Реляционные базы данных уже давно стали краеугольным камнем хранения и организации информации в коммерческих, государственных и научных сферах. Огромные объемы информации, распределённые по множеству таблиц, формируют сложные взаимосвязи и структуры, доступ к которым требует продвинутых инструментов анализа и интерпретации. Однако традиционные методы машинного обучения, ориентированные на табличные данные, сталкиваются с ограничениями при попытках учесть всю кладезь связей и взаимозависимостей, проглядывающихся между ними. Google Research разработали подход, основанный на преобразовании реляционных таблиц в графы — модели, где каждый элемент данных становится узлом, а связи между ними превращаются в ребра с определённым типом. Такой подход позволяет взглянуть на данные как на сеть, где взаимодействия и связи между объектами играют ключевую роль, открывая дорогу к использованию графовых нейронных сетей (Graph Neural Networks — GNN).
Эти сети обладают уникальными свойствами для обработки сложных структурированных данных и способны выявлять скрытые закономерности, недоступные при классическом табличном анализе. Основная сложность заключается в разработке универсальной модели, способной эффективно работать с произвольным набором таблиц, их схемами, типами данных и разнообразными задачами. Традиционные GNN зачастую привязаны к конкретной структуре графа и не способны переносить свои знания на другие, пусть даже схожие, данные без переобучения. Google Research презентовали концепцию графовых фундаментальных моделей (Graph Foundation Models — GFM), объединяющую передовые идеи трансформеров и графового машинного обучения для создания гибкой и масштабируемой системы. Подход базируется на трансформации любых реляционных таблиц в единую сложную гетерогенную графовую структуру, где узлы представляют строки таблиц, а ребра — ссылки между ними, основанные на внешних ключах.
Остальные параметры таблиц превращаются в признаки узлов и ребер, что даёт инструменты для обработки как численных, так и категориальных данных. Важным является и возможность учитывать временные характеристики, которые могут содержаться как в атрибутах узлов, так и во взаимосвязях. Для обучения графовой фундаментальной модели применяется высокоемкая нейронная сеть, напоминающая архитектуру трансформера, что позволяет выявлять сложные зависимости между признаками и элементами графа без жёсткой привязки к конкретным типам данных и структурам. В отличие от классических моделей с фиксированными словарями или таблицами эмбеддингов, GFM учится понимать динамические взаимодействия признаков и строить обобщённые представления, способные адаптироваться к любым новым графам. При масштабной обработке графов миллиардов узлов и ребер, подобной той, что доступна в инфраструктуре Google, модель демонстрирует впечатляющие показатели.
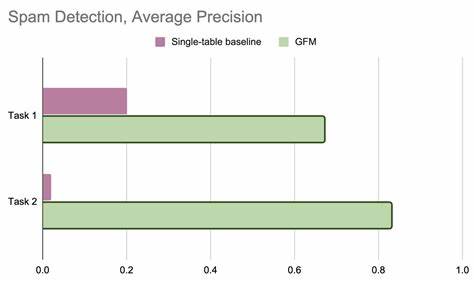
В частности, на задачах внутреннего характера — например, обнаружении спама в рекламе, где данные распределены по десяткам реляционных таблиц, — GFM показывает существенный прирост точности. Отмечается, что традиционные табличные алгоритмы, даже при тонкой настройке, значительно уступают в результате, поскольку не учитывают взаимосвязи между строками разных таблиц. Приросты точности достигают от трёх до сорока раз по метрике средней точности, что подчеркивает критическую важность графовой структуры данных. Эти достижения имеют фундаментальное значение для отрасли машинного обучения и искусственного интеллекта, особенно в области обработки данных крупного масштаба с комплексной структурой. Возможность переносить знания между различными доменами, получать эффективные представления даже при изменениях в структуре и схеме данных, открывает новые горизонты для широкого спектра приложений — включая рекомендательные системы, финансовый анализ, управление цепочками поставок и многое другое.
Инновации Google Research не только расширяют методологический арсенал, но и задают тон будущему развитию технологий. Их подход демонстрирует, насколько важно интегрировать структуру данных в саму модель и использовать преимущества графовых моделей для достижения высокой адаптивности и качества. Перспективы включают дальнейшее масштабирование архитектур, улучшение алгоритмов генерализации и углублённый теоретический анализ, что может привести к появлению еще более мощных и универсальных моделей. В заключение, графовые фундаментальные модели Google Research открывают качественно новый этап в обработке реляционных данных. Трансформация таблиц в графы и обучение универсальных моделей, способных переносить знания на новые данные без дополнительного обучения, кардинально меняют подход к задачам в машинном обучении.
Благодаря таким разработкам возможно значительно повысить эффективность и точность анализа больших корпоративных данных, расширить возможности интеллектуальных систем и построить основы для будущих инноваций в области искусственного интеллекта.