Сегодня искусственный интеллект занимает важное место в технологическом развитии, а оценка его работы становится ключевым этапом в создании качественных и надежных продуктов. AI Evals, или системы оценки моделей искусственного интеллекта, помогают выявлять проблемы, оптимизировать производительность и обеспечивают стабильность функционирования продуктов с использованием языковых моделей. Разберемся в наиболее популярных вопросах, связанных с этим процессом, чтобы помочь профессионалам и энтузиастам внедрить эффективную систему оценки. Что такое AI Evals и почему они необходимы? AI Evals представляют собой комплекс методов и инструментов для проверки качества работы языковых моделей и других систем ИИ. В отличие от стандартных бенчмарков, эти оценки ориентированы на реальные прикладные задачи и пользовательские сценарии.
Такая оценка позволяет команде разработки быстро выявлять и устранять ошибки, повышая качество конечного продукта и обеспечивая его соответствие нуждам пользователей. Основой любых AI Evals является анализ данных и ошибок. Этот процесс позволяет выделить конкретные недостатки в работе модели, сформировать перечень проблемных сценариев и определять направления улучшений. Регулярное проведение анализа ошибок — ключ к успешному развитию AI-продуктов. Без него команды рискуют тратить ресурсы на неверные задачи или недостаточно точные метрики.
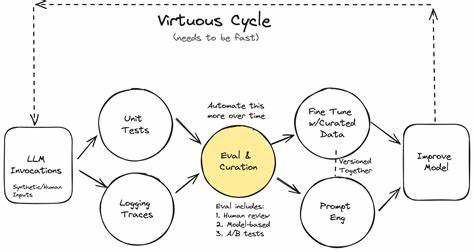
Терминология и базовые понятия играют важную роль в понимании процесса. Например, «трейс» — это полный лог всех взаимодействий с моделью: от запроса пользователя до конечного ответа с учетом всех промежуточных шагов. Анализ таких трейсов позволяет понять, как именно модель принимает решения и где возникают сбои. Обладая четким представлением о деталях каждой сессии, можно строить более точные и эффективные оценки. Как же начать внедрение AI Evals? Первым шагом всегда стоит ручной анализ ошибок.
Потратить полчаса на просмотр нескольких десятков примеров с рассмотрением проблем позволит выявить наиболее частые и критичные сбои. Желательно, чтобы этим занимался один эксперт, глубоко знакомый с продуктом и его пользователями — так называемый «благосклонный диктатор». Дальнейшая автоматизация и написание сложных оценщиков возможны только после того, как команда четко определит, что именно нужно проверять и исправлять. Выделение бюджета на оценку моделей — частый вопрос у команд разработки. Важно понимать, что оценка — неотъемлемая часть процесса создания ПО, похожая на отладку.
Большая часть работы уходит на выявление и изучение ошибок, а не на построение автоматических тестов. При этом не стоит стремиться к 100% прохождению тестов, так как слишком высокий проходной балл может означать недостаточную сложность оценок. Несмотря на быстрый прогресс в области ИИ, методы оценки останутся релевантными в долгосрочной перспективе. Даже при совершенствовании моделей потребуется регулярно проверять, действительно ли они решают нужную задачу, корректировать их поведение и подходы на основе анализа реальных данных, а также учитывать изменения во внешних условиях и требованиях. Для успешной работы с AI Evals стоит убедить команду в важности оценки, показывая реальные результаты анализа ошибок и его влияние на качество продукта.
Использование живых примеров, метрик по частоте и значимости ошибок, а также фиксирование успехов в снижении проблем укрепляет доверие к процессу и стимулирует инвестиции в развитие системы оценки. Одним из центральных элементов процесса является error analysis — всесторонний анализ ошибок. Это помогает не только выявить виды сбоев, но и понять их причины, что значительно повышает эффективность сборки и внедрения корректирующих мер. Процесс включает сбор набора данных, открытое кодирование с заметками эксперта, категоризацию выявленных ошибок и итеративное улучшение taxonomy, или таксономии ошибок. Чтобы выявлять критичные трейсы, помимо пользовательского фидбэка, можно использовать различные стратегии выборки данных — рандомизированную проверку, стресс-тестирование или сложные метрики отбора.
Чем грамотнее и целеустремленнее будет этот процесс, тем выше шансы поймать самые редкие и незаметные проблемы. Периодичность анализа стоит соотносить с масштабом изменений в продукте. При добавлении новых функций, смене моделей или исправлении важных багов необходимы расширенные ревизии. Для стабильных систем иногда бывает достаточно и ежемесячных проверок, однако нужно всегда реагировать на сигналы, указывающие на ухудшение качества или новые сбои. Создание синтетических данных для тестирования вызывает много вопросов.
Важно помнить, что бесструктурный запрос для генерации тестов приведет к результатам низкого качества и повторениям. Идеально разработать набор измерений или параметров, по которым будут генерироваться тестовые запросы с разнообразной комбинацией значений. Этот продуманный подход обеспечивает более глубокое покрытие разнообразных сценариев использования. Однако синтетика не всегда надежна. Для специализированных доменов, редких языков или случаев, где необходима высокая точность и достоверность, лучше опираться на реальные данные.
Синтетические образцы могут не учитывать тонкости и исключения, что критично для медицины, права и других чувствительных сфер. При работе с системами, обрабатывающими широкий спектр пользовательских запросов, не стоит заранее создавать чрезмерно сложную матрицу оценок. Лучше ориентироваться на реальные данные и выявленные через ошибочный анализ закономерности, позволяющие сгруппировать запросы по общим признакам и определить общие проблемы для этих групп. Отбор подходящих трейсов для проверки эффективен при использовании методов отсева аномалий, приоритизации по пользовательским сигналам и продвинутой выборке по мета-данным или кластеризации. Такое сужение фокуса экономит время экспертов и улучшает качество выявленных дефектов.
В проектировании самих оценок советуют отдавать предпочтение бинарным меткам — пройдено или провалено — вместо многоуровневых рейтингов. Простота способствует единообразию решений и снижает субъективность и вариативность при аннотировании. Практика так называемой eval-driven разработки, то есть создания тестов до реализации функционала, в большинстве случаев неэффективна. Наоборот, стоит ориентироваться на реальные ошибки и регистрировать оценочные метрики под узко определенные сбои, а не фантазировать об ошибках, которые еще могут появиться. При выборе, какие автоматические оценщики строить, разумнее сосредоточиться на трудноустранимых или многократно возникающих ошибках.
Простые недочеты зачастую проще устранить корректировкой промптов или логики, не тратя ресурсы на сложные системы оценки. Готовые универсальные метрики редко подходят под конкретные задачи и часто вводят в заблуждение, поэтому целесообразнее разрабатывать собственные, основанные на анализе конкретных проблем и требований. Аналогично, популярные метрики сходства (например, BERTScore или ROUGE) обычно мало помогают в оценках качества ответов ИИ за пределами узких задач вроде поиска или рекомендаций. Выбор модели для оценки не обязательно должен отличаться от основной. При условии хорошей валидации и корректного обучения судейской модели можно использовать тот же или схожий тип модели.
Ключевое — высокая точность и согласованность с оценками человека. Оценка способности модели признавать неопределенность и отказаться от ответа на неподходящий или невыполнимый вопрос требует создания сбалансированного набора проверок с вопросами, имеющими корректные ответы, и такими, на которые модель не должна отвечать. Эта метрика «умения воздержаться» становится особенно важной для ответственных и критичных приложений. Что касается организации человеческих аннотаций, оптимально иметь одного «благосклонного диктатора» — эксперта по предметной области, который принимает финальные решения и обеспечивает качество. Для больших проектов с разными географическими или культурными контекстами может потребоваться несколько аннотаторов с измерением согласованности их полной работы.
Сотрудничество между продукт-менеджерами и инженерами является залогом формирования целостного понимания ошибок, где первые сосредотачиваются на потребностях пользователей, а вторые — на технических аспектах системы. Аутсорсинг аннотаций в большинстве случаев нежелателен, так как снижает качество обратной связи и понимания проблемы. Отмечают риски поверхностной маркировки, потери контекста и конфликтов в интерпретации. Исключения составляют лишь рутинные задачи или привлечение внешних экспертов для узкоспециализированных областей. Большая часть процесса — ручной глубокий анализ.
Автоматизация на основе моделей ИИ полезна для ускорения рутинных операций, кластеризации и предподготовки данных, но не заменяет экспертный взгляд. В случаях с генерацией промптов не стоит с первых дней полностью полагаться на автоматические инструменты оптимизации. Создание промптов вручную помогает лучше сфокусироваться на требованиях и выявляемых ошибках. Автоматизация более оправдана на поздних этапах, когда критерии оценки стабильны и понятны. Для взаимодействия с оценками важны удобные инструменты.
Рекомендуется создавать собственные интерфейсы, которые учитывают специфику продукта и способствуют эффективному обзору данных. Возможность визуализации, фильтрации, навигации, а также автоматического предсказания проблемных зон повышает качество и скорость анализа. Серьезные пробелы в инструментарии требуют дополнений, таких как умная кластеризация ошибок, AI-сопровождение на всех этапах, поддержка кастомных метрик и API для работы с большими объемами данных. Выбор поставщика оценочных решений чаще всего сводится не к особенностям функционала, а к уровню поддержки и качеству взаимодействия. Рекомендуется пробовать несколько платформ, чтобы найти наиболее подходящую по духу и набору возможностей.
Управление версиями промптов эффективно вести в системах контроля версий, таких как Git, что позволяет объединять их с основным кодом продукта и обеспечивает прозрачность изменений. При необходимости более визуальные решения от платформ также имеют право на жизнь, но могут создавать дополнительную сложность. В CI/CD процессы должны использовать узкоспециализированные, небольшие тестовые наборы, чтобы быстро выявлять регрессии и контрольные случаи. Мониторинг в реальном времени полагается на асинхронные и более тяжёлые эвристики, которые позволяют обнаруживать новые проблемы и отклонения в поведении модели. Стоит различать защитные механизмы — гардайлсы — и полноценные оценщики.
Первые работают в реальном времени, обнаруживая и блокируя грубые ошибки или нарушения. Вторые функционируют после генерации ответа, анализируя качество более комплексно, зачастую асинхронно. В некоторых случаях возможно использовать оценщики, как часть механизма автоматического исправления в продакшене, однако это требует аккуратного учета временных и затратных ограничений, а также баланса между числом ложных срабатываний и пропуском ошибок. Затраты времени на выбор модели стоит сопоставлять с анализом реальных ошибок. Часто замена модели не решает основную проблему, если не выявлена чёткая причина в её работе.
Одной из часто обсуждаемых тем является RAG — Retrieval-Augmented Generation. Некоторые источники утверждают, что RAG «мертв» для конкретных сценариев, например, для кодогенерации. Однако это неправильное понимание. Важно понимать, что Retrieval-Augmented Generation — это принцип использования релевантного контекста для насыщения модели, и он по-прежнему актуален. Ключевой аспект — выбрать правильный подход к поиску и интеграции информации.
Оценка RAG-систем должна учитывать отдельно эффективность поиска (retrieval), измеряемую традиционными информационно-поисковыми метриками, и качество генерации, которую оценивают с помощью методов LLM Evals, особенно через систематический анализ ошибок и человеко-ориентированные метрики. При работе с документами выбор оптимального размера чанка зависит от типа задачи. Для фиксированного вывода лучше использовать большие блоки, содержащие всю необходимую информацию, а для генерирующих и суммаризирующих задач — разбивать на меньшие части для сохранения высокой точности и полноты ответа. Отладка многоходовых диалогов требует фокусироваться на первичной ошибке и простоте воспроизведения ситуации. Использование идентификаторов сессий и внимательное логирование всех взаимодействий помогает быстро выявить источник проблемы.
Если в системе присутствует передача управления человеку, такие моменты требуется детально документировать и анализировать, обращая внимание на качество перехода, полноту контекста и необходимость вмешательства. Для сложных рабочих процессов с множеством шагов и взаимодействием компонентов важно вести подробный лог с метриками прогресса и разбиением по этапам, позволяя выявлять слабые места и локализовать сбои. Работа с агентами, выполняющими сложные и многоступенчатые задачи, требует оценки как конечной успешности задачи, так и диагностики поэтапных результатов, что помогает оптимизировать каждый компонент и снизить число ошибок. Таким образом, AI Evals — это не просто набор тестов или метрик, а комплексный, итеративный и глубоко интегрированный подход к обеспечению качества ИИ, который подразумевает постоянное сотрудничество между узкими специалистами, инженерами и менеджерами, а также использование современных инструментов и человеческого опыта для создания действительно полезных и надежных продуктов.







