В современных распределённых системах и облачных сервисах gRPC становится одной из ключевых технологий для эффективной межсервисной коммуникации благодаря своей производительности и надёжности. Однако при работе в средах с низкой сетевой задержкой, как правило, с быстро реагирующими кластерными базами данных, возникают неожиданные трудности с производительностью на стороне клиента. Особенно это заметно при увеличении нагрузки на систему и уменьшении количества серверных узлов. Несмотря на то что инфраструктура и сеть работают без нареканий, производительность клиентов не масштабируется и задержки растут, что вызывает вопросы и необходимость глубокого анализа реального поведения gRPC клиентов. Компания YDB, поддерживающая открытое распределённое SQL-хранилище с проверенной поддержкой ACID-транзакций и строгой согласованности, в процессе тестирования нагрузки на свои gRPC-сервисы пришла к парадоксальному выводу: при сокращении количества серверных узлов и уменьшении масштаба кластера клиентам gRPC становится сложнее обеспечить высокую производительность, при этом наблюдается значительный рост клиентских задержек и простаивание ресурсов.
Команда разработчиков провела детальный разбор ситуации с использованием собственного микробенчмарка, построенного на базовом gRPC ping-тесте, работающем на C++ и по сравнению с аналогами на Java. Эксперименты выполнялись на выделенном железе с современными Xeon-процессорами и высокоскоростным 50 Gbps сетевым соединением с задержкой 0.03-0.04 мс, что исключало проблемы с сетью и позволило сфокусироваться именно на поведении клиента. В ходе исследования выяснилось, что в gRPC клиенте существует неочевидное ограничение, связанное с реализацией самих каналов и их взаимодействием по протоколу HTTP/2 поверх единственного TCP-соединения.
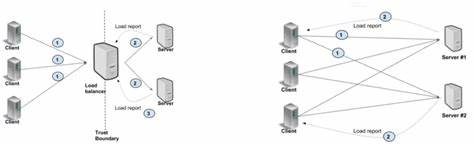
По умолчанию несколько gRPC каналов с одинаковой конфигурацией в клиенте фактически используют одно и то же TCP-соединение, которое поддерживает multiplexing нескольких потоков (RPC вызовов). При достижении лимита активных параллельных потоков (по умолчанию около 100), новые запросы начинают ставиться в очередь на стороне клиента, что создаёт буферизацию и увеличивает задержку. В результате для работающего в закрытом цикле клиента наблюдается существенная задержка между отправкой запросов из-за ожидания освобождения потоков на данном TCP соединении. Так как сеть является сверхнизколатентной и сервер отвечает быстро, эта задержка становится ключевым фактором снижения производительности. Дальнейший анализ трафика с помощью сниффера Wireshark подтверждает, что после обработки пакетов происходит пауза около 150-200 микросекунд на стороне клиента, что снижает общую производительность.
Разрешить эту проблему традиционно советуют двумя способами, которые у официальной документации gRPC почему-то рассматриваются как альтернативы. Во-первых, создавать отдельный канал для каждого интенсивно загруженного участка приложения, чтобы избежать потолка на число активных потоков на канале. Во-вторых, использовать пул каналов с различными аргументами конфигурации, что заставляет gRPC создавать отдельные TCP подключения. В ходе экспериментов доказано, что эти методы – не раздельные варианты, а последовательные шаги одного решения, позволяющего избавиться от ограничения одного TCP соединения. Настоящим прорывом стало приложение специального аргумента GRPC_ARG_USE_LOCAL_SUBCHANNEL_POOL, который заставляет клиента распределять RPC вызовы по отдельным подключениям и каналам, тем самым максимально распараллеливая сеть и внутриклиентскую обработку.
Когда команда сделала так, что каждый worker клиентского приложения имел собственный канал с уникальными параметрами, производительность резко возросла – около шестикратное увеличение throughput для простых RPC и почти пятикратное – для стриминговых вызовов. Показательно, что при усложнении нагрузки и росте числа параллельных in-flight запросов, рост задержек на клиенте стал значительно медленнее, почти выровнялся с низкоуровневым поведением сети. Можно говорить о том, что узкое место ждёт своего решения в виде более масштабируемой архитектуры каналов и оптимизации внутренних механизмов gRPC. Интересно было проверить, насколько эта проблема критична для сред с более высокой сетевой задержкой. В тестах с латентностью около 5 миллисекунд были получены вполне удовлетворительные результаты, при которых многоканальный подход давал лишь небольшое преимущество при высоких нагрузках.
Это объясняется тем, что в таких случаях сетевая задержка доминирует над внутренними клиентскими задержками, и узкие места смещаются на уровень инфраструктуры. Для разработчиков и инженеров, работающих с высокопроизводительными распределёнными системами, важным уроком стало то, что оптимизация клиента gRPC не ограничивается лишь внешними параметрами – необходимо тщательно конфигурировать и архитектурно проектировать взаимодействие каналов и потоков. Использование отдельных каналов с уникальными настройками для разных рабочих потоков или областей нагрузки даёт возможность достойно масштабировать и удерживать низкие задержки, что особенно важно для бизнес-критичных приложений и баз данных с жёсткими требованиями к времени отклика. Таким образом, эта история демонстрирует ключевой момент: прежде чем пытаться улучшать пропускную способность системы, нужно определить и устранить узкое место. В случае gRPC на сверхнизких задержках это место может быть неожиданно на стороне клиента и кроется в особенностях работы с HTTP/2 и TCP сокетами.
Кроме того, предоставленный компанией YDB открытый микробенчмарк и рекомендации по конфигурации каналов становятся ценным ресурсом для сообщества, способствуя пониманию и распространению лучших практик. Работа по оптимизации gRPC клиента не закончена. Авторы призывают сообщество делиться опытом, вносить предложения и расширять тестирование, что позволит выявлять и решать дополнительные узкие места, обеспечивая максимальную эффективность и масштабируемость современных распределённых решений. Ведь совершенствование таких фундаментальных технологий напрямую влияет на производительность миллионов сервисов и конечный пользовательский опыт во всём мире.

![Demis Hassabis Interview [video]](/images/E1EEA264-C580-4F3D-9CEB-D6A804FED40D)