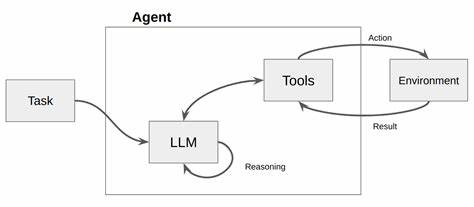
В современном мире развитие искусственного интеллекта движется семимильными шагами, и особое внимание уделяется большим языковым моделям (LLM). Эти модели становятся все более функциональными, расширяя диапазон своих возможностей, включая вызов корпоративных API и управление инструментами. Однако с ростом сложности взаимодействий возникают новые вызовы, в частности, связанные с неполной или неоднозначной информацией, которую получает модель от пользователя. Решение этих проблем — ключ к созданию более надежных и реалистичных систем, способных эффективно взаимодействовать с разнообразными инструментами в бизнес-среде. Одним из наиболее перспективных подходов к повышению качества и безопасности работы таких систем является так называемое дообучение с фокусом на устранение неоднозначностей или дисамбигуацию.
Впервые представленное исследование «Disambiguation-Centric Finetuning Makes Enterprise Tool-Calling LLMs More Realistic and Less Risky» раскрывает инновационный метод, разработанный для повышения точности вызова инструментов в условиях, когда доступны похожие по функционалу сервисы и когда пользовательские запросы оставляют много места для интерпретаций. В чем заключается главная проблема? Современные большие языковые модели часто сталкиваются с ситуацией, когда в корпоративном окружении имеется несколько API или инструментов, выполняющих близкие или даже пересекающиеся задачи. В таких условиях, особенно если в пользовательском запросе не указано достаточно подробностей или аргументов, модель может ошибочно выбрать не тот инструмент, что ведет к снижению эффективности работы и возникновению рисков для бизнеса. Разработчики из команды под руководством Ашутхоша Хатхидара предложили DiaFORGE — комплексную трехэтапную систему, направленную на решение этих сложностей. Первый этап включает синтезирование многоступенчатых диалогов, в которых виртуальный ассистент вынужден сравнивать и выбирать между очень похожими инструментами, опираясь на так называемые “персонажные” сценарии и контекстные подсказки.
Такой подход помогает моделям получать опыт «интерактивного уточнения» запроса, что напоминает живое общение человека с помощью вопросов уточняющего характера. Второй этап предусматривает контролируемое дообучение открытых моделей с числом параметров от 3 до 70 миллиардов. Именно в процессе дообучения модели получают объяснения своих рассуждений — «следы размышлений», что позволяет глубже понимать логику выбора. Это не только совершенствует внутреннее принятие решений, но и повышает прозрачность и доверие к системам AI. Заключительный, третий этап ориентирован на оценку готовности решений к реальной эксплуатации.
Система впускает дообученную модель в динамическую среду, где она в автономном режиме повторно выполняет вызовы инструментов и проверяет успешность выполнения конечной цели. Такой живой тест отличает подход от многих статических метрик, обеспечивая более надежную проверку результатов и реальное повышение качества. Результаты исследования были впечатляющими. Модель, обученная с использованием DiaFORGE, повысила эффективность вызова ремесленных инструментов на 27 процентных пунктов по сравнению с GPT-4o и на 49 пунктов по сравнению с Claude-3.5-Sonnet, причем все измерения велись при оптимизированных подготовительных инструкциях.
Это действительно значительный прорыв в области корпоративных моделей AI, ориентированных на интеграцию множественных сервисов. Для развития и популяризации разработанного решения команда учёных сделала доступной широкому сообществу открытую коллекцию из 5000 продакшен-уровневых спецификаций API, дополненную тщательно проверенными диалогами, сфокусированными именно на устранении неоднозначностей. Благодаря этому специалисты по машинному обучению и разработчики ассистентов могут использовать как обучающий материал, так и основу для тестирования собственных систем. Перспективы внедрения данной технологии особенно важны для предприятий, где точность и безопасность взаимодействия с множеством корпоративных инструментов напрямую влияют на бизнес-процессы. В частности, автоматизированные помощники смогут избежать неправильных команд, связанных с выбором не того API, или запросов с неполной информацией, минимизируя риски сбоев и ошибок.
Использование DiaFORGE и аналогичных подходов открывает новые горизонты для виртуальных ассистентов и цифровых сотрудников, которые не только понимают контекст и учитывают нюансы, но и способны вести диалог на уровне, близком к человеческому взаимодействию. Такой интеллект становится особенной ценностью для компаний, стремящихся повысить клиентский опыт и оптимизировать внутренние операции. В итоге, улучшение моделей с помощью дисамбигуационно-ориентированного дообучения значительно увеличивает реализм вызова инструментов и снижает потенциальные риски, что выводит большие языковые модели на новый уровень интеграции в реальный корпоративный мир. Разработанный подход становится заметным шагом к созданию действительно надежных, адаптивных и эффективных систем искусственного интеллекта, способных качественно сопровождать бизнес и пользователей в постоянно меняющейся цифровой среде.