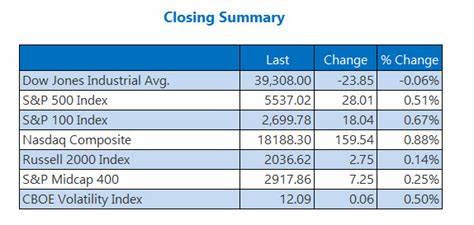
Nvidia продолжает традицию выпуска масштабных и высокопроизводительных графических процессоров с выпуском архитектуры Blackwell, которая закрепила статус компании как одного из ведущих игроков на рынке GPU. Новый флагманский чип GB202 занимает рекордные 750 квадратных миллиметров и содержит 92,2 миллиарда транзисторов, что делает его одним из крупнейших монолитных графических процессоров, когда-либо созданных. Такой масштаб позволяет Nvidia значительно увеличить количество вычислительных блоков и память, что в совокупности обеспечивает фантастическую производительность и пропускную способность. В центре внимания стоит RTX PRO 6000 Blackwell — самая мощная конфигурация на базе GB202, которая наряду с моделью RTX 5090 возглавляет модельный ряд Nvidia в 2025 году. Структура GPU включает 188 потоковых мультипроцессоров (Streaming Multiprocessors, SM), которые играют роль аналогов процессорных ядер, только в пределах GPU, предоставляя параллельные вычислительные мощности.
В сравнении с предшественниками и конкурентами, такими как AMD Radeon RX 9070 на архитектуре RDNA4, Blackwell предлагает колоссальное преимущество благодаря значительному увеличению числа ядер, объема кэш-памяти и пропускной способности видеопамяти. На аппаратном уровне архитектура Blackwell сохранила некоторые успешные решения предыдущих поколений, но вместе с тем предложила улучшения, повышающие эффективность и гибкость. Процессоры Blackwell оснащены 128 МБ кэш-памяти второго уровня (L2), что почти вдвое превосходит предыдущие поколения, и обеспечивают суммарную пропускную способность VRAM на уровне 1,8 ТБ/с благодаря использованию 96 ГБ GDDR7 с частотой передачи данных 28 Гбит/с и 512-битной шине памяти. Такая конфигурация улучшает обработку больших объемов данных и способствует лучшей производительности в рабочих и игровых приложениях. Особый интерес вызывают инновации, связанные с распределением задач внутри GPU.
Nvidia применила соотношение графических процессорных кластеров (GPC) к SM 1:16, что позволяет масштабировать количество SM без пропорционального увеличения вспомогательного оборудования. Такая архитектура хорошо подходит для тяжёлых, продолжительных вычислительных нагрузок, хотя короткие операции с малым временем выполнения могут страдать от ограничений в распределении заданий на GPC. В сравнении AMD использует архитектуру с иным соотношением — 1:8 между шейдерным движком (SE) и группами вычислительных процессоров (WGP). Это улучшает загрузку в мелких и кратковременных диспетчеризациях, но Nvidia компенсирует этот недостаток высокой частотой и способностью одновременно обрабатывать разные типы задач благодаря усовершенствованиям в системе управления очередями, исключающим необходимость ожидания завершения предыдущих операций. Важное обновление получил блок выборки и декодирования инструкций SM.
Архитектура опирается на фиксированную длину 128-битных инструкций, что требует высокой пропускной способности программного потока. Благодаря двухуровневой системе кэширования инструкций с приватными L0 и общим L1 для каждого SM, Blackwell обеспечивает эффективную подачу команд и улучшает работу с большими кодовыми базами. Исполнители инструкций были реорганизованы, объединив основные FP32 и INT32 pipelines в один 32-эвекторный исполнительный конвейер. Это обеспечивает высокую производительность, особенно при выполнении длинных последовательностей однотипных операций благодаря уменьшению простоев конвейера. В дополнение Blackwell сохранил способность выполнять 16 INT32 умножений за такт на каждом разделе SM, что было характерно для архитектуры Turing, превосходя многих конкурентов.
Важная особенность — добавление плавающих точек в uniform-датапуть, которую можно считать аналогом скалярного исполнительного блока AMD. Несмотря на некоторые ограничения и особенности реализации, такая архитектура расширяет функциональные возможности GPU и оптимизирует обработку данных, которые одинаковы для всех потоков внутри волны. Функции трассировки лучей также претерпели значительные улучшения. Производительность пересечения лучей с треугольниками удвоилась, а поддержка таких технологий, как Opacity Micromaps, позволяет более эффективно обрабатывать прозрачные объекты и улучшать качество рендеринга без значительного ущерба производительности. Память и подсистемы ввода-вывода — ключевые компоненты в современных GPU, и Blackwell здесь показывает свои сильные стороны.
В каждом SM имеется общий 128 КБ блок памяти, который может быть использован как кэш первого уровня (L1) или как разделяемая память для программ, тем самым обеспечивая гибкость использования в зависимости от задач. При этом Nvidia в отличие от некоторых конкурентов пока не увеличила общий объем L1/Shared Memory, сохраняя эффективное, проверенное соотношение. AMD в этом плане имеет более комплексную структуру, включающую 128 КБ локальной памяти с разделением на разные кэш-структуры с высокой пропускной способностью. Несмотря на это, Blackwell компенсирует потенциальные архитектурные ограничения большей частотой работы и общим более высоким энергопотреблением, что позволяет поддерживать максимальную производительность. Память и кэш-подсистема глобального уровня представлены 128-мегабайтным L2 кэшем, разбитым на 64 банка, что примерно на треть больше по сравнению с предыдущими поколениями.
L2-латентность увеличилась до 130 нс, что обусловлено масштабом и сложностью организации доступа, но в целом остается приемлемой с учетом большой емкости и пропускной способности. Совокупность L2 и высокоскоростной GDDR7 видеопамяти обеспечивает преимущество по пропускной способности по сравнению с конкурентами, создавая сверхмощную платформу для ресурсоемких приложений. Важным аспектом является обработка атомарных операций, необходимых для синхронизации данных при параллельных вычислениях. У Nvidia в каждом SM выделено 16 ALU для атомарных команд INT32, что в сумме дает суммарное преимущество в задачах, связанных с локальной памятью. В глобальной памяти производительность сопоставима с AMD, что свидетельствует о схожем уровне реализации, однако совокупный огромный масштаб Blackwell обеспечивает общую доминирующую позицию.
По итогам тестов в приложениях и бенчмарках Blackwell показывает впечатляющие результаты. Симуляции с интенсивными вычислениями и большим объемом памяти, такие как FluidX3D, демонстрируют лидирующую позицию RTX PRO 6000 Blackwell благодаря большому количеству SM и высокой пропускной способности памяти. Различия в производительности по сравнению с AMD RX 9070 сохраняются постоянными вне зависимости от настроек компиляции и оптимизаций кода. С точки зрения рынка, Blackwell выступает как еще одно подтверждение подхода Nvidia к разработке — максимальное масштабирование вычислительных ресурсов и быстрый выпуск монументальных GPU. Смелое увеличение размеров чипа, энергоемкости (600 Вт в случае RTX PRO 6000), а также применение новейших технологий памяти делают Blackwell самым крупным и самым мощным графическим процессором для потребительского сегмента в 2025 году.