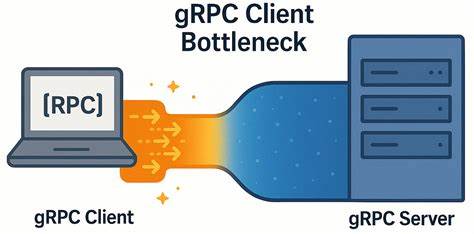
В современном мире распределенных систем и микросервисов коммуникация между сервисами должна быть максимально быстрой и эффективной. gRPC, построенный на базе HTTP/2, давно считается одним из самых производительных и надежных протоколов для межсервисного взаимодействия. Однако даже в высокотехнологичных решениях могут скрываться неожиданные ограничения, которые существенно влияют на производительность системы. Одним из таких примеров является обнаруженное в ходе практических испытаний узкое место на стороне gRPC клиента, наблюдаемое в условиях сетей с низкой задержкой. Протокол gRPC широко используется для экспонирования API распределенных баз данных и других критичных сервисов.
Несмотря на репутацию высокопроизводительной технологии, при работе с минимальными задержками и большими нагрузками обнаружилось, что gRPC клиент может стать главным источником деградации производительности. Интересно, что это не связано с сервером или сетью, а именно с нюансами внутренней реализации и особенностями управления каналами связи на клиентской стороне. В процессе изучения проблемы выяснилось, что сниженное число узлов в кластере приводит к затруднениям при генерации достаточной нагрузки. Вместо ожидаемого роста эффективности наблюдается увеличение клиентской латентности — при этом ресурсы самого кластера остаются недозагруженными и, следовательно, неэффективно используются. Данную аномалию удалось локализовать именно до архитектуры gRPC клиентской реализации.
Для демонстрации выявленной ситуации была разработана микробенчмарка на C++, работающая по принципу пинга: клиент отправляет запрос, сервер отвечает без нагрузки на полезную нагрузку, что позволяет максимально сконцентрироваться на измерении производительности самого протокола. Тесты проводились на мощном оборудовании с минимальным сетевым временем отклика, что исключало влияние внешних факторов. Одной из отправных точек была особенность gRPC каналов. Как известно, каждый канал базируется на одном или нескольких HTTP/2 соединениях, а каждое из них ограничено по количеству одновременных потоков (через эти потоки реализуются отдельные RPC запросы). Если предел достигнут, дополнительные запросы не отправляются мгновенно, а ставятся в очередь, что может замедлять обработку.
Классические рекомендации гласили использовать либо отдельные каналы по зонам высокого трафика, либо пул каналов с разными аргументами, чтобы создать мультиплексирование между несколькими TCP соединениями. На практике команда обнаружила, что при использовании одного TCP соединения с множеством стримов и каналов с идентичными параметрами запросы мультиплексируются в одном соединении, что приводит к неожиданным задержкам. Клиент, фактически, отправляет сообщения порциями, и между отправкой одних и других возникает пауза до 150–200 микросекунд — существенный показатель при работе на сетях с низкой задержкой в несколько десятков микросекунд. Анализ сетевого трафика подтвердил, что сама сеть и сервер не были узким местом: не наблюдалось проблем с оконной контролью TCP, отложенными подтверждениями или пакетными потерями. Применение настроек TCP_NODELAY и прочих оптимизаций также не решало ситуацию.
Поэтому было выделено, что причина кроется в клиентской реализации gRPC, в частности, в способе управления потоками и каналами. Эксперименты с регулировкой числа параллельных запросов показали, что производительность растёт не пропорционально увеличению количества работников (воркеров). При десятикратном увеличении клиентов прирост пропускной способности составил лишь около 3.7 раза, а при двадцатикратном — всего 4 раза. При этом задержка росла линейно и существенно превышала сетевые показатели, что свидетельствует о том, что производительность была ограничена ожиданиями на уровне клиента.
Переломным моментом стало использование отдельных каналов с уникальными аргументами, что создаёт отдельные TCP соединения и исключает мультиплексирование всех потоков в одном соединении. Включение специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL дало существенный прирост как в пропускной способности, так и в снижении задержек. Особенно заметно улучшение проявилось, когда у каждого рабочего процесса был свой канал с настройками, которые не позволяли gRPC объединять их в одно TCP соединение. Дополнительные тесты в различных сетевых условиях — в том числе с имитацией высокой сетевой задержки порядка 5 миллисекунд — показали, что подобный узкий клиентский узел становится проблемой именно в высокопроизводительных высокоемких сценариях с минимальной сетевой задержкой. В ситуациях с высокими задержками разница между одним и множеством каналов практически нивелируется, поскольку сетевая задержка начинает доминировать над внутренними задержками клиента.
Таким образом, в комплексной оптимизации производительности распределённых систем на базе gRPC нельзя игнорировать архитектуру клиента и особенности взаимодействия HTTP/2 потоков внутри TCP соединений. Большое количество RPC запросов, направленных через один TCP коннекшн, при низких сетевых задержках может привести к накоплению клиентских задержек за счёт внутренних механизмов синхронизации, очередей и мультиплексирования потоков. Современные практики рекомендуют создавать отдельные каналы с разными параметрами, чтобы задействовать несколько TCP соединений. Такой подход не только уменьшает задержки, но и справляется с ограничением максимального числа одновременных потоков на соединение. Кроме того, настройка опций, таких как локальные пулы подканалов, может значительно улучшить производительность без необходимости радикально менять архитектуру клиентского кода.
Эти выводы имеют важное значение для проектов, где требования к минимальной задержке и максимальной пропускной способности особенно высоки — к примеру, в распределённых базах данных, финансовых торгах, телекоммуникациях и системах реального времени. Пренебрежение клиентскими ограничениями gRPC может привести к неэффективному использованию ресурсов и снижению общей производительности, несмотря на идеально оптимальный сервер и быстрое соединение. При разработке и масштабировании gRPC-клиентов необходим системный подход: дифференциация каналов, настройка их параметров, мониторинг создания и использования TCP соединений, а также глубокое тестирование в условиях, максимально приближенных к реальным. Обнаружение и устранение узких мест на стороне клиента при минимальных сетевых задержках является примером того, как внимание к деталям реализации протокола может привести к внушительному приросту производительности. Без таких комплексных исследований и понимания внутренних рынков работы gRPC сервисов сложно добиться высокого качества и стабильности распределённых приложений.
В итоге можно утверждать, что хорошо знакомые «лучшие практики» gRPC, такие как разделение каналов и использование пулов, являются скорее частями одного целого решения, а не альтернативными вариантами. Применение этих методик совместно помогает добиться высокой производительности в самых требовательных сценариях. При этом не исключено, что существуют и другие, менее очевидные оптимизации и подходы, которые могут ещё больше повысить эффективность gRPC клиентов. Обмен опытом и постоянный обмен результатами исследований среди специалистов способствует развитию более совершенных инструментов и практик, что в конечном счёте ведёт к улучшению всего программного стека распределённых сервисов. Следовательно, для разработчиков и архитекторов систем на базе gRPC важно не только фокусироваться на серверных ресурсах и сетевой инфраструктуре, но и уделять первостепенное внимание грамотной конфигурации и архитектуре клиентской части.
Только такой всесторонний подход обеспечит максимальную производительность, высокую отказоустойчивость и минимальную задержку работы сервисов в реальных условиях.