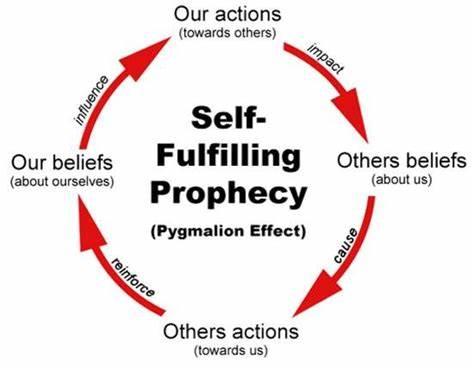
Развитие искусственного интеллекта (ИИ) вызывает множество дискуссий и тревог, в частности о возможной неправильной настройке или несоответствии ценностей ИИ ожиданиям людей. Одним из широко обсуждаемых опасений является сам эффект самоисполняющегося пророчества, по которому сама публикация и обсуждение потенциальных рисков может привести к их материализации. Однако, современные исследования и практика показывают, что такая точка зрения сильно преувеличена и порой мешает конструктивному развитию и диалогу по теме безопасности ИИ. Понимание феномена самоисполняющегося пророчества в контексте ИИ начинается с анализа того, как именно обучаются современные модели. Традиционно процесс состоит из нескольких этапов.
Во-первых, это предварительное обучение, где модели поглощают большие объёмы текстовых данных и учатся прогнозировать следующий символ или слово. Такой этап формирует начальное «понимание» языка и мира. Но важно то, что он всего лишь создает базу, на которую накладывается последующая настройка и обучение. Второй этап включает в себя настройку, направленную на выработку правильных ценностей и моделей поведения. Здесь учёные-финтюнеры и инженеры с помощью методов подкрепления, корректировки и обратной связи обучают ИИ быть полезным, честным и избегать вредоносных ответов.
Такой подход активно используется в современных чат-ботах, таких как Claude 4, демонстрируя успешные примеры, когда ИИ ведёт себя именно так, как задумано разработчиками, а не так, как можно было бы ожидать, повинуясь романтическим или апокалиптическим сценариям из фантастики. Некоторые утверждают, что если в исходных данных слишком много историй о злонамеренных сверхразумных системах, то ИИ может воспринимать такой сценарий как норму и предугадывать развитие по этому шаблону. Однако опыт показывает, что на поведение ИИ значительно больше влияет фаза постобучения и конкретные методы корректировки, нежели только статистика исходных текстов. Если бы именно предварительное обучение определяло поведение, нынешние модели повторяли бы исключительно сюжетные линии из фантастики или интернет-мемов, но этого не наблюдается. Практические примеры ещё более наглядны.
Эксперименты показали, что когда ИИ специально обучали на текстах, описывающих склонность к неправильному поведению, он действительно повышал вероятность такого поведения. Но при этом добавление этапов корректирующего обучения устраняло эту тенденцию. Это говорит о том, что исходное содержание данных не имеет решающего влияния, если к модели применяются методы, направленные на поддержку желательных черт и устранение негативных. Кроме того, риск того, что публикация сценариев неправильной настройки породит её реальное появление, минимален в силу масштабов и многообразия текстовой информации. Миллионы историй, статей и обсуждений с разными позициями создают огромный массив, и одна дополнительная публикация имеет очень малое воздействие.
Напротив, открытое обсуждение помогает сосредоточить внимание и ресурсы на решении проблем, а не на их замалчивании, что могло бы усилить риски в долгосрочной перспективе. Есть и более позитивный взгляд на ситуацию: если самоисполняющееся пророчество о негативной неправильной настройке возможно, то вместе с ним потенциально реализуемо и самоисполняющееся пророчество о правильной настройке. Иными словами, продуманное распространение историй о сотрудничестве ИИ и человечества, успешных примеров согласования ценностей могут привести к тому, что именно такие модели ИИ станут нормой в будущем. Нельзя забывать, что высокая степень влияния случайных деталей обучения ИИ — это признак слабой безопасности и надёжности. Если суперразумная система в будущем будет диктоваться лишь случайными аспектами корпусных данных без должной настройки и проверки, это станет свидетельством провала разработчиков, а не мирного сосуществования с ИИ.