В современных распределённых системах и приложениях с высокой нагрузкой скорость и качество межсервисного взаимодействия имеют критическое значение. Одним из самых популярных протоколов для этого стала gRPC, предоставляющая гибкий и эффективный способ удалённого вызова процедур поверх HTTP/2. Несмотря на широкую распространённость и репутацию производительного решения, недавние исследования показали, что даже в условиях низкой сетевой задержки и высокоскоростных каналов передачи данных gRPC-клиенты могут сталкиваться с неожиданными внутренними ограничениями, замедляющими работу всей системы. Очевидно, что улучшения вне узкого места не дают желаемого результата — ключ в выявлении самого слабого звена и устранении его воздействием на общую производительность. В рамках разработки YDB, распределённой SQL-базы данных с акцентом на масштабируемость и строгие транзакционные гарантии, подробно исследовался gRPC-стек в реальных сценариях нагрузки.
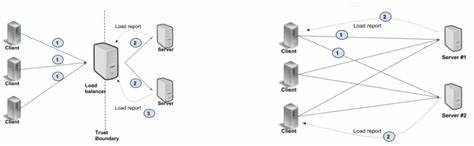
Оказалось, что именно клиентская часть gRPC создаёт неожиданный бутылочное горлышко, из-за которого при уменьшении числа узлов в кластере наблюдалось снижение общей пропускной способности и рост латентности на стороне клиента. Это противоречило первоначальным ожиданиям, поскольку меньший кластер с меньшим объёмом работы должен был работать эффективнее. При разборе проблемы было использовано лёгкое микробенчмарочное приложение на C++, имитирующее работу клиента и сервера, что позволило выявить характерные задержки и выявить механизм их возникновения. Анализ производительности продемонстрировал, что большинство вызовов проходило через единственное TCP-соединение, использующее возможности HTTP/2 multiplexing. Однако ограничение на максимум параллельных потоков (streams) в одном соединении и связанные с этим очереди в gRPC приводили к увеличению времени ожидания, особенно по мере роста числа одновременных запросов.
Эффект проявлялся особенно остро в условиях низкой сетевой задержки и высокой пропускной способности, где минимальные накладные расходы в протоколе становились доминирующим фактором. В ходе экспериментов было отмечено, что стандартные рекомендованные решения — использование нескольких каналов с отдельными TCP-соединениями — работают лучше, но полноценное устранение узкого места достигается только при назначении каждому рабочему своему собственному каналу с уникальными параметрами, либо через активацию специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL. Эта мера позволила значительно увеличить пропускную способность, повысить масштабируемость и снизить среднюю задержку отклика. При применении подобных оптимизаций удалось добиться почти шестикратного прироста пропускной способности на операции без потоковой передачи и около четырёх с половиной раз на потоковых RPC. Также стоит отметить, что латентность при увеличении числа одновременных запросов возрастала намного медленнее по сравнению с первоначальной конфигурацией.
Дальнейшее тестирование в сети с более высокой задержкой (примерно 5 мс) показало, что влияние внутренней клиентской оптимизации значительно снижается, и различия между конфигурациями становятся менее заметными. Это указывает на то, что узкое место критически проявляется именно в высокоскоростных сетях с минимальной задержкой, где каждый микросекундный выигрыш имеет значение для производительности. Полученные результаты подчеркивают важность глубокого понимания особенностей реализации клиентской части gRPC при проектировании высокопроизводительных систем. Простое создание множества клиентов или попытка увеличить параллелизм без корректной настройки каналов и управления соединениями может привести к снижению эффективности и росту задержек. Одним из принципов оптимизации становится распределение нагрузки не только серверного кластера, но и клиента, что существенно меняет традиционный взгляд на построение коммуникационных модулей.
Рекомендуется уделять особое внимание конфигурации каналов, вынося каждому рабочему отдельный gRPC-канал с уникальными параметрами, а также использовать доступные механизмы локального пуллинга субканалов. Эти приёмы помогают избежать бесконтрольного мультиплексирования в пределах одного соединения, которое приводит к конкуренции между потоками и внутреннему конфликту ресурсов. Для разработчиков и инженеров по производительности важно помнить, что при разработке систем с низкой сетевой задержкой нельзя ограничиваться только настройкой сетевого стека и серверной части. Оптимизация клиентской стороны, особенно в части gRPC, становится критически значимой и требует глубокого анализа логики работы протокола и активности внутри клиента. В свете этого опыта, открытым остаётся вопрос, насколько широко подобное узкое место распространено в других гRPC-реализациях и языковых биндингах.
Предварительные испытания показали, что проблема встречается как в C++, так и в Java-клиентах, что говорит о системном характере вопроса. Индустрия заинтересована в дальнейшем развитии и совершенствовании инструментария gRPC, и любой вклад в виде оптимизаций, патчей или новых рекомендаций будет востребован. Запуск собственного микробенчмарка и анализ результатов на реальном железе и сети с помощью современных средств мониторинга позволяет выявить слабые места и настроить инфраструктуру для достижения максимальной отзывчивости и пропускной способности. В заключение нужно подчеркнуть важность баланса между количеством одновременно запущенных запросов, количеством клиентов (воркеров) и каналов, а также параметров их конфигурации. Правильное распределение и разделение нагрузки как на серверной стороне, так и на клиентской, — ключ к достижению низкой латентности и высокой производительности.
Те, кто разрабатывает распределённые приложения на базе gRPC, особенно в системах с высокими требованиями к быстродействию, должны принимать во внимание выявленные ограничения и использовать предложенные методы оптимизации. Результаты исследований в YDB.tech не только расширяют понимание работы gRPC в быстрых сетях, но и открывают перспективы для создания ещё более отзывчивых, стабильных и масштабируемых распределённых систем будущего.