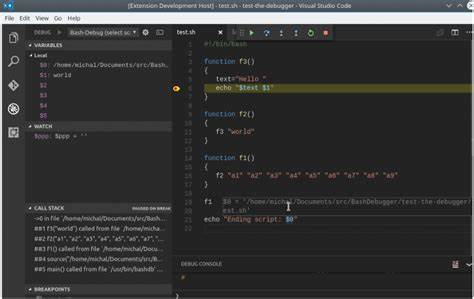
Bash продолжает оставаться одним из самых распространённых инструментов для автоматизации в мире разработки, системного администрирования и многих других IT-областях. Несмотря на его популярность, многие инженеры испытывают сложности с отладкой Bash-скриптов, особенно когда речь идёт о масштабных проектах или сложных сценариях. В этой статье мы подробно рассмотрим, как можно превратить процесс отладки Bash в контролируемый и удобный инструмент, используя встроенные возможности и собственные функции для логирования и траблшутинга. Изначально, Bash, как язык сценариев, не отличается сильной системой обработки ошибок и структур данных. Эти ограничения заставляют разработчиков часто применять defensive programming — защитное программирование, чтобы избежать неожиданных сбоев.
Основной набор встроенных опций, который обычно применяется в Bash-скриптах — set -euxo pipefail. Каждая из этих опций выполняет важную задачу: Опция e отвечает за немедленный выход из скрипта при возникновении ошибки, то есть ненулевого кода возврата. Это позволяет избежать продолжения выполнения скрипта, когда происходит сбой. Опция u помогает обнаруживать использование неопределённых переменных. Если скрипт пытается обратиться к переменной, которая не была задана, это также вызовет ошибку и прервет выполнение.
Опция x выводит в консоль каждую команду перед её выполнением, что значительно упрощает отслеживание логики скрипта во время отладки. Опция pipefail влияет на поведение конвейера команд (pipe). Если любая из команд в пайпе завершается с ошибкой, весь пайп будет считать это нарушением, что улучшает обнаружение ошибок в цепочке команд. Хотя эти опции очень полезны, у них есть свои недостатки. Например, использование опции u в реальных условиях может привести к нежелательным сбоям, если скрипт работает с глобальными переменными, которые задаются вне его.
Флаг x генерирует чрезмерно большой объем отладочной информации и целесообразен лишь при целенаправленной отладке. Также поведение этих опций может незначительно отличаться в зависимости от версии Bash, что порой приводит к неожиданным ошибкам. Важно понимать, что эти флаги не дают информации о конкретном месте и причине ошибки. Распознавание этих аспектов становится критически важным при работе с крупными Bash-проектами. Для этого полезно создавать собственные функции логирования, которые помогут структурировать вывод и сделать его более информативным.
Один из подходов — внедрить систему логирования с разными уровнями сообщений. Например, создать функцию log::info для вывода информационных сообщений и функцию log::level_is_active для проверки, активен ли текущий уровень логов. Уровни логирования можно задать в виде числовых значений, где DEBUG будет иметь наименьший приоритет, а ERROR — наибольший. Такая простая шкала позволяет гибко управлять тем, какие сообщения выводить пользователю. Логика функции log::level_is_active сводится к сравнению переданного уровня с глобальной переменной LOG_LEVEL.
Это гарантирует, что сообщения будут выводиться только при достижении или превышении заданного уровня. Например, установив LOG_LEVEL в INFO, вы исключаете из вывода отладочные (DEBUG) сообщения. Сам процесс формирования лог-сообщения можно делегировать функции log::_write_log. Она принимает уровень логирования и остальные аргументы, формируя консольный вывод в удобочитаемом формате. Важным элементом является получение текущего времени в формате yy.
mm.dd HH:MM:SS, чтобы каждая запись сопровождалась отметкой времени. Дополнительно для увеличения информативности в логах извлекается имя файла и функция, из которой был вызов логирования. Это достигается через две встроенные переменные Bash: BASH_SOURCE и FUNCNAME. Первая содержит список исходных файлов в порядке вложенности вызовов, вторая — имена вызываемых функций.
Извлечение имени именно второго элемента позволяет пропустить внутренние функции логирования и показать место, где он реально понадобился. Для вывода результата логирования используется перенаправление в стандартный поток ошибок — stderr. Это предотвращает путаницу между вашим логом и основной функциональностью скрипта, особенно когда скрипт должен выводить полезные данные в stdout. Результат работы такой системы логирования выглядит примерно так: INFO [23.12.
22 18:34:09] [github.sh - github::bootstrap]: Bootstrap has started WARN [23.12.22 18:34:10] [bazel.sh - bazel::check_buildfarm]: Buildfarm is unavailable INFO [23.
12.22 18:34:11] [bazel.sh - bazel::perform_build]: Starting build execution Дальнейшее расширение возможностей логирования — это функция log::error. Она не только выводит сообщение об ошибке так же, как у info, но и добавляет стек вызовов (stacktrace). Для этого функция перебирает массивы FUNCNAME и BASH_SOURCE, а также использует BASH_LINENO, чтобы показать номер строки, где произошла ошибка.
Отображение стек-трейса — мощный инструмент для понимания того, как и где именно произошла ошибка. Индексы перебирать стоит с определённым смещением, потому что первая запись часто относится к самому началу интерпретатора, а не к вашему коду. Каждая строка выводится в форме: имя_файла:имя_функции:номер_строки, что дает максимально точные указания для последующего исправления. Важно помнить, что Bash не имеет встроенной полноценной отладочной системы как некоторые языки программирования. Поэтому дополнять логи можно с помощью системных ловушек — trap.
Например, можно прописать trap 'log::error "An error has occurred"' ERR, что позволит автоматически запускать логирование ошибок при любых возникших исключениях. Есть и другие трюки для улучшения отладки. Например, по мере развития скриптов рекомендовано избегать использования глобальных переменных без явного контроля, использовать явные проверки входных данных и условия выхода. Удобно также писать функции, которые проверяют обязательные параметры, и, если они отсутствуют, вызывают лог с ошибкой и стеком вызовов. С течением времени такой подход помогает выстроить устойчивую архитектуру Bash-скриптов, при которой ошибки легче выявлять и исправлять.
Это снижает временные затраты на сопровождение и увеличивает надежность в эксплуатационной среде. В заключение стоит подчеркнуть, что грамотная отладка Bash требует сочетания стандартных инструментов Shell и разработки собственных функций для логирования и диагностики. Комбинация встроенных опций set, подписанной системы логирования с уровнями, автоматических стек-трейсов и ловушек ошибок превращает процесс отладки из пытки в искусство. Следуя этим рекомендациям, вы сможете написать более чистые, понятные и сопровождаемые Bash-скрипты, которые не только будут работать, но и легко поддаваться анализу в случае сбоев.



![Could this laser zap malaria? (2010) [video]](/images/8E052DBB-B9F2-49CF-92B3-C4C85598C3A3)

