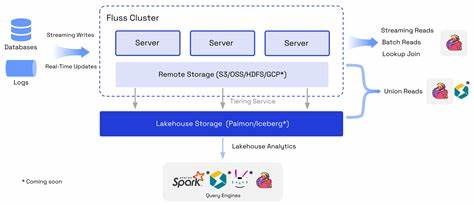
В современную эпоху цифровой трансформации объемы данных растут с молниеносной скоростью. Компании и организации стремятся не только собирать данные, но и обрабатывать их в реальном времени, чтобы принимать оперативные и эффективные решения. Именно в этом контексте на арену выходит Apache Fluss (Incubating) — инновационная система потокового хранения, созданная для аналитики в реальном времени. Этот инструмент обещает изменить традиционные подходы к интеграции потоков данных и хранилищ Lakehouse, обеспечивая непревзойденную производительность и гибкость. Apache Fluss представляет собой мощное решение для объединения потоковой передачи данных и архитектур Lakehouse.
Это означает, что Fluss не просто обеспечивает хранение больших данных, но и позволяет сделать этот процесс максимально динамичным и эффективным. Уникальность проекта заключается в обеспечении субсекундной латентности, что критически важно при работе с оперативной аналитикой, где каждая миллисекунда имеет значение для получения актуальных инсайтов. Одной из ключевых особенностей Apache Fluss является высокая производительность при работе с большими объемами данных. Система оптимизирует процесс чтения и записи данных, используя колоннарный поток, что в разы ускоряет обработку и позволяет эффективно проводить проекции. Такие возможности делают Fluss идеальным выбором для задач, где требуется мгновенный доступ к большим массивам данных с минимальными издержками.
Интеграция с популярными вычислительными движками, такими как Apache Flink, раскрывает новые горизонты для разработчиков и аналитиков. Fluss плавно встроился в экосистему потоковых вычислений, позволяя создавать сложные, масштабируемые аналитические пайплайны с использованием уже знакомых и проверенных инструментов. Ближайшие планы включают поддержку Apache Spark и StarRocks, что расширит возможности взаимодействия и интеграции. Особое внимание стоит уделить возможности частичных обновлений данных в режиме реального времени. Традиционные системы часто сталкиваются с проблемами дорогостоящих операций соединения (join), что замедляет процесс обновления данных на больших объемах.
Fluss решает эту проблему за счет эффективной реализации частичных обновлений, что позволяет компаниям быстрее реагировать на изменения и более гибко управлять информацией. Генерация полных логов изменений — еще одна инновация Apache Fluss. Это значительно упрощает работу аналитиков и разработчиков, которые могут отслеживать динамику данных и анализировать все трансформации в потоке. В результате повышается прозрачность процессов и качество аналитики, что особенно важно при построении комплексных отчетов и моделировании поведения. Среди технологических преимуществ Fluss также стоит выделить возможность выполнения запросов с высоким числом операций на секунду (QPS) для первичных ключей.
Это открывает двери для эффективного обслуживания измерительных таблиц, которые являются неотъемлемой частью любой аналитической инфраструктуры. Высокая производительность на этом фронте существенно снижает задержки и повышает общую отзывчивость системы. Проект Apache Fluss находится в стадии инкубации Apache Software Foundation, что свидетельствует о его инновационности и потенциале для дальнейшего роста. Разработчики уделяют большое внимание сообществу и открытости, приглашая всех заинтересованных к участию в развитии продукта. Это позволяет проекту быстро адаптироваться к потребностям рынка и внедрять новые функции на основе обратной связи.
Технически, для сборки Apache Fluss необходима среда, основанная на Unix-подобных системах, таких как Linux, Mac OS X или их аналоги. Также требуется Git, Maven версии не ниже 3.8.6 и Java 8 либо 11. Все эти требования отвечают современным стандартам разработки и обеспечивают стабильность и совместимость платформы.
Использование Maven Wrapper в процессе сборки гарантирует, что все зависимости и версии инструментов будут корректными, что снижает риски ошибок и упрощает установку как для новичков, так и для опытных разработчиков. Такая автоматизация помогает ускорить процесс внедрения и снизить барьеры для адаптации Apache Fluss в промышленной среде. Философия названия проекта интересна сама по себе: Fluss на немецком языке означает «река», что отлично иллюстрирует суть системы — постоянный поток данных, который постоянно движется, объединяется и направляется в озера данных (Lakehouse), наподобие живой реки. Такое метафорическое название подчеркивает концепцию непрерывного движения и обновления информации. Для бизнеса и крупных организаций Apache Fluss предлагает реальный шанс вывести аналитику на качественно новый уровень.
Возможность оперативно обрабатывать данные с минимальной задержкой, легко интегрироваться с современными инструментами и масштабироваться по мере роста нагрузок делает его привлекательным выбором для построения инфраструктуры данных будущего. Кроме того, Fluss достаточно гибок для интеграции в экосистемы с различными вычислительными задачами, что важно в условиях постоянного развития технологий и увеличения требований к обработке информации. Это делает его универсальным инструментом, способным отвечать не только текущим, но и будущим вызовам в сфере больших данных и аналитики. Отметим также, что проект имеет активное сообщество из более чем 70 участников, что говорит о его живости и поддержке. Регулярные обновления, публичные обсуждения и открытость способствуют быстрому развитию и обеспечивают пользователям доступ к новейшим достижениям в области потокового хранения данных.
Лицензия Apache 2.0 гарантирует, что Apache Fluss можно использовать в коммерческих и некоммерческих проектах без ограничений, что важно для компаний, стремящихся к внедрению открытых и надежных технологий с минимальными юридическими рисками. Это условие также стимулирует рост экосистемы и появление новых решений на базе Fluss. В заключение стоит подчеркнуть, что Apache Fluss — это не просто еще один проект в области больших данных. Это перспективное и высокотехнологичное решение, способное радикально изменить подход к потоковой аналитике, предоставляя компаниям мощный инструмент для управления данными в реальном времени.
Благодаря своей архитектуре, функционалу и открытости к сообществу, Fluss уже заслужил внимание экспертов и специалистов по всему миру, и, вероятно, станет базовой технологией для новых поколений систем аналитики и хранения данных.