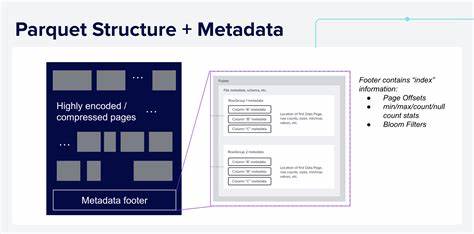
Формат Apache Parquet давно стал одним из самых популярных решений для хранения и анализа больших объемов информации благодаря своей колоночной структуре и оптимизации для аналитических задач. Однако существует распространённое заблуждение, что возможности Parquet ограничены базовой статистикой мин/макс, подсчетом пустых значений и использованием фильтров Блума для ускорения поиска. На самом деле, архитектура Parquet позволяет внедрять более продвинутые пользовательские индексы внутри файлов без изменения спецификации и потери совместимости с существующими читателями формата. Одна из ключевых особенностей Parquet — наличие подробного метаданных файла, расположенных в футере, который включает в себя информацию о структуре файла, столбцах, группах строк и прочих служебных данных. В этих метаданных можно хранить произвольные ключ-значение пары, что открывает возможность для расширений и внедрения дополнительных структур индексации.
Более того, Parquet допускает добавление данных в тело файла, которое читатели, не понимающие специфики вложенных индексов, просто игнорируют. Представим практический пример: в вашем наборе данных есть колонка с названием "Nation", в которой десятки уникальных значений разбросаны по тысячам файлам Parquet. Запрос, который вычисляет средний объем продаж по стране "Сингапур" по годам, может оказаться неэффективным, если полагаться лишь на стандартные min/max статистики, так как диапазон значений колонки слишком широк. В такой ситуации можно эффективно использовать индекс, который хранит полный список уникальных значений колонки в каждом файле, расположенный ближе к концу файла. Во время выполнения запроса поисковый движок быстро проверит наличие нужного значения в индексном списке и пропустит файлы без него, что существенно ускорит обработку.
Для создания пользовательского индекса в Parquet файле разработчики могут сериализовать произвольную структуру данных, например, список уникальных значений, Bloom-фильтр или более сложные приближённые структуры, и добавить эти данные в тело файла за данными столбцов, но до метаданных футера. Затем в футер записывает ссылку с ключом и смещением расположения данного индекса. Поскольку Parquet читатели, не понимающие вложенных данных, просто будут игнорировать неизвестные ключи и байты, совместимость остаётся на высочайшем уровне. Одним из простых и эффективных примеров пользовательского индекса является индекс по уникальным значениям. Его реализация в Rust может представлять собой обычный HashSet, в котором хранятся все уникальные строки по выбранному столбцу.
При сериализации этот набор преобразуется в текстовую строку UTF-8, где значения разделены символами новой строки и предваряются специальными магическими байтами, идентифицирующими формат индекса. Такой подход позволяет легко определить начало и длину блока с индексом при чтении файла. Чтение пользовательского индекса сводится к открытию Parquet файла, парсингу футера для получения смещения индекса, переходу к соответствующему месту в файле и десериализации данных с проверкой корректности магической последовательности. Благодаря этому можно реализовать динамическое получение нужной дополнительной информации по файлу без затрат на сканирование всего содержимого. Интеграция пользовательских индексов с аналитическими движками часто достигается расширением интерфейсов поставщиков данных (TableProvider).
В частности, в рамках Apache DataFusion можно создать кастомный поставщик, который считывает индекс из каждого файла, фильтрует список файлов до выполнения запросов с соответствующими фильтрами и тем самым пропускает ненужную работу. Это приводит к значительному сокращению времени отклика и экономии ресурсов сервера. Преимущества данного решения очевидны: не требуется создание дополнительных внешних индексных файлов и управление их синхронизацией с основными данными, при этом сохраняется полная совместимость с другими популярными системами, такими как DuckDB или Apache Spark. Такие системы будут работать с файлами как обычно, просто игнорируя дополнительные индексы. Важно отметить, что пользовательские индексы отлично подходят для фильтрации по равенствам и спискам значений, но не всегда эффективны для диапазонных запросов или запросов с нечеткими критериями.
Для последних типов задач могут использоваться встроенные в Parquet min/max статистики, Bloom-фильтры или более сложные агрегаты и сэмплы, которые также можно внедрять по аналогичному принципу. Текущие возможности Parquet позволяют хранить неограниченное количество пользовательских индексных структур на разной гранулярности — от всего файла до отдельных групп строк или даже страниц данных. Такая гибкость даёт разработчикам и аналитикам мощный инструмент для оптимизации обработки данных под специфические типы запросов и достижения максимальной производительности. Пример использования больших аналитических платформах демонстрирует, что внедрение пользовательских индексов помогает системам эффективно проводить селективное чтение, уменьшать задержки и снижать нагрузку на ресурсы без необходимости совершенствовать сам формат хранения или переходить на менее проверенные решения. Это особенно актуально в условиях растущих объёмов данных и усложняющихся требований к оперативности аналитики.
Помимо прямого ускорения выполнения запросов, пользовательские индексы облегчают развертывание масштабируемых систем аналитики за счёт снижения затрат на администрирование внешних файловых индексов, упрощают управление версиями и повышают надёжность системы в целом. Разработчики и компании, использующие Apache Parquet в своих архитектурах, могут с помощью встроенных индексов внедрять собственные механизмы оптимизации, адаптированные под конкретные бизнес-задачи, значительно улучшая производительность без ущерба совместимости и удобству интеграции. В заключение стоит подчеркнуть, что возможности расширения индексации внутри Parquet файлов — это эволюционный шаг в области хранения данных, позволяющий создавать интеллектуальные, гибкие и более эффективные системы аналитики. Акцент на использовании стандартов и обратной совместимости помогает ускорить распространение и интеграцию таких решений в существующие экосистемы обработки данных. Этот инновационный подход вдохновляет разработчиков на продолжение исследований в области оптимизации работы с большими данными и даёт надежду на создание ещё более мощных инструментов, способных удовлетворить потребности самых требовательных пользователей.
Apache DataFusion и сообщество Arrow активно поддерживают развитие таких механизмов, предоставляя готовые инструменты и примеры использования, что делает начало работы с пользовательскими индексами простым и доступным даже для специалистов без глубокого опыта в системном программировании.

![Potential backdoor in Intel's AES hardware implementation [video]](/images/A0FD4DA0-45B2-4ADD-9DCE-E249B1BDD60A)