еще один важный аспект — адаптация и дообучение моделей для специфических задач.
Технологии RLHF (обучение с подкреплением с помощью человеческой обратной связи) и конституционального ИИ (Constitutional AI) призваны повысить качество генерации и следование этическим стандартам. Параллельно раскрывается тема Parameter-Efficient Fine-Tuning (PEFT), которая позволяет проводить дообучение моделей с минимальными затратами ресурсов. Особенно популярными в этой области являются методы LoRA и QLoRA, где пользователь учится эффективно изменять лишь небольшую часть модели, сохраняя при этом высокую производительность и снижая энергозатраты. Практические навыки приходят с реализацией LoRA с нуля, внедрением адаптеров в открытые модели и их тонкой настройкой на конкретных данных. Завершающий этап — производство и внедрение моделей в реальные приложения с акцентом на оптимизацию процесса вывода (инференса).
Скорость реакции модели и потребление ресурсов напрямую влияют на пользовательский опыт и себестоимость сервиса. Современные подходы включают FlashAttention — ускоренный механизм внимания, а также техники квантования и другие методы оптимизации, которые позволяют добиваться ответов за доли секунды на обычном оборудовании. Погружение в эти технологии дает специалистам необходимые знания и инструменты для создания коммерчески успешных решений. Для эффективного освоения всех этапов обучения LLM важно использовать структурированный и многоуровневый подход. Сначала стоит понять концепции и построить интуицию с помощью визуальных и простых объяснений.
Затем — углубиться в теорию с помощью академических лекций и полноценных курсов. После этого — выполнять практические проекты, которые закрепляют знания и позволяют столкнуться с реальными проблемами и тонкостями построения моделей. Наконец — перейти к чтению и анализу профильных научных статей, чтобы оставаться на острие современных исследовательских тенденций. В качестве ключевых источников информации и обучения рекомендуются видео-подборки 3Blue1Brown, лекции Карпатса по нейросетям, полные курсы из Стэнфордского университета по NLP, а также оригинальные статьи, включая «Attention Is All You Need», работы по масштабированию нейросетей и статьям по адаптивному обучению. Для практики доступны разнообразные открытые проекты и библиотеки, такие как HuggingFace, PyTorch и инструменты для распределённого обучения.







