В современном мире, где голосовая коммуникация занимает значительное место в нашей повседневной жизни, качество звука имеет первостепенное значение. Особенно это касается видео-конференций, VoIP-звонков, подкастов и других форм цифрового общения. Шум является одной из главных преград, мешающих четкому восприятию речи, снижая комфорт и эффективность коммуникации. Именно здесь на сцену выходит RNNoise — инновационный проект, применяющий глубокое обучение для подавления шума в режиме реального времени. RNNoise представляет собой уникальный гибридный подход к шумоподавлению, который объединяет классические методы обработки аудио сигналов с возможностями искусственного интеллекта, а точнее — рекуррентных нейронных сетей (РНС), в частности, Gated Recurrent Units (GRU).
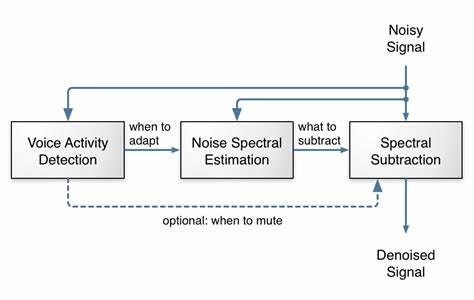
Это сочетание позволяет добиться высокого качества шумоподавления, при этом обеспечивая минимальные задержки и низкие требования к ресурсам оборудования. Благодаря этому алгоритм легко запускается даже на бюджетных процессорах и устройствах с ограниченными вычислительными мощностями, таких как Raspberry Pi. Традиционные методы шумоподавления существуют уже несколько десятилетий, начиная с 70-х годов прошлого века. Их суть заключается в распознавании голосовой активности (Voice Activity Detection, VAD) и последующей оценке спектральных характеристик шума для его субтракции из общего сигнала. Несмотря на кажущуюся простоту, на практике создание универсального, надежного и эффективного алгоритма шумоподавления требует тщательной настройки множества параметров и учета разнообразных сценариев использования.
Такие классические алгоритмы часто сталкиваются с проблемой музыкального шума — неприятных артефактов, которые появляются при неравномерном подавлении частотных компонентов. Появление глубокого обучения и особенно рекуррентных нейронных сетей позволило существенно продвинуться в области обработки аудио. Благодаря способности РНС учитывать временные зависимости и хранить информацию о предыдущих состояниях, появляется возможность более точно выделять характеристики шума и речи во временной последовательности. Одной из ключевых структур здесь выступают Gated Recurrent Units, которые, в отличие от традиционных рекуррентных ячеек, используют механизмы управления состоянием с помощью специальных ворот — сброса и обновления. Эти компоненты помогают избежать проблем с затуханием градиентов при обучении и позволяют модель эффективнее запоминать важную информацию на длительных временных промежутках.
RNNoise эффективно использует потенциал GRU, поскольку они обеспечивают баланс между производительностью и расходом ресурсов, превосходя по эффективности классические LSTM. Такой выбор архитектуры способствует интеграции алгоритма в приложения с жесткими ограничениями по вычислительным мощностям без необходимости использования мощных графических процессоров. Для снижения сложности модели и уменьшения объема вычислений в RNNoise применяется обработка сигнала на уровне полос частот, соответствующих шкале Барк, которая адаптирована под восприятие человеческим ухом. Вместо анализа сотен или тысяч отдельных частотных компонентов алгоритм оперирует всего 22 полосами, что значительно упрощает как входные данные, так и выходные параметры сети. На выходе нейросеть вычисляет коэффициенты усиления для каждой полосы, позволяя динамически управлять уровнем сигнала в каждой из них и эффективно подавлять шум без образования неприятных артефактов.
Особенностью RNNoise является использование не просто спектральных данных, а логарифмического преобразования энергии полос с последующим применением дискретного косинусного преобразования (DCT). Это создает набор признаков, схожий по структуре с широко используемыми в распознавании речи мел-частотными кепстральными коэффициентами (MFCC), что способствует лучшему обучению сети и улучшает качество распознавания и подавления шума. Входные данные для нейросети дополнительно обогащаются новыми признаками: производными первых коэффициентов кепструма, параметрами периодичности и силы голоса, а также специальным показателем нестабильности сигнала, помогающим точнее дифференцировать речь и шум. Этот набор из 42 признаков позволяет модели лучше понимать сложные изменения во входном аудио и адаптироваться к динамическим сценариям. Динамическая структура нейросети RNNoise состоит из нескольких полносвязных слоев и трех рекуррентных слоев GRU, которые последовательно обрабатывают входные признаки и вычисляют значения усиления для каждой полосы.
Кроме того, сеть одновременно оценивает вероятность наличия речи, что может быть полезно в дополнительных задачах, таких как голосовая активность или управление шумоподавлением. Обучение RNNoise — сложный и ответственный этап. Поскольку невозможно одновременно записать чистую речь и ту же речь с шумом, данные для обучения создаются искусственно, путем смешивания записей чистой речи с разнообразными шумовыми фонами. Отбор и разнообразие шумов критичны, так как они обеспечивают надежную работу алгоритма в самых разных условиях. Дополнительную сложность создает возможность работы с сигналами, отфильтрованными по верхней частоте, поэтому тренировка проводится на различных диапазонах частот, чтобы обеспечить универсальность модели.
Одним из уникальных элементов алгоритма является так называемая вокальная фильтрация или pitch filtering. Из-за невысокой частотной разрешающей способности полос невозможно детально выделять шум между гармониками голоса, что могло бы привести к ухудшению качества речи. Для решения этой задачи применяется периодическая обработка сигнала, где среднее значение вычисляется не для соседних сэмплов, а для сэмплов, разделенных на период основного тона. Такая техника действует как гребенчатый фильтр, пропускающий гармоники голоса и подавляющий шумовые компоненты между ними. Сила фильтра зависит от степени корреляции по периодичности и коэффициентов усиления, вычисляемых нейросетью, что позволяет сохранить естественность звучания и избежать искажений.
После этапа обучения модель экспортируется и переводится из среды Python и библиотеки Keras на язык C для применения в реальных приложениях. Такой подход обеспечивает более высокую скорость работы и меньшую нагрузку на систему. Весовые коэффициенты сжимаются до 8-битного формата, что позволяет сократить занимаемую память до 85 Кбайт, в несколько раз меньше по сравнению с традиционными 32-битными значениями. Практические тесты показывают, что RNNoise работает на нескольких десятках раз быстрее реального времени на обычных процессорах x86 и даже многократно превосходит эту скорость на популярном одноплатном компьютере Raspberry Pi 3. Таким образом, данное решение отлично подходит для встраивания в программные и аппаратные средства видеозвонков, голосовых ассистентов, стриминга и других систем, где критичны задержки и производительность.
Ключевой показатель работы RNNoise — улучшение качества звука и снижение раздражающего воздействия фонового шума, а не обязательно повышение разборчивости речи, так как человеческий мозг и так великолепно распознает речь даже в неблагоприятных условиях. Тем не менее для сложных случаев с несколькими говорящими или при сжатии аудио кодеками с низким битрейтом шумоподавление приносит заметную пользу. Проект RNNoise доступен с открытым исходным кодом под лицензией BSD, что способствует его широкому распространению и дальнейшему развитию. Активное сообщество и исследователи могут улучшать модель, адаптировать ее под новые задачи, например, автоматическую расшифровку речи или создание умных шумовых гейт-систем для музыкальных инструментов. Одним из вариантов развития RNNoise является сбор дополнительных шумовых данных от пользователей, что позволяет собрать разнообразные примеры и улучшить адаптивность модели к реальным сценариям эксплуатации.
Такая инициатива позволяет сделать шумоподавление по-настоящему персонализированным и эффективным в различных условиях окружающей среды. В целом, RNNoise демонстрирует, как грамотное сочетание классических алгоритмов обработки звука с современными методами глубокого обучения может привести к качественным прорывам в реальном времени. Это существенно расширяет возможности коммуникаций во всех сферах жизни, делая их более комфортными и надежными при любых уровнях фонового шума.