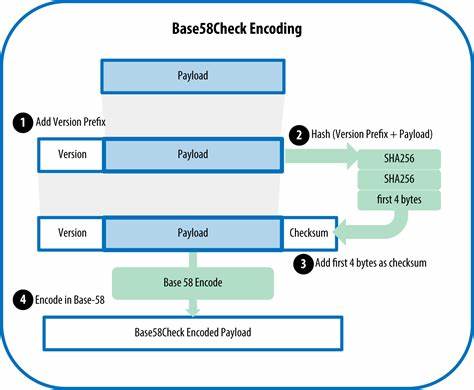
Кодировки Base58 и Base85 занимают важное место в области обработки двоичных данных и широко используются в различных областях IT. Обе кодировки служат для преобразования двоичной информации в человекочитаемую форму, но при этом реализуют это разными способами и с разными целями. Понимание их особенностей и отличий поможет правильно выбрать кодировку в зависимости от задач, а также улучшить эффективность работы с данными. Кодировка Base58 изначально была разработана для решения проблем, связанных с ошибками визуального восприятия текста. В частности, она широко применяется в экосистеме биткоина и криптовалютных технологий, например, для сериализации кошельков, адресов и ключей.
Главная идея Base58 — избежать символов, которые легко спутать друг с другом. Например, буква «l» (маленькая L) и цифра «1», либо буква «O» (большая О) и цифра «0». Чтобы уменьшить вероятность ошибок при ручном наборе или чтении кодированных данных, символы, которые слишком схожи, исключаются из алфавита. Алфавит Base58 состоит из 58 символов, и его набор включает цифры, прописные и строчные буквы, но с определёнными исключениями. Это обеспечивает более удобное восприятие и меньшую вероятность ошибки ввода.
При этом кодирование в Base58 фактически является преобразованием числа в систему счисления с основанием 58, что соответствует обычному математическому смыслу «базы». Такой подход позволяет представить двоичные данные в виде строки, состоящей из символов указанного алфавита. С другой стороны, кодировка Base85 ориентирована на максимальную эффективность представления данных. Её особенность — использование гораздо более обширного набора символов, состоящего из 85 печатных ASCII-символов, что позволяет более компактно упаковывать данные и уменьшать их общий размер в текстовом формате. В Base85 каждая группа из четырёх байтов (32 бит) преобразуется в последовательность из пяти символов, что выгодно отличается по соотношению плотности кодирования от более традиционных систем, например Base64.
Base85 изначально применялась в таких форматах, как PDF, а затем была адаптирована для кодирования патчей в системе контроля версий Git. При кодировании не происходит напрямую преобразования всего числа в систему счисления с основанием 85, как в Base58, а каждая 4-байтовая часть обрабатывается отдельно. Это позволяет более эффективно работать с большими объёмами данных и облегчает параллельную обработку информации. Кроме того, в случае с Base85 существует несколько вариантов алфавита, используемого для кодирования. Это означает, что разные реализации Base85 могут выдавать различные результаты при кодировании одних и тех же данных, что требует внимательного выбора формата для совместимости или же ясного определения применяемого стандарта.
Важный нюанс — несмотря на то, что термин «base» присутствует в названиях обеих кодировок, значение этого слова в контексте Base58 и Base85 различается. Base58 подразумевает преобразование числа в систему с основанием 58, а Base85 использует подход, близкий к так называемому «кодированию бинарно-кодированных десятичных цифр» (BCD), где группы битов разбиваются на числа в определённом диапазоне и кодируются отдельными символами, что более сложное с математической точки зрения. Рассмотрим практические примеры. Если взять четырёхбайтовое число 0xCAFEBABE, которое является «магическим числом» в начале бинарных файлов Java классов, и закодировать его в Base58, результатом будет строка из шести символов. При этом кодирование сводится к вычислению коэффициентов для разрядов в системе счисления с основанием 58 и замене их на соответствующие символы из алфавита.
Получившаяся строка достаточно компактна и удобочитаема. Аналогичная операция с использованием Base85 даст строку из пяти символов, что сразу демонстрирует преимущество базовой эффективности Base85. Этот метод разбивает число на 32-битные слова и кодирует каждое из них отдельно, что и приводит к более компактной записи. Однако при большем объёме данных Base85 может стать более предпочтительным не только из-за меньшей длины закодированного результата, но и из-за большей вычислительной эффективности процесса. Ещё более наглядно разница проявляется при кодировании восьмибайтовых данных.
В Base58 происходит конвертация всего числа целиком, что ведёт к более длинной итоговой строке и большему количеству символов. Для Base85 в этом случае используется отдельное кодирование каждой 4-байтовой части, и результатом становится последовательность из двух блоков, которые проще обрабатывать и хранить. Для понимания особенностей также важно отметить, что алфавит Base85 включает символы, которые потенциально могут путаться визуально, например цифры «0» и буквы «O» или «o». В кодировке Base85 приоритетом была компактность и использование всех доступных и удобочитаемых ASCII-символов, а не максимальная визуальная различимость, как в Base58. В конечном счёте, выбор между Base58 и Base85 зависит от контекста задачи.
Если важна надёжность восприятия человеком, например при обмене ключами, адресами или другими величинами в криптовалютах, Base58 становится очевидным выбором благодаря своему специально подобранному алфавиту и исторически сложившейся популярности. Если же первостепенна эффективность использования места и высокая скорость обработки больших объёмов данных, применяют Base85, особенно в системах, где данные передаются между программами или записываются в форматы с ограничениями по объёму. Важным аспектом также является совместимость с уже существующими стандартами. Base85 часто используется в низкоуровневых протоколах, файловых форматах, системах контроля версий, где кодировка и декодировка должны быть максимально быстрой и не требовать дополнительной проверки символов на человеческие ошибки. Base58 же считается более «человеческой» кодировкой и хорошо подходит для случаев, когда данные читаются и вводятся вручную.
Подытоживая, можно выделить несколько ключевых моментов. Base58 — это числовая система счисления с основанием 58, которая благодаря грамотно подобранному алфавиту минимизирует ошибки при чтении и вводе. Base85 же функционирует по принципу кодирования 32-битных слов в символы из расширенного набора ASCII, обеспечивая более высокую плотность кодирования и удобство для программной обработки. Обе технологии продолжают развиваться и находят своё применение в разных сферах. Понимание различий между ними позволяет точнее подобрать инструменты для работы с данными, а также избежать недоразумений при написании программ, связанных с кодированием и декодированием информации.
Таким образом, Base58 и Base85 не соперничают, а дополняют друг друга, предлагая варианты кодирования с различными акцентами на удобство человека или эффективность машины. Каждый разработчик или специалист, работающий с двоичными данными и их представлением в текстовом формате, должен иметь чёткое представление о преимуществах и недостатках этих систем, чтобы добиваться наилучших результатов при реализации собственных проектов.