Современное промышленное производство сталкивается с множеством задач, требующих максимальной точности и надежности, особенно в таких критических процессах, как закручивание винтов. Мониторинг и выявление дефектов на ранних стадиях крайне важны для предотвращения серьезных производственных сбоев и финансовых потерь. Однако традиционные методы анализа временных рядов часто требуют большого количества аннотированных данных и значительных вычислительных ресурсов, что делает их применение в промышленности не всегда целесообразным. В такой ситуации всё большую популярность приобретает малообучаемое обучение (Few-Shot Learning, FSL) — подход, который позволяет моделям эффективно обучаться на небольшом количестве примеров. Особенное значение он приобретает в индустриальных временных рядах, где получение меток для новых типов дефектов сопряжено с большими затратами времени и ресурсов.
Рассмотрим применение малообучаемого обучения на примере мониторинга процесса закручивания винтов — одной из ключевых операций на производственных линиях. Процесс закручивания сопровождается генерацией многомерных временных рядов, например, данных о крутящем моменте, скорости и других параметрах инструмента. Эти данные позволяют выявлять отклонения в работе и потенциальные дефекты, но традиционные методы распознавания требуют наличия обширных обучающих выборок для каждого типа неисправности.Недавние исследования, проведенные группой учёных из Университета Фридриха-Александра в Эрлангене, Германия, продемонстрировали, что малообучаемое обучение способно значительно повысить качество мониторинга и классификации дефектов в таких условиях. В их работе использовался датасет, состоящий из 2300 примеров многомерных временных рядов с 16 различными типами дефектов, как однофакторных, так и мультифакторных.
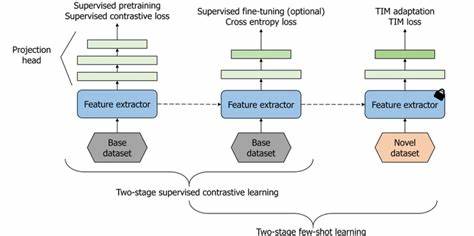
Основная цель заключалась в том, чтобы обучить модели эффективно различать эти типы при условии наличия всего нескольких примеров каждого класса.Для этого исследователи предложили инновационный подход — label-aware episodic sampler, который трансформирует многомарочные последовательности во множество задач с одним ярлыком, что позволяет сохранять информацию о сочетании меток при фиксированной размерности выхода модели. Это особенно важно для промышленных временных рядов, где возможна одновременная активность нескольких дефектов.В работе были исследованы две основные парадигмы малообучаемого обучения: метрическое обучение с применением прототипных сетей и градиентное метаобучение с использованием Model-Agnostic Meta-Learning (MAML). Каждая из них была протестирована с тремя различными архитектурами: одномерной сверточной нейронной сетью (1D CNN), InceptionTime — продвинутой структурой для временных рядов, и трансформером Moment с 341 миллионом параметров.
Результаты показывают, что сочетание InceptionTime с прототипными сетями на 10-шотной 3-классовой задаче достигает веса F1 высокого уровня — 0.944 в многоклассовом режиме и 0.935 в многомарочном. Это превосходит более крупную и ресурсоёмкую модель Moment, которая уступила до 5.3%, несмотря на наличие в ней значительно большего числа параметров и затраты времени на обучение, превышающие в 100 раз.
Такое превосходство относительно тяжеловесных моделей объясняется тем, что при ограниченном объёме данных лёгкие архитектуры в сочетании с метрическим обучением показывают лучшее обобщение и быстрее сходятся, что критично для промышленных условий с ограниченным временем и ресурсами. Более того, применение label-aware sampling улучшает результаты примерно на 1.7% по сравнению с обычным классическим выбором задач по ярлыкам, подчеркивая важность корректной организации тренировочного процесса.Выводы этого исследования имеют ключевое практическое значение для высокотехнологичных производственных предприятий: внедрение малообучаемых моделей позволяет не только существенно сократить затраты на сбор и маркировку данных, но и повысить надежность мониторинга процессов. Это, в свою очередь, способствует быстрому обнаружению дефектов и снижению количества брака, что благотворно влияет на себестоимость продукции и общую эксплуатационную эффективность.
Отдельного внимания заслуживает открытость разработчиков: они предоставили доступ к коду, разделению данных и предобученным весам, что не только ускорит развитие исследований в области промышленного малообучаемого обучения, но и облегчит его практическое применение на предприятиях разного уровня.Таким образом, малообучаемое обучение открывает новые перспективы для анализа многомерных временных рядов в промышленности, особенно когда речь идет о мониторинге сложных процессов с недостатком обучающих данных. Простые и эффективные алгоритмы, основанные на метрическом обучении и лёгких сверточных архитектурах, способны существенно улучшить качество диагностики и контроля технологических операций, таких как закручивание винтов. Внедрение таких методов на практике позволит повысить производительность, снизить выпуски бракованной продукции и оптимизировать техническое обслуживание.Современные тенденции показывают, что большие и сложные трансформеры не всегда являются оптимальным выбором для индустриальных задач с ограниченными метками.
Вместо этого стоит обращать внимание на сочетание проверенных архитектур сверточных сетей и инновационных методик малого обучения. Это особенно актуально для предприятий с ограниченными вычислительными ресурсами и жесткими требованиями к времени реакции систем мониторинга.В будущем дальнейшее развитие малообучаемых подходов для временных рядов будет стимулироваться усиливающейся интеграцией в производственные процессы Интернета вещей (IIoT), автоматизации и предиктивного технического обслуживания. Важной задачей станет расширение исследовательской базы, устранение ограничений современных моделей и адаптация их под новые производства и типы данных.Таким образом, малообучаемое обучение становится неотъемлемой частью цифровой трансформации промышленности, открывая возможности для более гибкого, экономичного и точного контроля качества и стабильности технологических процессов.
Инженеры и исследователи получают мощные инструменты для борьбы с дефицитом аннотированных данных и одновременно повышают надежность промышленного производства за счет интеллектуального анализа временных рядов.